





Результаты измерений показывают, что EC2 содержит как хорошие и плохие экземпляры виртуальных машин с точки зрения сети хвоста задержками, мы проектируем бобтейл. Для нахождения хороших экземпляров для работы чувствительных к задержкам приложений. Конкретно, хорошие экземпляры являются те, делить с ними процессоры только с совместимыми рабочими нагрузками или те, которые не разделяют на всех, в то время как плохие экземпляры являются те, которые совместно, запланированных с несовместимыми рабочих нагрузок. Таким образом, облачные клиенты могут затем развернуть их чувствительных к задержкам приложений только на хороших экземпляров VM ожидать более предсказуемую производительность сети.
Бобтейл использует гостевой-ориентированный подход, который требует только гостей, чтобы узнать, является ли их рабочие нагрузки чувствительны к задержкам или CPU-оценка, а клиенты Облако может использовать бобтейла в качестве библиотеки, чтобы решить, на котором экземпляры для запуска их чувствительных к задержкам рабочие нагрузки без каких-либо изменений в облачной инфраструктуре [1, с. 13]. В то время как бобтейл не улучшает изоляцию VM напрямую, это снижает производительность помех общих моделей коммуникации выгода от сокращения до 40 % в 99.9-й процентиль времени отклика.
Потенциальная польза
Чтобы понять, как, сколько улучшение возможно, и как трудно было бы получить, мы измерили влияние плохих узлов для общих моделей коммуникации: последовательного и разделов-агрегации. В последовательной модели клиент RPC вызывает некоторое количество серверов последовательно для завершения одного, приуроченный наблюдение [9, с. 23].
Для последовательной модели мы имитируем рабочий поток времени завершения путем отбора проб из измеренных распределений RTT хороших и плохих узлов. Конкретно, каждый раз, когда мы случайным образом выбираем один узел из серверов RPC N, чтобы запросить 10 притоки последовательно, и мы повторяем это 2000000 раз. Рисунок 1 показывает, 99-й и 99.9-й процентили значения работы потока времени завершения, с увеличением числа плохих узлов среди в общей сложности 100 экземпляров [2, с. 36].
Интересно отметить, что нет никакой разницы в хвостах общего времени завершения, когда больше, чем 20 % узлов являются плохими. Но разница в поток времени завершения хвост между 20 % плохих узлов и 50 % плохих узлов суров: поток времени завершения увеличивается в три раза на 99-й процентиль, и аналогичная картина существует в 99.9-й процентили с меньшим различием. Это означает, что бобтейл разрешается делать ошибки, даже если до 20 % случаев, выбранных бобтейл, на самом деле плохо виртуальные машины, она по-прежнему помогает уменьшить поток времени завершения, когда по сравнению с использованием случайных экземпляров из EC2 [4, с. 45].
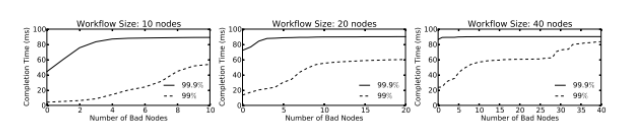
Рис. 1.
Наши измерения показывают, получая 50 % плохих узлов из EC2 не является редкостью.
Проектирование системы ивнедрение
Бобтейл должна быть масштабируемая система, которая делает правильные решения своевременно. В то время как свойство узла остается стабильной в нашей пяти недель измерения, эмпирические данные показывают, что чем дольше работает бобтейл, тем точнее его результат может быть. Однако, поскольку запуск экземпляра занимает не более минуты в EC2, мы ограничиваем бобтейлов принятия решения в рамках двух минут [3, с. 15].
Таким образом, нам необходимо установить баланс между точностью и масштабируемостью. Наивный подход может просто проводить измерения сети с каждым CAN-didate. Но тем не менее точны это может быть, такая конструкция не очень хорошо масштабируется для обработки большого количества экземпляров кандидатов параллельно: сделать это в короткий промежуток времени потребует отправки большого количества сетевых Traf ц с как можно быстрее для всех кандидатов, и синхронное характер измерений может привести к серьезной перегрузки сети или даже TCP incast.
С другой стороны, наиболее масштабируемый подход предполагает проведение испытаний на местах в случаях, кандидаты, которые не зависит от каких-либо ресурсов за пределами самого экземпляра. Таким образом, все операции можно сделать быстро и параллельно [8, с. 22].
На основе нашего анализа первопричины, такой метод существует, так как часть длинного хвоста проблемы мы ориентируемся на это свойство узлов вместо сети [1, с. 18]. Соответственно, если мы знаем, что модели рабочей нагрузки виртуальных машин совместно расположенных с жертвой VM, мы должны быть в состоянии предсказать, если жертва VM будет иметь плохое распределение задержками локально без каких-либо измерений сети.
Для того, чтобы достичь этого, мы должны сделать вывод, как часто задержки долго планирования случаются с жертвой VM [7, с. 53]. Поскольку длительные задержки планирования, вызванные совмещенных ресурсоемкие виртуальных машин не являются уникальными для сети обработки пакетов и любые события прерывания на основе будет страдать от той же проблемы, мы можем измерить частоту больших задержек путем измерения времени для цели VM, чтобы проснуться от сна функции вызова-задержки обработки прерывания таймера является прокси-за задержки в обработке всех аппаратных прерываний [3, с. 25].
Чтобы проверить эту гипотезу, мы повторяем пять контролируемых экспериментов, представленные в анализе основных причин. Но вместо запуска сервера RPC в жертвы VM и измерения RTTS с другим клиентом, жертва VM запускает программу, которая закругляется спать 1мс и измеряет время стенки для операции сна [6, с. 27]. Как правило, виртуальная машина должна быть в состоянии проснуться после того, как чуть более 1 мс, но совмещенных ресурсоёмким виртуальные машины могут помешать ему сделать это, что приводит к большим задержкам.
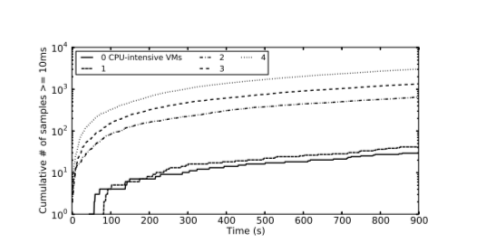
Рис. 2.
Рисунок 2 показывает, сколько раз, когда время сна поднимается выше 10 мс в пяти сценариев контролируемых экспериментов. Как и следовало ожидать, когда два или более виртуальных машин являются ресурсоемкие, количество больших задержек, с которыми сталкиваются жертвы VM один на два порядка выше, что опытный, когда ноль или один виртуальные машины ресурсоёмким. Хотя доля таких больших задержек мал во всех сценариях, большая разница в исходных графов образует четкий критерий для различения плохих узлов из хороших узлов. Кроме того, хотя это не показано на рисунке, мы находим, что большие задержки с ноль или один CPU-интенсивных виртуальных машин в основном появляются при длине около 60мс или 90 мс; они вызваны крышкой ЦП 40 % на каждом, чувствительного к задержкам VM (то есть, когда они не имеют права использовать процессор, несмотря на доступность).
По результатам наших контролируемых экспериментов, мы можем разработать алгоритм выбора экземпляра спрогнозировать локально, если целевая виртуальная машина будет испытывать большое количество длительных задержек планирования. Алгоритм 1 показывает псевдокод нашего дизайна. Хотя алгоритм 35itself прост, задача состоит в том, чтобы фи-й правый порог в EC2 различать два случая (LOW_MARK и HIGH_MARK) и сделать точный вывод о том как можно быстрее (петли размер M) [6, с. 13].
Наша текущая политика заключается в снижении ложных срабатываний, так как в структуре разделов-агрегации, уменьшение плохих узлов имеет решающее значение для масштабируемости. Стоимость такого консерватизма в том, что мы можем обозначить хорошие узлы, как плохо неправильно, и в результате мы должны создавать объект даже больше узлов, чтобы достичь требуемого количества. Для возврата г N хорошие узлы в соответствии с просьбой пользователей, наша система должна запустить K * N экземпляров, а затем ему необходимо, обрести лучшие N экземпляров этого набора с наименьшей вероятностью получения длинных хвостов задержками.
Параметризация
Для реализации алгоритма бобтейл, мы должны определить как его выполнения (етли размер M) и пороговые значения для параметров LOW_MARK и HIGH_MARK. Наш проект намерен ограничить время тестирования до менее двух минут, так что в нашей текущей реализации мы устанавливаем размер петли M, чтобы быть 600k операции сна, что переводится примерно 100 секунд на небольших случаях в EC2-тем хуже экземпляр, тем дольше его принимает.
Рисунок 3 показывает компромисс между ложноположительных и ложноотрицательных LOW_MARK от 0 до 100. точка поворота сплошной линией появляется, когда мы устанавливаем LOW_MARK около 13, что позволяет достичь бобтейл <0,1 ложных срабатываний во время поддержания ложноотрицательный скорость около 0,3-хороший баланс между ложноположительных и ложноотрицательных результатов. После того, как HIGH_MARK вводится (как пять раз LOW_MARK), эффективная ставка ложная 37 может быть снижена до уровня ниже 0,1, хотя и с помощью сети на основе тестирования. Мы оставляем его в качестве будущей работы по изучению, когда нам нужно заново откалибровать эти параметры [5, с. 25].
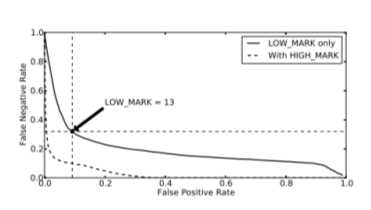
Рис. 3.
Выше результат отражает наш принцип в пользу низкой ложных срабатываний. Поэтому нам нужно использовать относительно большое значение K, чтобы получить N хорошие узлы из K * N кандидатов. Напомним, что наша измеряется хорошее соотношение узел для случайных экземпляров непосредственно возвращаемых EC2 колеблется от 0,4 до 0,7. Таким образом, как оценка, с 0,3 ложноотрицательных скорости и от 0,4 до 0,7 хорошее соотношение узла для случайных экземпляров из нескольких центров обработки данных, нам нужно K * N * (1 -0,3) * 0,4 = N или K ≈ 3,6 для извлечения количество требуемых хороших узлов из одной партии кандидатов. Тем не менее, в связи с широким распространением плохих экземпляров в EC2, даже если бобтейл не делает никаких ошибок, которые мы до сих пор нужно как минимум K * N * 0,4 = N или К = 2,5. Если задержками запуска является критическим ресурсом, а не вознаграждения, выплаченного начать новые экземпляры, можно увеличить этот фактор, чтобы улучшить время отклика.
Оценка
В этом пункте, мы оцениваем нашу систему в течение двух зон доступности (AZS) в EC2 в восточном регионе США. Эти два AZS всегда возвращают некоторые плохие узлы. Мы сравниваем задержками хвосты экземпляров и выбранные нашей системой и запускается непосредственно через стандартный механизм. Мы проводим это сравнение с использованием как микро-контрольных показателей и моделей последовательных и разделов-агрегации рабочих нагрузок.
В каждом испытании, мы сравним 40 небольших экземпляров инициированы непосредственно EC2 от одного AZto 40 небольших экземпляров, выбранных нашей системой из того же AZ. Сравнение производится с серией тестов; эти небольшие экземпляры будут запускать серверы RPC для всех тестов. Для запуска 40 хороших экземпляров, мы используем K = 4 160 экземпляров кандидатов. Кроме того, мы открываем четыре дополнительных больших экземпляров на каждые 40 небольших экземпляров для запуска клиентов RPC. Мы делаем это потому, что, как обсуждалось ранее, дополнительные крупные экземпляры не испытывают дополнительные проблемы длинный хвост; Поэтому мы можем винить экземпляров сервера для плохих распределений задержками.
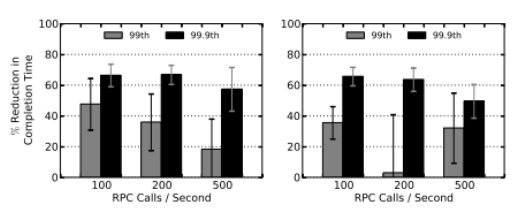
Рис. 4.
Микро контрольные показатели
Наши модели для обеих микро-критериев и последовательных и разделов рабочих нагрузок агрегации имеют между поступлениями времена RPC вызовов, образующих пуассоновский процесс. Для микро-тестов, мы относим 10 небольших серверов, например, для каждого дополнительного крупного клиента. Скорости RPC вызовов установлены на уровне 100, 200 и 500 звонков / сек. В каждом вызове RPC, клиент посылает запрос на 8 байт на сервер, а сервер отвечает 2KB случайных данных. В то же время, как запросы и ответы упакованы с другой накладные расходы 29 байт. Размер 2KB сообщение было выбрано потому, что измерения, сделанные в выделенном центре данные указывают на то, что большинство чувствительных к задержкам Потоки около 2 КБ. Обратите внимание, что мы не создают искусственным фон Traf фи с, потому что реальный фон траф фи с уже существует на протяжении EC2, где мы оцениваем бобтейлов.
На рисунке 3 представлены сокращения времени выполнения для запроса ставок три RPC в микро-тестах по двум AZS. Бобтейл уменьшает время ожидания при 99.9-й процентили с 50 % до 65 %. В микро-тестов и последующих оценок, среднее процентного сокращения потока в завершение представлен с 90 % интервалом подтвер- симость.
Однако улучшения на 99-й процентиль меньше с более высокой дисперсией. Это происходит потому, что, как показано на рисунке 3.1, 99-й процентиль RTTS внутри EC2 не очень плохо, чтобы начать с (~2.5ms); Таким образом, улучшение пространства бобтейл является намного меньше, на 99-й процентиль, чем на 99.9-й процентили. По той же причине, перегрузка сети может иметь большое влияние на 99-й процентиль, имея незначительное влияние на 99.9-й процентили в EC2. Останец 200 вызовов / сек во втором AZ на рисунке 4.5 вызывается одним испытании 39in эксперимент с 10 хороших небольших экземпляров, которые выставлены аномально большие значения на 99-й процентиль.
Литература:
1. Craig Labovitz. How Big is Amazon’s Cloud? http://www.deepfield.net/2012/04/how-big-is-amazons-cloud/.
2. Lydia Leong, Douglas Toombs, Bob Gill, Gregor Petri, and Tiny Haynes. Magic Quadrant for Cloud Infrastructure as a Service. Gartner, October 2012.
3. Paul Barham, Boris Dragovic, Keir Fraser, Steven Hand, Tim Harris, Alex Ho, Rolf Neugebauer, Ian Pratt, and Andrew Warfield. Xen and the Art of Virtualization. In Proceedings of the 19th ACM Symposium on Operating Systems Principles (SOSP’03), Bolton Landing, NY, USA, October 2003.
4. Guohui Wang and T. S. Eugene Ng. The Impact of Virtualization on Network Performance of Amazon EC2 Data Center. In Proceedings of the 29th conference on Information communications (INFOCOM’10), San Diego, CA, USA, March 2010.
5. T. Ristenpart, E. Tromer, H. Shacham, and S. Savage. Hey, You, Get Off of My Cloud! Exploring Information Leakage in Third-Party Compute Clouds. In Proceedings of the 16th ACM Conference on Computer and Communications Security (CCS’09), Chicago, IL, USA, November 2009.
6. Guohui Wang and T. S. Eugene Ng. The Impact of Virtualization on Network Performance of Amazon EC2 Data Center. In Proceedings of the 29th conference on Information communications (INFOCOM’10), San Diego, CA, USA, March 2010.
7. J¨org Schad, Jens Dittrich, and Jorge-Arnulfo Quian´e-Ruiz. Runtime Measurements in the Cloud: Observing, Analyzing, and Reducing Variance. In Proceedings of the 36th International Conference on Very Large Data Bases (VLDB’10), Singapore, September 2010.
8. Sean K. Barker and Prashant Shenoy. Empirical Evaluation of Latency-sensitive Application Performance in the Cloud. In Proceedings of the 1st annual ACM SIGMM conference on Multimedia systems (MMSys’10), Scottsdale, AZ, USA, February 2010.
9. Ang Li, Xiaowei Yang, Srikanth Kandula, and Ming Zhang. CloudCmp: Comparing Public Cloud Providers. In Proceedings of the 2010 Internet Measurement Conference (IMC’10), Melbourne, Australia, November 2010.
