





Прогресс в информационной сфере, а именно, развитие обработки данных приводят к огромному объему информации. В результате анализа значительных объемов информации возникает проблема представления требуемых данных в виде, подходящем для анализа [1]. Основным требованием, предъявляемым к информационной системе, ориентированной на анализ данных, является своевременное обеспечение аналитика всей информацией, необходимой для принятия решения.
Интеллектуального анализа данных (Data Mining) представляет собой сочетание обширного математического инструментария и последних достижений в сфере информационных технологий. В сфере анализа данных гармонично объединились строго формализованные методы и методы неформального анализа, т. е. количественный и качественный анализ данных [2].
Основу методов Data Mining составляют всевозможные методы классификации, моделирования и прогнозирования. Знания, добываемые методами Data mining, принято представлять в виде моделей.
Модели представления знаний Data Mining подразделяют на:
1) ассоциативные правила;
2) деревья решений;
3) кластеры;
4) математические функции.
Методы построения таких моделей принято относить к области искусственного интеллекта. К алгоритмам интеллектуального анализа данных относятся: байесовские сети, деревья решений, нейронные сети, метод ближайшего соседа, метод опорных векторов, линейная регрессия, корреляционно-регрессионный анализ, иерархические методы кластерного анализа, неиерархические методы кластерного анализа, методы поиска ассоциативных правил (в частности алгоритм Apriori) метод ограниченного перебора эволюционное программирование и генетические алгоритмы, разнообразные методы визуализации данных и множество других методов [5].
Большинство аналитических методов, используемые в технологии Data Mining являются наиболее известными математические алгоритмы и методы. Новым в их применении является возможность их использования при решении тех или иных конкретных проблем, обусловленная появившимися возможностями технических и программных средств.
В данной статье производится сравнительный анализ двух алгоритмов (нейронной сети и деревьев принятия решений) интеллектуального анализа данных на основе задачи: оценка влияния гендерной принадлежности студента на его успеваемость в ВУЗе. Для проведения интеллектуального анализа данных будем использовать компонент Microsoft SQL Server 2012 — Microsoft Analysis Services.
В службы Analysis Services представлено несколько алгоритмов для использования в решениях интеллектуального анализа данных. Эти алгоритмы являются реализациями некоторых из наиболее популярных методов, используемых в интеллектуальном анализе данных.
Выбор правильного алгоритма для использования в конкретной аналитической задаче может быть достаточно сложным. В то время как можно использовать различные алгоритмы для выполнения одной и той же задачи, каждый алгоритм выдает различный результат, а некоторые алгоритмы могут выдавать более одного типа результатов [2]. Например, можно использовать алгоритм дерева принятия решений (Майкрософт) не только для прогнозирования, но также в качестве способа уменьшения количества столбцов в наборе данных, поскольку дерево принятия решений может идентифицировать столбцы, не влияющие на конечную модель интеллектуального анализа данных.
Дерево решений, связанное с большинством других методов, используют в рамках критериев отбора так же для поддержки выбора определенных данных в рамках общей структуры. Дерево решений начинают с простого вопроса, который имеет два ответа (но возможно и больше). Каждый ответ приводит к следующему вопросу помогая классифицировать и идентифицировать данные или делать прогнозы. Деревья решений чаще всего используются с системами классификации информации системами прогнозирования, где различные прогнозы могут основываться на прошлом историческом опыте, который помогает построить структуру дерева решений и получить результат [3].
Искусственная нейронная сеть представляет собойсистемусоединённых и взаимодействующих между собой простыхпроцессоров(искусственных нейронов). Такие процессоры обычно довольно просты (особенно в сравнении с процессорами, используемыми в персональных компьютерах). Каждый процессор подобной сети имеет дело только с сигналами, которые он периодически получает, и сигналами, которые он периодически посылает другим процессорам [4]. И, тем не менее, будучи соединёнными в достаточно большую сеть с управляемым взаимодействием, такие локально простые процессоры вместе способны выполнять довольно сложные задачи.
В качестве исходных данных мы используем набор данных из базы ВУЗа. И на основе успеваемости и социальной активности студента найдем вероятность гендерной принадлежности.
Для выявления черт, присущих студентам создадим представление, в котором будет содержаться информация о студентах. Эти данные мы будем использовать в качестве материала для машинного обучения и выявления атрибутов, влияющих на повышения данной вероятности.
Таблица 1
Атрибуты представления набора данных
|
Название атрибута |
Значение |
|
Pol |
Полстудента |
|
institute |
Факультет, на котором обучается студент |
|
specName |
Специальность, на которой обучается студент |
|
nformob |
Форма обучения |
|
ncontstatus |
Основа финансирования |
|
fio |
ФИО студента |
|
ne_attestovan |
Количество не аттестованных дисциплин |
|
ne_ayvka |
Количество неявок на аттестацию |
|
ne_dopysk |
Количество не допусков к аттестации |
|
ne_zachet |
Количество не зачтенных дисциплин |
|
Two |
Количество неудовлетворительных оценок |
|
Three |
Количество удовлетворительных оценок |
|
Four |
Количество оценок «хорошо» |
|
five |
Количество оценок «отлично» |
|
zachet |
Количество зачтенных дисциплин |
|
socialActivityEventName |
Название мероприятия, в котором участвовал студент |
|
socialActivityRateName |
Роль студента в данном мероприятии |
Необходимо понимать, что не все параметры предметной области влияют на выходной вектор. Параметры, которые не оказывают влияния на выходной вектор, называют незначимыми для него. Естественно, что незначимые параметры не следует включать в список параметров входного вектора. Однако на практике часто бывает трудно и даже невозможно установить, какие из параметров предметной области являются значимыми, а какие нет. Поэтому на первом этапе в входной вектор включают как можно больше параметров [6]. Данные параметры были выбраны как наиболее влияющие на гендерную принадлежность студента. После первоначального создания, обучения и тестирования сети, незначимые параметры были выявлены путем возмущения входных параметров и анализа реакции сети на эти возмущения.
Сеть оставалась такой же, но на вход подавались 18 параметров, поочередно убирая каждый из входных параметров. Сеть снова обучалась и тестировалась, а на основе прогноза и исходных данных вычислялась погрешность обобщения. Если погрешность не реагирует или слабо реагирует на нехватку входного параметра, то этот параметр является незначимым.
После выявления и исключения входных нейронов, соответствующих незначимым параметрам, качество нейронной сети улучшается, так как снижается ее размерность. Однако надо учитывать, что слишком малое число входных параметров может привести к тому, что нейронной сети не хватит данных для выявления требуемых от нее закономерностей предметной области.
При выборе алгоритма «Нейронные сети» в модели анализа мы можем определить какие значения атрибутов повышают вероятность попадания пользователя в целевую группу:
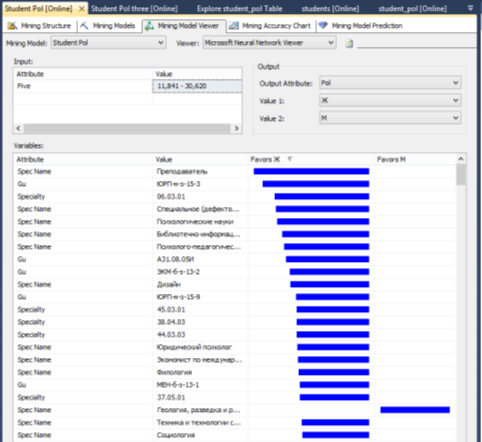
Рис. 1. Результат анализа с помощью нейронных сетей
Построив «Диаграмму точности прогнозов» (рисунок 2) для алгоритма Нейронные сети, можно отметить, что прогнозируемая модель не идеальна, но с высокой вероятностью предсказания: Оценка — 0,85; Правильное заполнение — 44,46 %; Вероятность предсказания — 81,30 %.
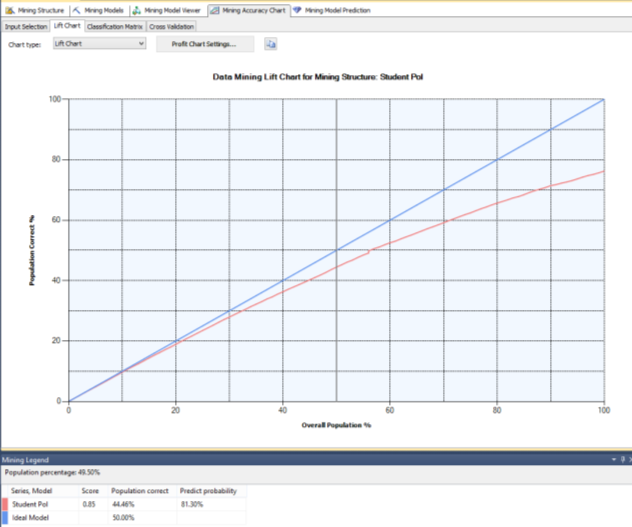
Рис. 2. Оценка точности прогноза с помощью нейронной сети
Средство просмотра деревьев в службах Microsoft SQL Server Службы Analysis Services отображает деревья принятия решений, построенные с помощью алгоритма дерева принятия решений. Алгоритм дерева принятия решений — это гибридный алгоритм дерева принятия решений, который поддерживает и классификацию, и регрессию. Поэтому это средство просмотра можно использовать для просмотра моделей, основанных на алгоритме линейной регрессии. Алгоритм дерева принятия решений используется для прогнозирующего моделирования дискретных и непрерывных атрибутов.
Выделяются следующие характеристики, влияющие на прогнозируемый элемент:
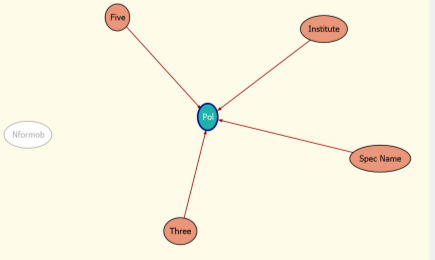
Рис. 3. Сеть зависимостей при использовании алгоритма дерева принятия решений
Пошагово рассмотрев дерево принятия решений, можно составить алгоритм влияния гендерного признака на успеваемость:
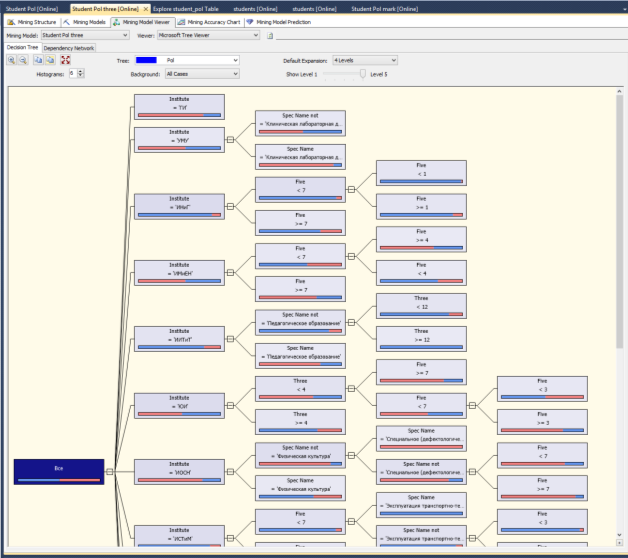
Рис. 4. Использование алгоритма дерева принятия решений
Используя данный алгоритм можно выявить с процентной долей вероятности гендерную принадлежность студента:
Рис. 5. Вероятности гендерной принадлежности студента
Построив «Диаграмму точности прогнозов» (рисунок 6) для алгоритма «Дерево принятия решений», можно отметить, что прогнозируемая модель близка к идеальной: Оценка — 0,84; Правильное заполнение — 43,16 %; Вероятность предсказания — 78,43 %.
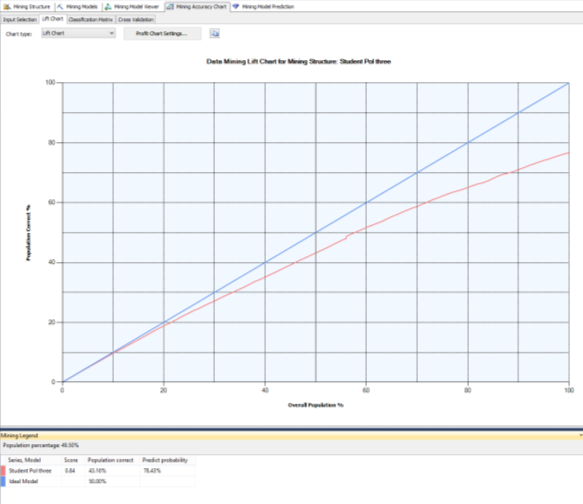
Рис. 6. Диаграмма точности прогнозов для структуры интеллектуального анализа данных: алгоритм дерева принятия решений.
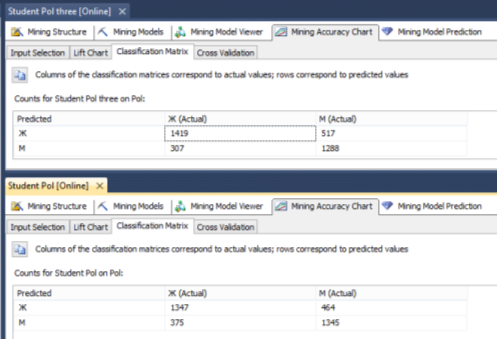
Рис. 7. Сравнения точности прогнозируемых результатов исследуемыми алгоритмами
По матрице классификации, изображенной на рисунке 7 можно рассчитать вероятность ошибки по каждому исследуемому алгоритму. В случае с использованием алгоритма деревьев принятия решений, результаты которого изображены в верхней части рисунка 7, полученная вероятность ошибки немного меньше, чем при использовании нейронных сетей. Но в следствие переобучения наблюдается увеличения ошибок первого рода.
Проанализировав методы интеллектуального анализа данных можно отметить следующие преимущества нейронных сетей перед традиционными вычислительными системами:
‒ нейронная сеть способная решать задачи, в которых неизвестны закономерности развития ситуации и зависимости между входными и выходными данными;
‒ возможность работы при наличии большого числа неинформативных, шумовых входных сигналов;
‒ нейронная сеть способна адаптироваться к изменениям окружающей среды. Т. е. нейронные сети, обученные в определенной среде, могут без труда быть переучены для работы в условиях незначительных колебаний параметров среды;
‒ нейронные сети обладают потенциальным сверхвысоким быстродействием за счет использования массового параллелизма обработки информации;
Преимущества использования деревьев решений:
‒ быстрый процесс обучения;
‒ генерация правил в областях, где эксперту трудно формализовать свои знания;
‒ извлечение правил на естественном языке;
‒ интуитивно понятная классификационная модель;
‒ высокая точность прогноза, сопоставимая с другими методами (статистика, нейронные сети);
‒ построение непараметрических моделей.
В силу этих и многих других причин, методология деревьев решений является важным инструментом в работе специалиста-аналитика.
В результате исследования было установлено, что для решения данной задачи лучше подходит алгоритм деревья принятия решений.
Сравнительный анализ выбранных и примененных к решению задачи методов интеллектуального анализа данных показывает, что не существует универсального алгоритма для извлечения новых знаний. При использовании любого алгоритма важно понимать его достоинства и недостатки, учитывать природу данных, с которыми он лучше работает и объективно оценивать способность алгоритма к масштабируемости.
Литература:
- Бахвалов Н. С., Лапин А. В., Чижонков Е. В. Численные методы в задачах и упражнениях. — М.: Высшая школа, 2010.
- Башмаков А. И., Башмаков И. А. Интеллектуальные информационные технологии: Учеб. пособие. — М.: Изд-во МГТУ им. Н. Э.Баумана, 2005.
- Дороганов В. С., Пимонов А. Г. Методы статистического анализа и нейро-сетевые технологии для прогнозирования показателей качества металлургического кокса / Дороганов В. С., Пимонов А. Г. // Вестник Кемеровского государственного университета. — 2014. — № 4, Т. 3. — С. 123–129.
- Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы = Siecineuronowe, algorytmygenetycznei systemyrozmyte. — 2-е изд.. — М.: Горячая линия-Телеком, 2010. — С. 452.
- Уоссермен Ф. Нейрокомпьютерная техника — теория и практика. — М.: Вильямс, 2010.
- Хайкин С. Нейронные сети: Полный курс. Пер. с англ. Н. Н. Куссуль, А. Ю. Шелестова. 2-е изд., испр. — М.: Вильямс, 2008.
