





Одним из этапов запуска космических аппаратов (КА) является обработка и последующий анализ телеметрической информации (ТМИ). При этом стоит вопрос о формировании из полученной приемными станциями (ПС) телеметрической информации т.н. единого носителя. ТМИ, зарегистрированная на ПС, записывается в виде файлов на носитель информации. Единый носитель – файл, сформированный из нескольких файлов, зарегистрированных на одной или нескольких ПС. Фрагменты ТМИ, включаемые в единый носитель, выбираются по критерию максимальной возможной достоверности. Полное отсутствие ТМИ на каком-либо участке полёта считается случаем максимальной недостоверности. Единый носитель обеспечивает максимально качественный анализ ТМИ, а также значительную экономию времени при обработке и анализе ТМИ.
В современной космической отрасли данный вопрос часто или игнорируется, или производится сборка единого носителя с помощью неавтоматизированных программных средств (вручную). Существуют также некоторые автоматизированные программные средства, позволяющие производить сборку единого носителя. Но они не обеспечивают универсальности использования – они рассчитаны или на определённое изделие или на использование с определенным типом приемной аппаратуры.
В данной статье описан принцип (алгоритм) работы программы автоматизированной сборки ТМИ (далее – программы) для бортовых радиотелеметрических станций (БРТС), содержащих некоторое необходимое количество служебной информации. Данная программа полностью независима от типа приёмной аппаратуры, работает с ТМИ, сформированной определённой БРТС и имеет возможность расширения функциональности под другие БРТС.
Независимость от типа приёмной аппаратуры обеспечивается способом реализации данной программы. Программа работает с определённой структурой ТМИ. Файлы из другой структуры приводятся в данную с помощью существующего конвертера.
ТМИ, формируемая с помощью данного типа БРТС, имеет следующие особенности:
· Существует несколько типов кадров: содержащие ТМИ, содержащие информацию от бортовой цифровой вычислительной машины (БЦВМ), служебные, пустые (не содержат ТМИ) и пр.
· Служебные пакеты содержат бортовое время.
· БРТС работает в режиме непосредственной передачи (НП) ТМИ, или воспроизведения (ВП) ТМИ, записанной на запоминающее устройство.
· Информация в БРТС поступает от разных источников.
И следующие структурные элементы:
· Непосредственно кадр ТМИ, состоящий из слов ТМИ.
· Слово ТМИ, состоящее из определенного количества бит и имеющее бит дополнения до четности.
· Аналогичные слова ТМИ, содержащие служебную информацию (перечислены далее).
· Номер источника и код режима, к которому принадлежит данный кадр.
· Порядковый номер кадра (по определенному модулю, в данном случае 256).
· Номер пакета (аналогичен номеру кадра, но счёт производится в пределе данного источника).
· Слово с контрольной суммой для служебной информации.
· Прочая служебная информация, не имеющая существенного значения для реализации данной программы.
В случае отличия от данной структуры в алгоритм программы необходимо внести некоторые изменения для соответствия другой структуре.
Приемная станция дополнительно записывает станционное время, которое не входит в кадр ТМИ. Станционное время различается на разных ПС и на разных типах приемной аппаратуры, имеет большое количество сбоев. Использовать станционное время для сборки единого носителя недопустимо.
Алгоритм работы программы предусматривает несколько этапов. Операции, производимые на первом этапе, выполняются для каждого файла отдельно. Операции, производимые на остальных этапах, выполняются для всех файлов попарно. При этом для первого файла парой будет второй файл. Для третьего файла в качестве пары используется результат операций с первым и вторым файлом, и т.д.
На первом этапе исправляются различные сбои, внесённые в ТМИ в результате некорректной работы наземной приемной аппаратуры. Записанная наземной аппаратурой ТМИ, описывается формулой:
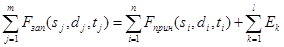 , (1)
, (1)
где 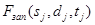 – записанный кадр ТМИ,
– записанный кадр ТМИ, 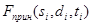 – кадр ТМИ на входе,
– кадр ТМИ на входе, 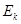 – сбои, внесенные наземной приемной аппаратурой,
– сбои, внесенные наземной приемной аппаратурой, 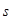 – служебная информация,
– служебная информация, 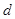 – данные,
– данные, 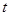 – время,
– время, 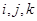 – номера кадров ТМИ.
– номера кадров ТМИ. 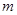 – общее количество кадров,
– общее количество кадров, 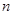 – количество принятых кадров,
– количество принятых кадров, 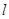 – количество внесенных сбоев. При этом известна, необходимо определить
– количество внесенных сбоев. При этом известна, необходимо определить 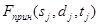 .
.
Одним из примеров данного типа ошибок являются кадры ТМИ, не содержащие никакой информации. Такие кадры необходимо удалить. Сложность [1] первого этапа определяется по формуле:
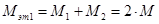 , (2)
, (2)
где 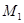 – количество итераций в первом файле,
– количество итераций в первом файле, 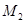 – количество итераций во втором файле (при этом
– количество итераций во втором файле (при этом 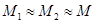 ). Далее, при определении сложности этапов, обозначения будут аналогичны данным.
). Далее, при определении сложности этапов, обозначения будут аналогичны данным.
После первого этапа телеметрическая информация описывается формулой (3) для первого файла и формулой (4) для второго файла:
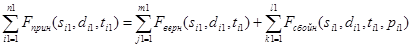 , (3)
, (3)
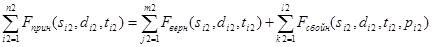 , (4)
, (4)
где 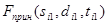 и
и 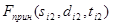 – ТМИ, полученная в результате выполнения первого этапа. Индекс «1» и «2» определяет номер файла из пары файлов (далее, если не указано другое, индексы «1» и «2» будут определять номер файла из пары).
– ТМИ, полученная в результате выполнения первого этапа. Индекс «1» и «2» определяет номер файла из пары файлов (далее, если не указано другое, индексы «1» и «2» будут определять номер файла из пары). 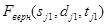 и
и 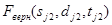 – кадры ТМИ, не содержащие сбоев.
– кадры ТМИ, не содержащие сбоев. 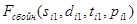 и
и 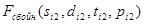 – кадры тми, содержащие сбои. Обозначения , , ,
– кадры тми, содержащие сбои. Обозначения , , , 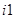 ,
, 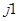 ,
, 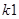 ,
, 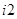 ,
, 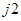 ,
, 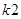 соответствуют обозначениям, принятым в формуле (1), индекс определяет номер файла.
соответствуют обозначениям, принятым в формуле (1), индекс определяет номер файла. 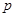 – помеха,
– помеха, 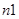 ,
, 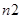 – количество принятых кадров (количество кадров после первого этапа),
– количество принятых кадров (количество кадров после первого этапа), 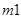 ,
, 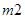 – количество кадров без сбоев,
– количество кадров без сбоев, 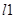 ,
, 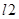 – количество кадров со сбоями.
– количество кадров со сбоями.
На втором этапе, блок-схема алгоритма которого представлена на Рис. 1, производится поиск кадров ТМИ (в каждом файле), содержащих полностью достоверную информацию (необходимо определить и на основе анализа служебной информации 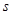 ). Эти кадры ТМИ сравниваются с полностью достоверными кадрами из других файлов ТМИ (необходимо найти такие и , для которых
). Эти кадры ТМИ сравниваются с полностью достоверными кадрами из других файлов ТМИ (необходимо найти такие и , для которых 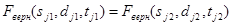 ). Если эти кадры идентичны, то их позиции запоминаются. Назовем данные позиции точками синхронизации. Вероятность нахождения точки синхронизации в общем случае определяется по формуле:
). Если эти кадры идентичны, то их позиции запоминаются. Назовем данные позиции точками синхронизации. Вероятность нахождения точки синхронизации в общем случае определяется по формуле:
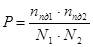 , (5)
, (5)
где 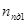 – количество полностью достоверных кадров в первом файле,
– количество полностью достоверных кадров в первом файле, 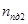 – количество полностью достоверных кадров во втором файле,
– количество полностью достоверных кадров во втором файле, 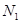 – количество кадров в первом файле,
– количество кадров в первом файле, 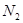 – количество кадров во втором файле.
– количество кадров во втором файле.
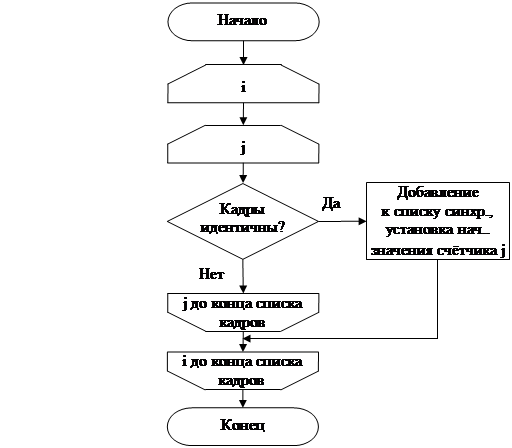
Рис.1 Блок-схема алгоритма второго этапа
Следует учесть, что по формуле (5) определяется вероятность нахождения точек синхронизации для файлов, в которых потери информации вызваны случайными помехами. Часто имеют место потери информации, вызванные уходом изделия из зоны видимости ПС, сильными помехами на определенном временном интервале. При этом вероятность нахождения полностью достоверного кадра подчиняется нормальному закону распределения [2] и определяется по формуле:
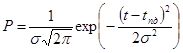 , (6)
, (6)
где 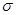 – коэффициент масштаба (
– коэффициент масштаба (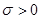 ), – время,
), – время, 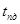 – центр временного интервала с полностью достоверной информации.
– центр временного интервала с полностью достоверной информации.
Сложность второго этапа определяется по формуле:
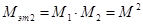 . (7)
. (7)
На третьем этапе операции выполняются над парами фрагментов, содержащимися между точками синхронизации. ТМИ на данном этапе описывается формулами (3) и (4).
Если на втором этапе точки синхронизации не были найдены, то третий этап (блок-схема его алгоритма показана на Рис.2.) выполняется для файла целиком. На данном этапе производится поиск кадров с одинаковым бортовым временем. У найденных кадров должны совпадать номер источника и режим (нп/вп). Кроме того, слова в кадре, содержащие данную информацию, не должны содержать сбоя по четности, а на сам кадр накладывается ограничение количества сбоев по четности в кадре (задается пользователем). Качество сбойного кадра ТМИ (для любого файла из пары) описывается формулой:
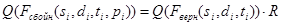 , (8)
, (8)
где 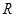 – коэффициент достоверности ТМИ,
– коэффициент достоверности ТМИ, 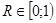 .
. 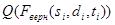 – качество кадра без сбоев (равно единице). Коэффициент достоверности определяется количеством слов без сбоев по четности в кадре. В связи с накладываемым ограничением на сбои по четности коэффициентом достоверности больше допустимого минимального значения:
– качество кадра без сбоев (равно единице). Коэффициент достоверности определяется количеством слов без сбоев по четности в кадре. В связи с накладываемым ограничением на сбои по четности коэффициентом достоверности больше допустимого минимального значения: 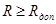 .
.
Кадры, соответствующие данным условиям, добавляются к списку точек синхронизации. Этот этап позволяет значительно сократить размеры интервалов между точками синхронизации в ТМИ, содержащей сбои. Вероятность нахождения точки синхронизации на данном этапе определяется по формуле:
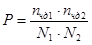 , (9)
, (9)
где 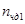 – количество кадров, удовлетворяющих ограничению, наложенному на количество сбоев по четности, в первом файле,
– количество кадров, удовлетворяющих ограничению, наложенному на количество сбоев по четности, в первом файле, 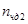 – количество полностью, удовлетворяющих ограничению, наложенному на количество сбоев по четности, во втором файле, – количество кадров в первом файле, – количество кадров во втором файле.
– количество полностью, удовлетворяющих ограничению, наложенному на количество сбоев по четности, во втором файле, – количество кадров в первом файле, – количество кадров во втором файле.
Сложность третьего этапа определяется по формуле:
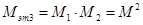 . (10)
. (10)
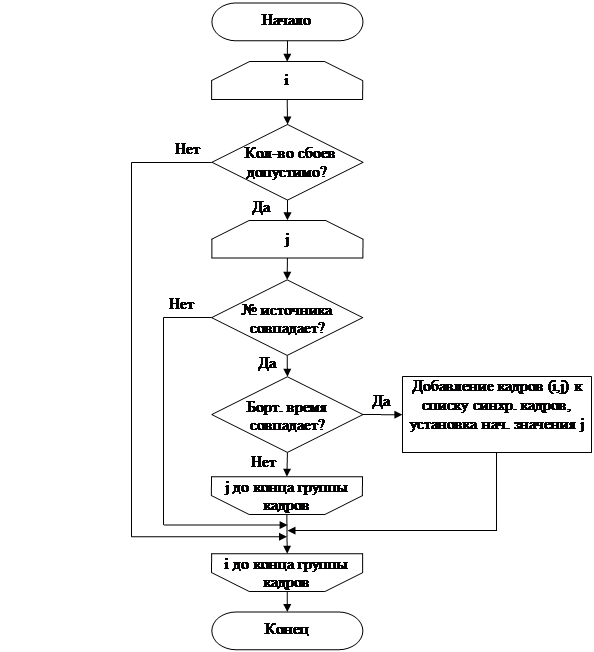
Рис.2 Блок-схема алгоритма третьего этапа.
Четвертый этап выполняется над парами фрагментов между точками синхронизации, полученными на предыдущих этапах или над файлами целиком (если такие фрагменты не существуют). Блок-схема алгоритма четвертого этапа показана на Рис.3.
На данном этапе производится анализ качества ТМИ с целью приблизительного определения положения точек синхронизации. Составляются карты фрагментов ТМИ, содержащих количество сбоев по четности не превышающее заданной величины. Накладывается ограничение на минимальный размер фрагмента. Производится анализ бортового времени, номера источника и режима во фрагментах, принадлежащих к паре карт. На основе данного анализа определяется порядок следования фрагментов. Точки синхронизации расставляются так, чтобы данная последовательность соблюдалась. Точно определять положение точек синхронизации не требуется, поскольку они будут находиться на фрагментах с крайне низким качеством ТМИ (шум), и не имеет значения, из какого файла будет включен в единый носитель фрагмент, состоящий из шума. Кроме того, отсутствует возможность точно определить данные точки синхронизации, не прибегая к дополнительным способам анализа. Точное определение приведет к увеличению времени работы программы без увеличения качества ТМИ на выходе. Данный этап позволяет определить точки синхронизации на фрагментах ТМИ, для которых предыдущие два этапа не дали результатов или результаты недостаточно хороши. Наглядным примером является фрагмент ТМИ, во время передачи которого происходило вращение изделия, при этом передача осуществлялась с двух антенн, расположенных напротив друг друга. Наземная аппаратура записывает ТМИ в два файла: один с одной антенны, второй с другой. В результате в файлах может не быть кадров, для которых сработает второй или третий этап.

Рис.3 Блок-схема алгоритма четвертого этапа.
Сложность четвертого этапа определяется по формуле:
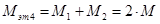 . (11)
. (11)
На пятом этапе (блок-схема алгоритма данного этапа представлена на Рис.4.) производится сравнение кадров или фрагментов, находящихся между точками синхронизации, а так же самих точек синхронизации. В качестве критерия используется количество сбоев по четности: выбираются те фрагменты (или кадры), которые имеют меньшее число сбоев по четности. Отдельные кадры допускается сравнивать пословно, что позволяет из парных сбойных кадров получить кадр без сбоев или с количеством сбоем меньшим, чем в менее сбойном кадре из пары. Фрагменты одинакового небольшого размера допускается сравнивать покадрово.
Сложность пятого этапа определяется по формуле:
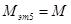 . (12)
. (12)
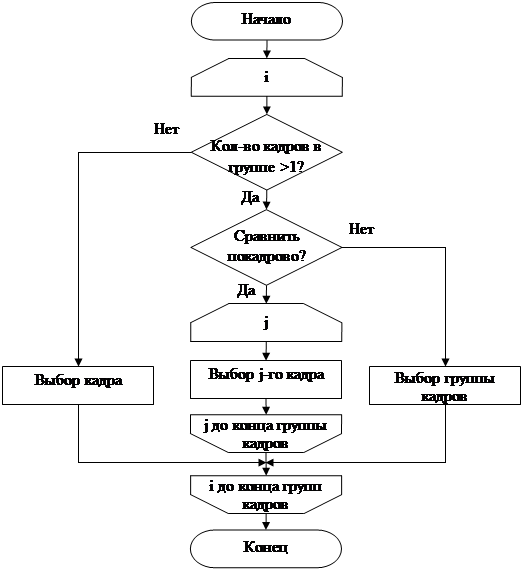
Рис.4 Блок-схема алгоритма пятого этапа
В результате работы программы получается файл с телеметрической информацией, максимально приближенной к той, которая передается с изделия.
Сложность программы определяется по формуле
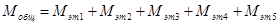 . (13)
. (13)
и составляет. Подставив определенные выше сложности отдельных этапов, получим 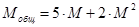 .
.
При этом порядок сложности [1] определяется по формуле:
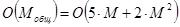 . (14)
. (14)
и составляет 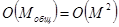 . Для данной задачи такая сложность алгоритма является приемлемой.
. Для данной задачи такая сложность алгоритма является приемлемой.
В случае использования данной программы для БРТС, ТМИ которой не содержит необходимого количества служебной информации, нужно внести изменения в алгоритм и произвести доработку программы в соответствии с измененным алгоритмом. Один из вариантов данных изменений – внедрение корреляционного анализа. При этом в файле ТМИ необходимо определить участки потери информации, а фрагменты, содержащиеся между данными участками сопоставить с помощью корреляции.
Литература:
1. Delphi. Готовые алгоритмы / Род Стивене; Пер. с англ. Мерещука П. А. - 2-е изд., стер. - М.: ДМК Пресс ; СПб.: Питер, 2004. - 384 С.: ил.
2. http://mathworld.wolfram.com/NormalDistribution.html
