





В настоящее время представлено большое разнообразие методов синтеза речи. Существуют два основных фактора, от которых зависит выбор технологии синтезирования в конкретной реализации:
- Задача. В зависимости от требований к качеству итогового продукта, варьируются возможности синтезированной речи. Самую простую синтезированную речь можно создавать путём объединения частей записанной речи, которые будут храниться в базе данных. Естественно, в случае, если необходим синтез сложного текста, такой метод использовать нельзя, так как на стыке составляемых звуковых фрагментов возможны интонационные искажения и разрывы, заметные на слух. Кроме того, потребуется очень большая база данных для хранения всех необходимых звуковых фрагментов.
- Структура языка. При построении выходной речевой волны используются основные фонологические законы, правила ударения, морфологические и синтаксические структуры.
- Технологические возможности. В первую очередь, это количество памяти, доступное для информационной системы. В зависимости от количества хранимого словаря синтезатора, меняется и его сложность, и качество результирующего сигнала. Не менее важную роль при выборе метода играет вычислительная мощность устройства. Выбор сложного метода синтеза речи вкупе с низкой производительностью аппаратного обеспечения приведет к огромным затратам времени на вычисления.
Синтезаторы речи в целом делят на два типа: с ограниченным и неограниченным словарем. В устройствах с ограниченным словарем речь хранится в виде слов и предложений, которые выводятся в определенной последовательности при синтезе речевого сообщения.
Основные методы с ограниченным словарем — модель компилятивного синтеза и параметрическое представление. [1]
Модель компилятивного синтеза.
Модель компилятивного синтеза предполагает синтез речи путем конкатенации записанных образцов отдельных звуков, произнесенных диктором.
При использовании этой модели составляется база данных звуковых фрагментов, из которых в дальнейшем будет синтезироваться речь. Размер элементов синтеза, как правило, не меньше слова.
Этот способ обеспечивает высокое качество синтезируемой речи, т. к. позволяет воспроизводить форму естественного речевого сигнала. Еще один немаловажный плюс такого подхода: не требуется никаких знаний об устройстве речевого тракта и структуре языка. Однако, серьезное ограничение в данном случае имеет объем памяти. [2]
Таким образом, этот метод весьма прост в реализации и при этом эффективен в системах, не требующих синтеза заранее неизвестных предложений.
Существуют способы кодирования речевого сигнала в цифровой форме, позволяющие в несколько раз уплотнить информацию: простая модуляция данных, импульсно-кодовая модуляция, адаптивная дельтовая модуляция, адаптивное предиктивное кодирование. Естественно, сложность операций кодирования и декодирования увеличивается со снижением числа бит в секунду. В случае, когда требуется соединить сообщения в более длинное, сгенерировать высококачественную речь трудно, так как значения параметров речевой волны нельзя изменить, а они могут не подойти в новом контексте. [3]
Параметрическое представление.
С целью решения двух основных проблем компилятивного синтеза было разработано параметрическое представление сигнала, которое абстрагируется от речевой волны, а представляет ее в виде определенных параметров. Такой подход уменьшает объем требуемой памяти для словаря и дает большую гибкость по сравнению с компилятивной моделью.
Параметры отражают наиболее характерную информацию либо во временной, либо в частотной области. Один из подходов параметризации — представление речевой волны с помощью сложения отдельных гармоник на данной частоте.
Другой вариант параметрического представления речевого тракта — формантный — генерирует речь искусственным путем, создавая нужный набор резонансов. Такая система оперирует параметрами основного тона и формантами.
Таблица 1
Формантные частоты гласных
|
Символ |
F1 |
F2 |
F3 |
|
и |
390 |
1990 |
2550 |
|
у |
440 |
1020 |
2240 |
|
а |
730 |
1090 |
2440 |
|
э |
660 |
1720 |
2410 |
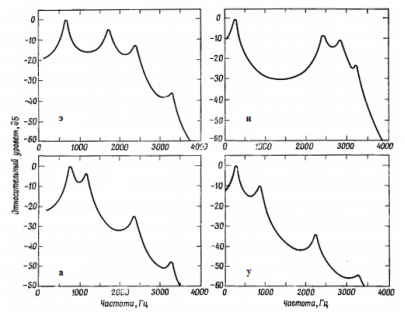
Рис. 2. Спектры гласных
Изменения таких параметров дают возможность существенно изменять интонацию и временные характеристики сообщения.
Представление речи формантами является экономичным способом хранения речевой информации, еще больше уменьшая объем необходимой памяти по сравнению с компилятивным подходом.
Второе преимущество такого подхода является присущая ему гибкость. Поскольку смысловая информация содержится в формантах, а мелодическая (интонация, темп речи и т. д.) — в периоде основного тона и временном распределении речи, то формантное представление позволяет разделить что именно сказано и как сказано. [3]
Итак, формантный подход требует меньшего объема памяти, чем компилятивный, но при этом ему нужно больше вычислений, чтобы воспроизвести исходный речевой сигнал. Требуется соответствующая цифровая техника и знание моделей речеобразования, при этом лингвистическая структура языка не используется.
Описанные выше методы ориентированы на такие речевые единицы, как слова, предварительно введенные в устройство с голоса диктора. Данный принцип лежит в основе функционирования синтезаторов с ограниченным словарем. В системах, использующих синтезатор с неограниченным словарем, единицами речи служат фонемы или слоги. Такие синтезаторы используют метод полного синтеза по правилам.
Полный синтез по правилам.
При синтезе речи по правилам также используются компилятивный и параметрический методы кодирования, но уже на уровне слогов.
Метод синтеза речи по правилам базируется на запрограммированном знании акустических и лингвистических ограничений и не использует непосредственно элементы человеческой речи.
Для запоминания этой информации требуется мало памяти, но чтобы извлечь из нее параметры, необходимы знания эксперта. Анализ текста — задача лингвистическая и включает в себя определение базовых фонетических, слоговых, морфемных и синтаксических форм, плюс вычленение семантической информации. Системы конвертации текста в речь являются наиболее комплексными системами синтеза речи, включающие в себя знания об устройстве речевого аппарата человека и лингвистической структуре языка.
Таким образом, этот метод дает полную свободу моделирования параметров и позволяет воспроизводить почти любой текст; значительно экономит память, не требуя хранения большого количества информации. Однако, синтезированная речь звучит хуже натуральной (и, как правило, хуже, чем синтезированная другими вышеописанными методами); такая система сложна в разработке.
В поисках компромисса между гибкостью полного синтеза речи по правилам и его экономичностью, был разработан синтез речи по правилам с использованием предварительно запомненных отрезков естественного языка.
Такой метод является разновидностью обычного синтеза по правилам. В зависимости от размера исходных элементов синтеза выделяются следующие виды синтеза: микросегментный (микроволновый); аллофонический; дифонный; полуслоговой; слоговой; синтез из единиц произвольного размера.
Обычно в качестве таких элементов используются полуслоги — сегменты, содержащие половину согласного и половину примыкающего к нему гласного.
Качество такого синтеза не соответствует качеству естественной речи, поскольку на границах сшивки дифонов часто возникают искажения. Компиляция речи из заранее записанных словоформ также не решает проблемы высококачественного синтеза произвольных сообщений, поскольку слов изменяются в зависимости от типа фразы и места слова во фразе. Это положение не меняется даже при использовании больших объёмов памяти для хранения словоформ. Тем не менее, такой метод генерации речи будет давать более качественный звук на выходе, по сравнению с простым методом синтеза по правилам.
Литература:
- Сорокин В. Н. Синтез речи. — М.: Наука, 1992. – 392 с.
- Фролов А., Фролов Г. Синтез и распознавание речи. — М.: Москва, 2008 г.
- Рабинер Л., Гоулд Б. Теория и применение цифровой обработки сигналов. — М: Мир, 1988. – 835 с.
