





В данной работе проводится анализ текущего состояния научных исследований в области построения и разработки ДНК-компьютеров. Наиболее конструктивный подход в данный момент состоит в том, чтобы рассматривать будущие ДНК-компьютеры как дополнение современных компьютеров в некоторых важных аспектах, а не замену их.
Ключевые слова: ДНК компьютер, параллельные вычисления, фон-Неймановская архитектура.
Развитие информационных технологий и вычислительной техники с каждым годом набирает все новые обороты. Техника быстро устаревает, не успевая справляться с поставленными ей задачами, и на смену обычной фон-Неймановской архитектуре приходит все больше концепций построения вычислительных машин. Одной из них является попытка реализации высокопроизводительного процессора на базе ДНК. Идея его создания, наряду с построением квантового компьютера, будоражит мысли ученых всего мира уже далеко не один год, но пока создано крайне мало аналогов, удачно реализованных на практике. В связи с этим возникает вопрос: чем же идея компьютера на базе молекулярных вычислений превосходит суперкомпьютер, построенный на традиционной архитектуре, что можно пренебречь всеми трудностями его создания? Во-первых, у современных информационных устройств имеются пределы миниатюризации, и вполне очевидно, что новый решительный прорыв в этой области станет возможен только при переходе на молекулярный уровень. А во-вторых, ДНК-компьютер обладает рядом свойств, связанных в первую очередь с его биолого-химической сущностью, и не присущих ни одному из ныне существующих вычислительных устройств, что позволит ему развиваться в совершенно уникальной области.
Надежды на успешное развитие ДНК-компьютера основаны на двух фундаментальных феноменах, это массированный параллелизм цепочек ДНК и комплементарность Уотсона-Крика. Первое позволяет распараллелить задачу таким образом, что большое количество однотипных действий будет выполняться одновременно, а второе — это свойство, означающее, что у каждого основания цепочки ДНК есть только одно, комплементарное данному (А-Т, Г-Ц), что дает нам мощный механизм вычислений [1].
Еще в 1994 году Леонард Эдлман, профессор Калифорнийского университета, продемонстрировал, что с помощью пробирки с ДНК можно весьма эффективно решать классическую комбинаторную задачу о нахождении кратчайшего пути обхода всех вершин графа. Метод ДНК позволяет сразу сгенерировать все возможные варианты решений с помощью известных биохимических реакций. Затем возможно быстро отфильтровать именно ту молекулу-нить, в которой закодирован нужный ответ. Однако, при решении этой задачи возникает ряд трудностей, связанных в первую очередь с тем, что для вычисления требуется большое количество трудоемких химических реакций, проводимых под тщательным наблюдением. Также Эдлман проводил этот опыт на примере графа всего лишь с 7 вершинами, и при масштабировании задачи хотя бы до 200 вершин, масса необходимого ДНК материала превысит массу нашей планеты [2]. Электронный компьютер хоть и будет решать эту задачу значительно дольше, так как все операции в нем будут выполняться последовательно, однако точность выполнения повысится, а задействованность в процессе человека сведется к минимуму. Однако недостаток точности компенсируется избыточностью одинаковых цепочек в ДНК аппарате, что позволяет провести проверку. Массированный параллелизм используется для расшифровки криптосистем, требующих полный перебор всех вариантов [3]. Эти задачи могут быть решены с помощью небольших машин, которые не нуждаются в больших количествах ДНК. В настоящее время криптографические задачи кажутся наиболее подходящей областью приложения ДНК-вычислений, поскольку тут приемлем наиболее высокий уровень погрешности, чем тот, что обычно требуется от электронных компьютеров.
Команда ученых под руководством Олега Ганга (Oleg Gang) из Национальной Лаборатории Брукхэвена (Brookhaven National Laboratory) прикрепили к молекуле ДНК наночастицы золота.
В проведенном ими эксперименте была сформирована трехмерная наноструктура с кристаллической симметрией из золотых наночастиц. При этом молекулы ДНК играли роль лесов. На которых располагались строительные блоки-наночастицы.
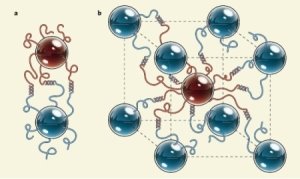
Рис. 1. Наночастицы собираются на ДНК-лесах
Наночастицы размером 10 нанометров присоединялись к цепям ДНК, и как только молекула встречала комплиментарный участок с такой же наночастицей на конце, формировалась пара строительных блоков. Была сформирована трехмерная сетка из наночастиц.![]() После формирования структуры ее нагрели для того, чтобы удалить фрагменты ДНК и получить завершенную золотую наноструктуру.
После формирования структуры ее нагрели для того, чтобы удалить фрагменты ДНК и получить завершенную золотую наноструктуру.
Не подлежит сомнению тот факт, что на протяжении уже примерно полувека воплощением парадигмы вычислений является машина Тьюринга [3]. Однако если рассуждать о долгосрочных перспективах молекулярных вычислений, то представляется вероятным, что одна единственная молекула ДНК может быть использована для кодирования мгновенного описания машины Тьюринга [4]. В конечном счете, можно вообразить появление компьютера общего назначения, состоящего из одной единственной макромолекулы. Но все-таки для этого необходимы обширные дополнительные исследования в области молекулярной биологии и химии. На самом деле вопрос о том, воплотятся ли ДНК-вычисления в реальность или останутся лишь сноской в книгах по истории компьютерных наук, еще далек от какого-либо окончательного решения.
Таким образом, возможно, наиболее конструктивный подход в данный момент состоит в том, чтобы рассматривать будущие ДНК-компьютеры как дополнение современных компьютеров в некоторых важных аспектах, а не замену их. Некоторые классы задач кажутся наиболее подходящими для ДНК-вычислений. Особенностями, характерными для таких задач, являются, во-первых, то, что наилучшим из известных методов их решения является полный перебор, а во-вторых, то, что достижение успеха с высокой вероятностью почти так же хорошо, как получение определенного ответа. Именно так ставятся типичные криптоаналитические задачи. Успехи робототехники могут открыть также новые перспективы для создания компьютеров, сочетающих как молекулярные, так и электронные компоненты.
Использование биокомпьютера уже сегодня возможно, целесообразно и необходимо: в науке, образовании, во всех системах управления, проектирования, в процессах созидания и творения.
Ну а сегодня какие задачи можно решать, используя биокомпьютер? Если ввести в биокомпьютер фамилию, имя и отчество человека, то можно получить информацию о его предназначении, способностях, дарах Божьих — феноменах, о которых он даже не подозревает, выявить успешность работы в данной фирме, совместимость с командой фирмы, и таких показателей может быть 50–80.
Затем можно получить полную информацию о состоянии здоровья каждого элемента его организма, отклонения не от средней нормы, а от нормы данного человека в процентах и узнать причину этих отклонений. Клиент может сделать заказ пользователю биокомпьютера по телефону, факсу из любой точки земного шара и таким же способом получить распечатанный ответ.
Если ввести в биокомпьютер только название фирмы и фамилию, имя, отчество директора, то можно получить данные о факторах, влияющих на экономику предприятия, данные о конкурентоспособности его продукции на любых рынках, объёмы реализации продукции в будущих периодах, эффективность инвестиций в новые направления, эффективность сотрудничества или слияния с другими фирмами, эффективные и целесообразные объемы рекламы и тому подобные данные.
В спорте, искусстве, шоу-бизнесе по фамилии, имени и отчеству можно получить полную информацию об успехе, возможностях, совместимости с коллективом приобретаемого кандидата в клуб или коллектив. Фактически уже открыто новое направление — геология интеллектуальных ресурсов стран, и это самое главное их богатство.
Для крупных объединений, корпораций только с помощью биокомпьютерных технологий можно разработать прогнозы их развития, выявить новые направления деятельности с учетом будущих реалий нашего мира.
Биокомпьютерные технологии привлекательны тем, что практически все задачи решаются оперативно. Обследование эффективности деятельности огромного судостроительного завода, включая экономику, парк оборудования, состояние производственных площадей, конкурентоспособность основных видов продукции, выявление производств, требующих расширения, реконструкции и технического перевооружения, было выполнено за три дня.
Анализ и прогноз деятельности крупного банка и 30 его филиалов был выполнен за десять дней. Очень важным обстоятельством при выполнении подобных работ является то, что биокомпьютерные технологии не требуют исходной статистической и тем более коммерчески закрытой информации.
Для решения научных проблем биокомпьютер заменит все технические средства научных проблемных лабораторий, оставив им решать незначительные прикладные задачи.
Биокомпьютерные технологии в бизнесе, науке, в высоких властных структурах позволяют совершить переворот в эффективности управления, освободить руководителей от состояния неуверенности, когда будущее в тумане, оно «кажется» и позволяет руководителям «ясно» видеть будущее, во многом отказаться от сбора рутинной статистики.
XXI век станет веком широкого использования человечеством в свое благо Премудрости, так как только с ее помощью возможно движение человечества к совершенству и становится реальным формирование нравственных обществ.
Литература:
1. Паун Г., Розенберг Г., Саломаа А. ДНК-компьютер. Новая парадигма вычислений. — М: Мир, 2004.
2. Adleman L. M. Molecular computation of solutions to combinatorial problems //Science. — 1994. — Т. 266. — №. 5187. — С. 1021–1024.
3. Adleman L. M. et al. On applying molecular computation to the data encryption standard //Journal of Computational Biology. — 1999. — Т. 6. — №. 1. — С. 53–63.
4. Turing A. M. On computable numbers, with an application to the Entscheidungsproblem //J. of Math. — 1936. — Т. 58. — №. 345–363. — С. 5.
