





В данной работе рассматривается применение методов машинного обучения с учителем к анализу тональности русскоязычных высказываний в социальной сети Twitter. Подробно разбираются методы предварительной обработки текста, описываются способы анализа тональности текста. Основываясь на теоретических исследованиях социальной сети Twitter, а также особенностях машинного обучения, приводятся оценки различных подходов к решению задачи. Для проведения исследовательской работы был написан комплекс программ на языке Python, который реализует рассмотренные подходы, и на реальных данных проводит численные эксперименты. Продемонстрированы результаты работы программ. Проведено сравнение результатов теоретических исследований и результатов, полученных в ходе эксперимента.
Ключевые слова:анализ тональности, классификация, datamining
За последнее десятилетие значительно возросло использование различных онлайн-ресурсов, в частности, социальных сетей, таких как Twitter. Многие компании и организации определяют эти ресурсы как значимые для маркетинговых исследований [1]. Обычно, чтобы получить обратную связь и понимание того, как покупатели относятся к их продукции, компании проводят интервью, анкетирования и опросы. Эти стандартные методы часто требуют больших затрат времени и денег; более того, они не всегда приносят желаемый результат.
Каждый день в Интернет загружается огромное количество данных, содержащих потребительское мнение. Такие данные являются, в основном, неструктурированным текстом, из которого компьютеру сложно извлечь мнение потребителя. В прошлом было невозможно обрабатывать такой большой объём неструктурированных данных, но сегодня это не составляет большого труда. Таким образом обработка естественного языка и анализ тональности играют важнейшую роль в принятии обоснованных решений о маркетинговых стратегиях и дают полезную обратную связь о продуктах и услугах.
Целью данной работы является проведение анализа тональности отзывов в социальной сети Twitter для определения репутации компаний. Данная цель включает в себя выполнение следующих задач:
- Исследовать методы машинного обучения для задачи анализа тональности;
- Провести анализ тональности для высказываний в Twitter;
- Оценить полученные результаты.
Обзор предметной области
Анализ тональности текста — это раздел интеллектуального анализа данных, направленный на выявление закономерностей в текстах, с целью классификации настроения в данных текстах
Существует несколько способов произвести анализ тональности текстов:
‒ по правилам;
‒ по словарям;
‒ машинное обучение с учителем;
‒ машинное обучение без учителя.
Основанный на правилах:
Цель данного подхода — поверхностный синтаксический анализ на основе какого-то правила. Такой подход показывает хорошую точность при большом количестве правил.
Пример такого подхода: если высказывание содержит прилагательные из набора ['хороший', 'добрый', 'новый'] и не содержит прилагательных из набора ['плохой', 'старый', 'ужасный'], то высказывание является положительным.
Основанный на словарях:
Данный подход подразумевает составление, либо использование готовых словарей тональности. Словарь представляет собой список слов с приписанной им тональностью. Каждому слову документа ставится в соответствие тональность из словаря, а затем подсчитывается общая тональность документа.
Основанный на машинном обучении с учителем [2]:
Данный способ представляет собой алгоритм с обучающими данными; эти данные состоят из обучающих примеров с предполагаемыми для них ответами. Алгоритм обучения с учителем использует эти данные, чтобы научиться сопоставлять подаваемые ему новые примеры с ожидаемыми ответами. В данной работе используется именно этот подход.
Основанный на машинном обучении без учителя:
Данный способ не требует обучающих данных, работа идёт с данными, где ответы не известны. Идея данного подхода в том, что чем чаще слова встречаются в одном тексте и чем реже в другом, тем большую значимость они играют для первого. Таким образом, для того, чтобы узнать тональность текста, нужно исходить из тональности таких слов.
Обзор данных
Коллекция обучающих и тестовых данный взята с международной конференции по компьютерной лингвистики и интеллектуальным технологиями «Диалог» [6]. Корпус состоит из 8643 обучающих твитов и 19773 — тестовых. Твиты содержат в себе информацию об операторах сотовой связи в России. Высказывания делятся на положительные, отрицательные и нейтральные (таблица 1).
Таблица 1
Данные
|
Положительные |
Отрицательные |
Нейтральные |
|
3326 |
3783 |
1534 |
Общий алгоритм анализа тональности
- Предварительная обработка данных;
- Построение вектора признаков;
- Применение метода машинного обучения с учителем;
- Оценка полученных результатов.
Предварительная обработка данных.
Подготовка данных является важной частью анализ тональности, поскольку анализировать можно любые данные, но для получения качественного анализа, данные должны быть очищены от загрязненных данных. Чтобы правильно подготовить данные, очень важно знать и понимать область исследования, поскольку исследователь должен уметь распознавать, какие данные важны, а какие можно исключить, поскольку они не несут весомой значимости. Предобработка данных включается в себя очистку и преобразование данных.
Очистка данных: удаление дубликатов, знаков пунктуации, цифр, лишних пробелов, ссылок, хэштегов и прочих символов.
Преобразование данных: удаление окончаний (стемминг) и приведение всех слов к нижнему регистру.
Построение вектора признаков:
В задачах обработки текста на естественном языке популярно представление документов в виде 𝑛-грамм, где 𝑛-граммы — последовательности слов длины 𝑛. В данной работе каждое высказывание определяется как вектор признаков (𝑛-грамм)
В качестве методов машинного обучения были выбраны Наивный Байесовский метод и метод опорных векторов (SVM) [4].
Наивный Байесовский метод:
Данный подход основан на присвоении высказыванию d класса ![]()
Согласно теореме Байеса [5] вероятность принадлежности высказывания d классу c выражается следующим образом:
![]()
Чтобы оценить вероятность ![]() , Наивный Байесовский метод раскладывает её на величины
, Наивный Байесовский метод раскладывает её на величины ![]() и таким образом получается Наивный Байесовский классификатор:
и таким образом получается Наивный Байесовский классификатор:
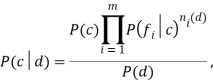
где ![]() количество признаков в обучающем корпусе данных,
количество признаков в обучающем корпусе данных, ![]() количество встретившихся признаков в документе d
количество встретившихся признаков в документе d
Метод опорных векторов: Суть метода опорных векторов заключается в том, что он отображает признаки в многомерном пространстве, а затем пытается разделить их гиперплоскостью. Если выборка линейно неразделима, то происходит переход от текущего пространства к пространству большей размерности, в котором выборка может быть линейно разделимой.
Оценка
В качестве оценки работы алгоритмов используется
![]()
![]() точность;
точность; ![]() полнота
полнота
‒ ![]() — истинно-положительные решения;
— истинно-положительные решения;
‒ ![]() — истинно-отрицательные решения;
— истинно-отрицательные решения;
‒ ![]() — ложно-отрицательные решения;
— ложно-отрицательные решения;
‒ ![]() — ложно-положительные решения.
— ложно-положительные решения.
Результаты
Анализ тональности высказываний в Twitter посредством методов машинного обучения был реализованы на языке программирования Python.
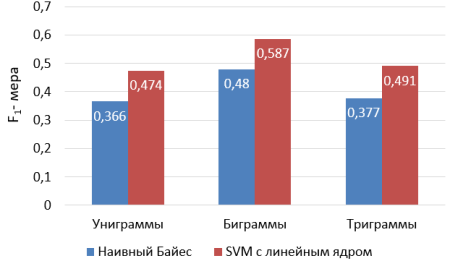
Рис. 1. Результаты работы Наивного Байесовского метода и SVM с линейным ядром
Как можно заметить из рис. 1, SVM с линейным ядром отработал лучше на всех n-граммах, причем наилучший результат был получен на биграммах.
На рис. 2 приведены результаты работы метода опорных векторов с линейным и полиномиальным ядрами. Можно видеть, что полиномиальному ядру не удалось обойти линейное.
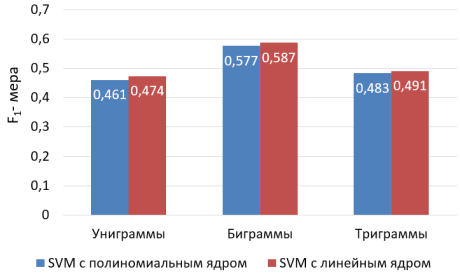
Рис. 2. Результаты работы SVM с линейным и полиномиальным ядрами
На рис. 3 видно, что лучший результат показал метод опорных векторов с линейным ядром. Лучший показатель у всех методов наблюдается на биграммах.
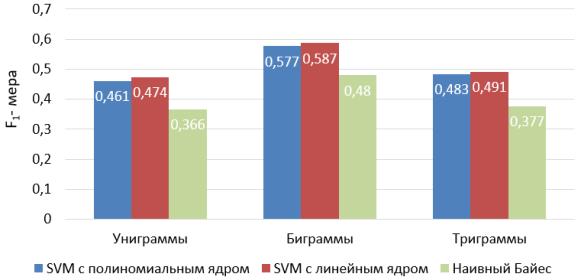
Рис. 3. Общие результаты работы методов
Выводы
Превосходство линейного ядра может быть обусловлено большой размерностью матрицы признаков и линейной разделимостью данных. Результаты с использованием биграмм могут быть объяснены спецификой русскоязычных высказываний в Twitter: ограниченностью в 140 символов, содержанием орфографических ошибок и сленга.
Результаты работы классификаторов можно попытаться улучшить путём выбора других признаков, удалением стоп-слов, комбинированием n-грамм, использованием лемматизации, а также, возможно, стоит оставить некоторые знаки препинания.
Литература:
- S. Owens, Your Guide to Twitter Marketing, March 2015.
- B. Pang, L. Lee, S. Vaithyanathan, Thumbs up? Sentiment classification using machine learning techniques, 2002, pp. 79–86.
- C. Cortes, V. Vapnik, Support-Vector Networks, 1995, pp. 273–297
- https://en.wikipedia.org/wiki/Naive_Bayes_classifier
- http://www.dialog-21.ru/
- https://en.wikipedia.org/wiki/Singular_value_decomposition
