





В статье рассмотрена задача анализа тональности текста на примере отзывов о фильмах. Рассмотрена проблематика подхода, основанного на словарях, создан свой собственный словарь сентиментов и для него проведены исследования на корпусе данных.
Ключевые слова: словарь сентиментов, тональность
Анализ тональности текста — это сложный процесс, касающийся выделение полезной субъективной информации из текста. Огромное множество пользовательского контента в интернете появляется с каждым днем. Миллионы пользователей ежедневно высказывают свое мнение о продуктах и услугах в блогах, социальных сетях и других информационных ресурсах. Предоставление надежного извлечения мнения из неструктурированного текста имеет важное значение для коммерческих организаций. С помощью предоставленных данных компании смогут узнать важное для них мнение покупателей, найти невидимые для их глаза недостатки и повысить свой уровень продаж.
Анализ тональности применяется на множестве текстовых документов, содержащих в себе эмоции и оценки определенных объектов, к примеру людей, событий, тем (например, отзывы о фильмах, книгах, продуктах). Анализ тональности предполагает идентификацию сентимента в документе, и в последствии определения его положительной/отрицательной полярности.
Как правило, анализ тональности применяется на корпусах текстов, содержащих отзывы. Однако, анализ тональности может быть в том числе применен к новостным статьям [1] или блогам и социальным сетям. Сентимент анализ также применяют чтобы извлечь общественное мнение о различных темах в пределах от фондовых рынков [2] до политических споров [3].
Существуют два основных подхода к задаче автоматического извлечения тональности — подход, основанный на использовании словарей сентиментов и подход, основанный на машинном обучении. В данной статье будет рассматриваться подход, основанный на словарях.
Создание словарей сентиментов очень сложный процесс. Для того чтобы создать словарь сентиментов необходимо вручную обработать большое количество текста, чтобы понять, какая лексика используется в рассматриваемой области.
В качестве основы для создания словаря сентиментов были взяты 5000 ключевых слов из корпуса о фильмах, книгах и фотоаппаратах [4] без разделения по тональности. Каждое слово было вручную определено на положительную/отрицательную тональность. Те слова, которые невозможно было однозначно отнести к положительной или отрицательной тональности исключались. Таким образом, специально для мета-области фильмов было получено 1926 слов с разделением по тональности. Из них 1002 слова было с положительной тональностью и 924 слова с отрицательной тональностью.
Тестовая коллекция
Отбор данных для тестирования очень важен. Без тестовых данных невозможно четко и точно определить работоспособность полученной модели. Для тестирования полученного словаря был использован корпус отзывов о фильмах, предоставленный НП РОМИП [5] в виде xml-кода.
Коллекция была представлена в виде xml-кода, каждый отзыв содержит оценку и текст мнения. Корпус данных состоит из 15718 таких отрывков. После предварительной обработки данных было определено, что данный корпус состоит из 1502030 слов.
В качестве положительных отзывов было принято считать те тексты, которые имели оценку выше пяти баллов, а отрицательными те тексты, которые имели оценку ниже шести баллов.
Так как исходные данные для тестирования были представлены в виде необработанного текста, была проведена предварительная обработка для приведения документов к нормализованному виду.
В своей программе для первоначальной обработки текста использовалась библиотека Beautiful Soup.
В рассматриваемом случае задача состояла в том, чтобы выделить из корпуса данных информацию для двух массивов — массива оценок и массива непосредственных отзывов.
Так как полученные тексты представляли из себя набор из нескольких предложений, было принято решение избавится от лишних знаков и выделить отдельные слова — для этого текст разбивался на слова регулярным выражением «^ [\s\W]*| [^\w]|\s(?= [\W\s]|$)(?u)». Все полученные слова были переведены в нижний регистр.
Алгоритм для словарного подхода
В качестве определения тональности для словарного подхода, было принято использовать метод, описанный Peter D. Turney в 2002 году [6]. Идея заключалась в следующем: каждое слово текста рассматривалось на наличие в словаре, как слово, несущее положительную или отрицательную тональность. Если слово встречалось в словаре, как слово с положительным весом, то счетчик для слов, несущих положительную тональность увеличивался. Аналогично счетчик для слов несущих отрицательную тональность, увеличивался, если слово имеет отрицательный вес.
Тональность текста определялось большим количеством того или иного счетчика.
Методы оценки построенного алгоритма
Для того чтобы понять, насколько хорошо построенный алгоритм работает с данными, необходима численная метрика его качества.
Точность иполнота
Точность (precision) — это доля документов, которые действительно принадлежат классу относительно всех документов, который классификатор отнес к этому классу.
Полнота(recall) — это доля найденных системой документов, принадлежащих классу относительно всех документов рассматриваемого класса в тестовой выборке.
Данные значения можно рассчитать на основе таблицы контингентности
Таблица 1
Таблица контингентности
|
Категория i |
Экспертная оценка |
||
|
положительная |
отрицательная |
||
|
Оценка системы |
положительная |
TP |
FP |
|
отрицательная |
FN |
TN |
|
Где:
TP — истинно-положительное решение
FP — ложно-положительное решение
FN — ложно-отрицательное решение
TN — истинно-отрицательное решение
Тогда полнота и точность вычисляются следующим образом:
![]()
![]()
Высокая точность и полнота означают качественное построение модели.
F-мера
F-score (F-мера) это метрика, которая объединяет информацию о точности и полноте алгоритма. F-score представляет собой гармоническое среднее между точностью и полнотой. Данная метрика стремится к нулю, если полнота и точность стремятся к нулю
![]()
Результаты
Для точного определения работы подхода, основанного на словарях, было принято решение разделить исходный корпус данных на 30 выборок, состоящих из 500 отзывов, собранных случайным образом.
Используя метод, описанный Peter D. Turney для словаря сентиментов, полученного ручной обработкой по тональности из словаря ключевых слов, были получены следующие результаты:
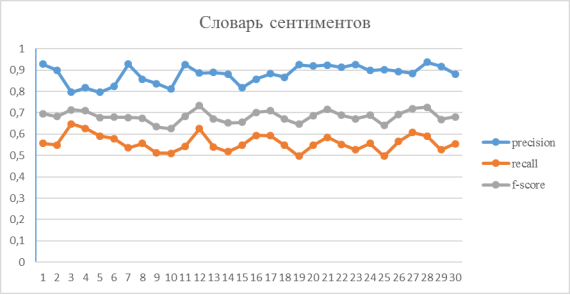
Рис. 1. Результаты словаря сентиментов
Таким образом, представив данные в виде диаграммы можно заметить высокую точность. Недостаточно высокую полноту можно объяснить малым словарным запасом словаря, который состоит из 2000 слов.
Рассмотрим, теперь отдельно оценки определения позитивных и негативных отзывов. Результаты получились следующими:
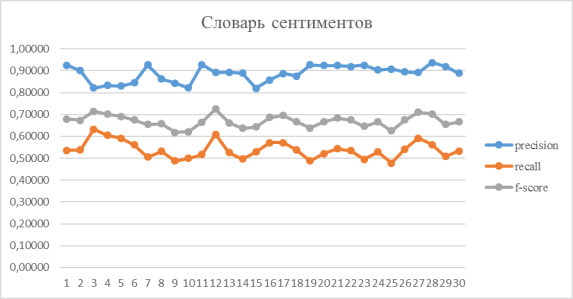
Рис. 2. Результаты оценки определения положительных отзывов для словаря сентиментов
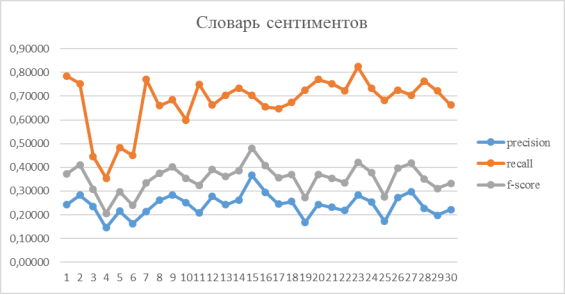
Рис. 3. Результаты оценки определения отрицательных отзывов для словаря сентиментов
Результаты оценки словаря сентиментов показали более высокую точность определения положительных отзывов, чем отрицательных, и более высокий общий результат.
Выводы
Целью данной статьи являлось исследование и разработка метода анализа тональности отзывов пользователей. Для исследования задач классификации был выбран подход, основанный на словаре, была рассмотрена проблема его построения и различные методы решения данной задачи. В итоге был получен собственный словарь сентиментов, который показал достаточно высокие результаты определения точности. Исследование показало, что определение отрицательных отзывов более трудная задача, чем определение положительных отзывов.
Литература:
1. T. Xu, Q. Peng, and Y. Cheng, Knowledge-Based Systems 35, 279 (2012).
2. M. Hagenau, M. Liebmann, and D. Neumann, Decision Support Systems 55, 685 (2013).
3. I. Maks and P. Vossen, Decision Support Systems 53, 680 (2012).
- Chetviorkin I. I., Loukachevitch N. V. Extraction of Russian Sentiment Lexicon for Product Meta-Domain // In Proceedings of COLING 2012: Technical Papers, pages 593–610 (2012).
5. http://romip.ru/
6. Turney, P. D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews //Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL'02), Philadelphia, Pennsylvania, 417–424 (2002).
