





Организация совместной работыдвух подходов к статическому анализу кода: анализ указателей и интервальный анализ. Многократное выполнение отдельных алгоритмов анализа, с уточнением результатов на каждой итерации.
Ключевые слова: статический анализ, интервальный анализ, анализ указателей, поиск дефектов программного кода
Одной из важных составляющих качества программного обеспечения является надежность программной системы. Большинство нефункциональных программных ошибок вносится на стадии кодирования. Обнаружение таких дефектов является трудоемкой задачей и может занимать значительную часть от всего времени разработки, поэтому автоматизация ее решения является актуальной. Среди существующих подходов наиболее перспективными с точки зрения автоматизации представляются методы статического анализа. Статический анализ — группа методов, которые используют исходный код для определения требуемых свойств программы; применяются для обнаружения программных дефектов с 70-х гг. прошлого века.
Рассматриваемые в литературе стратегии зачастую предлагают решение узкой задачи — поиска одного или нескольких типов дефектов для определенного класса программ. При исследовании потока управления не четко интерпретируются выражения в условных операторах, также игнорируются межпроцедурные взаимодействия. Предлагаемые в настоящее время подходы свидетельствует о высокой сложности организации и ресурсоемкости выполнения полноценного статического анализа, обеспечивающего поддержку всего множества конструкций реального языка программирования для обнаружения широкого набора дефектов.
Процесс статического анализа
Статический анализ следует делить на четыре основных части: парсинг (распознание) кода программы и построение модели, интервальный анализ, анализ указателей и поиск ошибок. Вначале исходный код приводится к виду доступному для дальнейшей обработки. Далее цикл работы интервального анализа и анализа указателей. В финале результаты исследуются на присутствие ошибок.
Модели исходного кода
Наиболее удобной моделью в рамках данной задачи можно назвать модель представления на основе статического однократного присваивания исходного кода [5] программы, в которой:
– каждой локальной переменной значение присваивается только один раз;
– вводится версионирование для локальных переменных, которые в исходном коде имеют неоднократные присваивания;
– для локальных переменных вводятся ɸ-функции на выходе условных конструкций, объединяющие несколько ветвей программы и определяющие их окончательное значение;
– циклы заменяются инструкциями ветвления и безусловных переходов;
– сложные выражения заменяются цепочками выражений в трехоперандной форме.
Данное представление может быть записано ограниченным набором конструкций исходного языка (таких, как if и goto для языка С), или может быть изображено в форме графа потока управления.
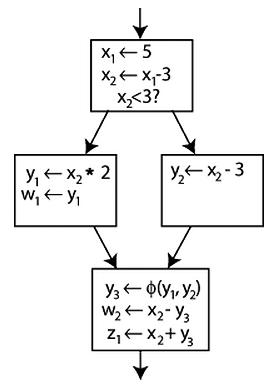
Рис. 1. Представление на основе статического однократного присваивания
Данное представление широко применяется при решении различных задач анализа кода: определение неиспользуемого кода, устранение избыточных конструкций, машинно-независимая оптимизация и т. д.
Одним из недостатков является отсутствие явной информации об областях видимости переменных, что затрудняет поиск используемых переменных в различных точках программы [5].
Базовые алгоритмы анализа
В качестве базовых алгоритмов анализа выбраны интервальный анализ и анализ указателей. В качестве математического аппарата предлагается использовать теорию решеток, поскольку известны эффективные алгоритмы поиска решения в рамках этой теории.
Решеткой называется частично упорядоченное множество L, для каждого подмножества X которого определена единственная точная верхняя грань sup(X) и единственная точная нижняя грань inf(X) [2]. Пусть L — некоторая конечная решетка, а f(x) —монотонная функция на L:
![]()
![]()
Наименьшей неподвижной точкой функции f(x) называется минимальный элемент ![]() решетки L, для которого справедливо
решетки L, для которого справедливо
![]()
Любая монотонная функция имеет единственную наименьшую неподвижную точку [2].
Интервальный анализ
При проведении интервального анализа формируется система уравнений. Для каждой строки представления кода составляется уравнение по определенным правилам. Неизвестными в уравнениях являются состояния программы Sl в соответствующих строках, где l номер вершины.
Элементами L являются подмножества множества всех возможных кортежей 〈a, i〉, где a — объект программы, i — интервал принимаемых им значений. Отношением порядка на решетке L является отношение включения подмножеств:
![]()
![]()
![]()
![]()
Интервал i обладает следующими атрибутами: ilow — нижняя граница интервала; ihigh — верхняя граница интервала. Кроме обычных интервалов вводится неинициализированное значения inoninit.
Ta является типом переменой a. Tahigh и Talow максимальное и минимальное значение типа Т.
Рассмотрим несколько правил построения уравнений для вершин, содержащих конструкции программы [1].
Начальное множество решений S равно нулю. Каждая обработанная строчка расширяет его.
При объявлении новой переменной к предыдущему состоянию программы добавляем кортеж, состоящий из объявляемой переменной a и интервала inoninit:
![]()
![]()
где ![]() — множество кортежей всех предшествующих состояний для вершины l.
— множество кортежей всех предшествующих состояний для вершины l.
При выходе переменной из области видимости удаляются все кортежи для данной переменной:
![]()
![]()
Для оператора присваивания, в правой части которого стоит константа, правило выглядит следующим образом:
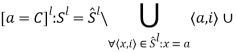
В этом уравнении из предыдущего состояния программы удаляются все старые кортежи, содержащие объект программы a, и добавляется новый кортеж a.
Правило для оператора присваивания a = b состоит в удалении всех кортежей для объекта a и добавлении для него всех кортежей, которые имеются для объекта b:
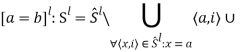
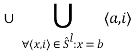
Анализ указателей
В анализируемом коде алгоритм работает с отношением «указывает-на». Каждый компонент представлен набором (o, i), где o объект, i сдвиг внутри этого объекта. Связь «указывает-на» определяет два элемента программы в виде кортежа ((oj1, k1), (oj2, k2)), где (oj1, k1) указывает на (oj2, k2).
С помощью такого представления можно передать работу с памятью на языке С: возможность косвенной и прямой адресации [3], определение сложных типов и структур.
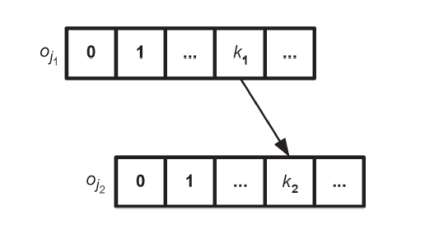
Рис. 2 Модель отношения «указывает-на»
Каждый объект представлен тремя атрибутами: тип, размер и владелец. Возможные типы:
– динамический (T dynamic) — приписывается блоку имен, через который происходит работа с памятью, выделенной одной из процедур захвата памяти malloc(), calloc(), realloc();
– статический (T static) к таким объектам относятся глобальные и локальные переменные;
Владелец объекта o — ownerof(o) — связывает статические объекты между собой.
Сдвиг внутри объекта i определяет элемент сложного типа, на который указывает переменная-указатель, что дает возможность работать с массивами и структурами. В случае, если переменная-указатель указывает на первый элемент массива, смещение равно нулю.
Для построения уравнений используются правила уникальные для каждой конструкции. Неизвестными в этих уравнениях являются множества кортежей для конструкций программы.
Для большинства интерпретируемых операторов и функций уравнения имеют вид:
![]()
Решение системы уравнений начинается с пустого множества и расширяется каждой новой обработанной строчкой. Система уравнений решается с использованием известных алгоритмов теории решеток.
Сформулируем правила для некоторых интерпретируемых конструкций программы.
Объявление в программе переменной-указателя приводит к добавлению в текущее состояние программы кортежа для нового объекта-указателя и объекта oinvalid, при этом удаление кортежей из предыдущего состояния не производится:
![]()
Объявление статического массива приводит к добавлению в текущее состояние программы кортежа, для которого создаются два новых объекта, объект длины 1, который хранит адрес массива, и объект для элементов массива:
![]()
![]()
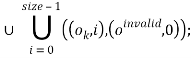
![]()
![]()
![]()
Правило (2.1) выполняется, если массив p объявлен как массив указателей, правило (2.2) — в остальных случаях.
Выход локальной переменной из области видимости приводит к удалению всех кортежей с этой переменной из текущего состояния программы. Для всех указателей, указывающих на статический объект, которым владела эта переменная, добавляется кортеж с объектом oinvalid:
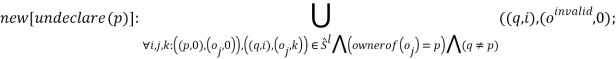
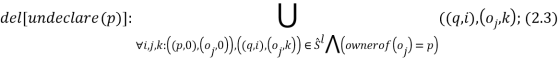
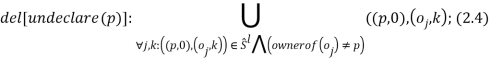
Правило (2.3) действует для объекта, владельцем которого является p, правило (2.4) — для всех остальных объектов.
Обнаружение дефектов
После решения систем уравнений, составленных интервальным анализом и анализом указателей, следует просмотр решений и поиск дефектов. Далее приведены некоторые правила для поиска некоторых дефектов.
Ошибка использования неинициализированной переменной в арифметических или логических операциях обнаруживается следующим правилом:
![]()
где ⊗ — некоторая арифметическая или логическая операция.
Дефект утечки динамической памяти возникает в конструкциях присваивания нового значения указателю p и в конструкции undeclare(p) в том случае, если указатель p в предыдущем состоянии программы указывал на динамический объект и на данный объект не указывали другие указатели. Это описывается следующим правилом:
![]()
![]()
Ошибка обращения к массиву по неправильному индексу возникает при значении индекса, выходящем за границы массива. Данный дефект обнаруживается следующим правилом:
![]()
![]()
где кортеж (p,(a,k)) связывает указатель p с k-м элементом объекта a и определяется в результате анализа указателей.
Правило обнаружения ошибок разыменования указателя, выведенного за границу массива, эквивалентно предыдущему случаю при индексе m, равном нулю:
![]()
Одной из ошибок адресной арифметики является выполнение операции вычитания или сравнения указателей на разные объекты:
![]()
где ![]() операция адресной арифметики.
операция адресной арифметики.
Дефект разыменования неинициализированного, неконтролируемого или нулевого указателя возникает в конструкции ∗p в том случае, если указатель мог указывать на некорректный объект oinvalid. Данная ситуация обнаруживается следующим способом:
![]()
Особенность метода заключается в том, что всегда можно расширять систему правил поиска ошибок, с целью нахождения новых дефектов.
Заключение
Предложен алгоритм, основанный на взаимодействии двух методов: интервального анализа и анализа указателей. К достоинствам представленных методов относится интерпретация условий в операторах ветвления, возможность комплексного анализа всех функций программы с учетов входных и выходных данных, а также просмотр сложных структур и массивов.
Недостатком алгоритма является потеря точности из-за объединения решений, полученных по отдельным путям. Можно предложить несколько способов преодоления указанного недостатка, в том числе извлечение и анализ зависимостей между объектами программы, проведение точного анализа путей для некоторых фрагментов программы [1].
Предложенный подход к организации комплексного анализа применим для различных языков программирования. На текущий момент, является основой для разрабатываемой системы автоматического обнаружения дефектов в программах на языках С/C++.
Литература:
- Ицыксон В. М., Моисеев М. Ю., Цесько В. А., Захаров А. В., Ахин М. Х. Алгоритм интервального анализа для обнаружения дефектов в исходном коде программ // Информационные и управляющие системы. — 2009. — № 2. — С. 34–41.
- Ицыксон В. М., Моисеев М. Ю., Цесько В. А., Карпенко А. В. Исследование систем автоматизации обнаружения дефектов в исходном коде программ // Научно-технические ведомости СПбГПУ. — 2008. — № 5. — С. 119–127.
- Andersen L. Program Analysis and Specialization for the C Programming Language. — Copenhagen: University of Copenhagen, 1994. — 311 с.
- Nielson F., Nielson H., Hankin C. Principles of Program Analysis. — Copenhagen: Springer, 2005. — 452 с.
- Schwartzbach M. Lecture Notes on Static Analysis // Karlsruhe Institute of Technology. URL: https://pp.ipd.kit.edu/lehre/SS2009/compiler2/schwarzbach-static-analysis.pdf (дата обращения: 11.11.2016).
