





Контролируемые методы машинного обучения как средство детектирования сетевых вторжений
Кожевникова Ирина Сергеевна, магистрант;
Ананьин Евгений Викторович, студент;
Лысенко Александр Вячеславович, студент;
Никишова Арина Валерьевна, доцент
Волгоградский государственный университет
Обнаружение аномалий является ключевым вопросом при обнаружении вторжений, в котором отклонение от нормального поведения указывает на наличие преднамеренных или непреднамеренных атак, ошибок, дефектов и др. В данной статье представлен обзор научных направлений применения контролируемых методов для решения проблем обнаружения аномалий.
Ключевые слова: контролируемое машинное обучение, система обнаружения вторжений, обнаружение аномалий
Применение методов машинного обучения для обнаружения вторжений позволит автоматически построить модель, основанную на наборе обучающих данных, которая содержит экземпляры данных, описанных с помощью набора атрибутов (признаков). Атрибуты могут быть различных типов, например качественными или количественными. Все существующие методы машинного обучения обнаружения аномалий можно разделить на два класса: контролируемые и неконтролируемые методы [1]. Общую схему методов можно представить схемой (рис. 1). В данной статье рассмотрим контролируемые методы машинного обучения для обнаружения аномалий.
1. К-ближайших соседей (K-NN)
K-NN является одним из простых и часто используемым непараметрическим методом. Он вычисляет приблизительные расстояния между различными точками входных векторов, а затем присваивает непомеченную точку к классу ее К-ближайшего соседа. В процессе создания K-NN классификатора (К) является важным параметром, и различные значения (К) могут вызвать различные последствия. Если К очень большое, соседи, которые используются для прогнозирования, будут потреблять большое время классификации и повлияют на точность.
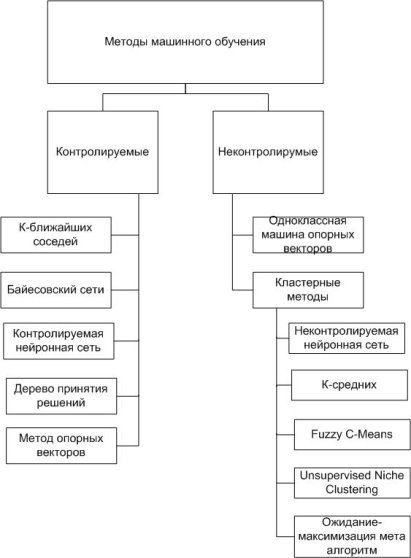
Рис. 1. Схема методов машинного обучения для обнаружения аномалий
2. Байсовские сети
Байесовская сеть (BN) представляет собой модель, которая кодирует вероятностные отношения между переменными. Этот метод обычно используется для обнаружения вторжений в сочетании со статистическими схемами. Она имеет ряд преимуществ, в том числе возможностью кодирования взаимозависимостей между переменными и предвидения событий, а также возможность включать предварительные знания и данные.
Johansen и Lee [2] указали, что система BN обеспечивает правильную математическую основу, чтобы сделать простой по-видимому трудную задачу. Они предположили, что IDS на основе BN будет различать атаки от обычной сетевой активности путем сравнения показателей каждого образца сетевого трафика. Moore и Zuev [3] использовали контролируемый Наивный Байесовский классификатор и 248 потоков функций чтобы дифференцировать между различными типами признаков, таких как длина пакета и время доставка, в дополнение к многочисленным TCP заголовкам. Корреляция отбора признаков была использована для определения сильных функций, и это показало, что лишь небольшое подмножество менее 20 признаков необходимо для точной классификации.
3. Контролируемая нейронная сеть (NNs)
NNS предсказывают поведение различных пользователей и демонов в системах. Если NNS должным образом разработаны и внедрены, то они способны решить многие проблемы, с которыми сталкиваются подходы, основанные на базе правил. Основным преимуществом NNS является их толерантность к неточным данным и неточной информации, а также их способность строить решения без предварительного знания закономерностей в данных.
Это, в сочетании с их способностью к обобщению изученных данных, сделало их подходящими для IDS. Для того чтобы применить этот подход к IDS, данные, представляющие атаки и не-атаки должны быть введены в NN для автоматической настройки сетевых коэффициентов на этапе обучения. Многослойный персептрон (MLP) и радиальная базисная функция (RBF) являются наиболее часто используемыми в контролируемых нейронных сетях.
MLP могут систематизировать только линейно разделимые экземпляры наборов. Если прямая или плоскость может быть обращена на отдельные входные экземпляры в разрешенные категории, входные экземпляры являются линейно разделимыми, то персептрон сможет найти решение. Если экземпляры не являются линейно разделимыми, то обучения никогда не достигнет точки, где все экземпляры систематизируются должным образом. Многослойные персептроны (искусственные нейронные сети) были созданы, чтобы попытаться решить эту проблему.
Были исследования, реализовавшие IDS с использованием MLP, которая имеет возможность обнаружения нормального соединения и атак, как в [4]. Они были реализованы с использованием MLP из трех и четырех слоев нейронной сети.
Радиальная базисная функция (RBF) является еще одним распространенным типом нейронных сетей. Так как они выполняют классификацию путем измерения расстояния между входами и центрами RBF скрытых нейронов, RBF сети гораздо быстрее, чем время, потребления обратного распространения, и наиболее подходит для задач с большим размером выборки.
4. Дерево принятия решений (DT)
Quinlan [5] определил деревья решение как «эффективный и распространенный инструмент для классификации и прогнозирования. Деревом решений является дерево, которое состоит из трех основных компонентов: узлы, дуги и листья. Каждый узел помечен особенным признаком, который является наиболее информативным среди признаков, еще не рассматриваемых по пути от корня. Каждая дуга из узла помечает значения признака узла, и каждый лист отнесен к категории или классу. Дерево решений может быть использовано для классификации точки данных, начиная с корня дерева и перемещаясь вниз, пока лист узла не будет достигнут. Лист узла обеспечивает классификацию точки данных. ID3 и C4.5, разработанные Куинланом являются наиболее распространенными вариантами реализации дерева решений».
Peddabachigari и др. [6], предложили деревья решений (DT) и метод опорных векторов (SVM) использовать в качестве модели обнаружения вторжений. Они также разработали гибридный метод DT-SVM, где SVM и DT используются в качестве базовых классификаторов. Joong и др. [7] адаптировали деревья решений для DoS-атак, R2L атак, U2R атак и атак сканирования. Алгоритм ID3 используется в качестве алгоритма обучения для автоматической генерации дерева решений.
5. Метод опорных векторов (SVM)
Метод опорных векторов (SVM) предложен Vapnik [8]. SVM преобразует входной вектор в многомерное пространство признаков, а затем получает оптимальную разделяющую гиперплоскость в высокой размерности пространства признаков. Кроме того, граничное решение, т. е. отделяющая гиперплоскость, определяет опорный вектор, а не целую обучающую выборку и, таким образом, является устойчивым к резко отклоняющимся значениям. В частности, SVM предназначен для бинарной классификации. То есть, чтобы отделить набор обучающих векторов, принадлежащих к двум различным классовым меткам. SVM также обеспечивает заданный пользователем параметр, называемый функцией штрафа. Это позволяет пользователям делать компромисс между числом выборок и ошибочной классификацией ширины границы решения.
Mukkamala и др. [9] разработали модель обнаружения сетевых аномалий с помощью SVM «применяются классификаторы ядра и методы проектирования классификатор к сети с проблемой обнаружения аномалий. Они оценивали влияние значений типа ядра и параметров на точность, с которой метод опорных векторов (SVM) выполняет классификацию вторжений. Jun и др. [10] предложили модель PSO-SVM применять к задаче обнаружения вторжений, стандарт PSO используется для определения свободных параметров опорных векторов и бинарный PSO состоит в получении оптимальной функции подмножества в системе обнаружения вторжений. Paulo и др. [11] предложили модель системы обнаружения вторжений на основе поведения сетевого трафика на основе анализа и классификации сообщений. Два метода искусственного интеллекта под названием Kohonen neural network (KNN) и опорных векторов (SVM) применяются для обнаружения аномалий.
Литература:
- Кожевникова И. С., Ананьин Е. В., Лысенко А. В., Никишова А. В. Применение машинного обучения для обнаружения сетевых аномалий // Молодой ученый. — 2016. — № 24. — С. 19–21.
- Johansen K. and Lee. ”CS424 network security: Bayesian Network Intrusion Detection (BINDS)”: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.83.8479.
- Moore D. 2005. Internet Traffic Classification Using Bayesian Analysis Techniques in Proceedings of ACM SIGMETRICS.
- Srinivas M. 2002.Intrusion Detection using Neural Networks and Support vector Machine. Proceedings of the IEEE International HI.
- Quinlan J. 1993.” C4.5: programs for machine learning”. Log Altos, CA, Morgan Kaufmann.
- Peddabachigari S., Abraham A., Grosan C. and Thomas J. 2007. ”Modeling Intrusion Detection System using Hybrid Intelligent Systems”. J. Netw. Comput. Appl, Vol. 30, NO1, PP. 114–132.
- Joong L., Jong H., Seon G. and Tai M.2008. ”Effective Value of Decision Tree with KDD99 Intrusion Detection Datasets for Intrusion Detection System”. ICACT, pp. 17–20.
- Theodoridis S. and Koutroumbas. 2006. ”Pattern recognition(3rd Ed.)”. USA: Academic Press.
- Mukkamala S., Sung A. and Ribeiro B. 2005. Model Selection for Kernel Based Intrusion Detection Systems. Proceedings of International Conference on Adaptive and Natural Computing Algorithm.
- Jun W., Xu H., Rong R. and Tai-hang L.2009.A Real Time Intrusion Detection System Based on PSO-SVM. Proceedings of the International Workshop on Information Security and Application (IWISA).
- Paulo M., Vinicius M. and Joni. 2010. Octopus-IIDS: An Anomaly Based Intelligent Intrusion Detection System. Proceedings of Computers and Communications (ISCC).
