





Основными последствиями воздействия угроз на автоматизированную систему управления является в конечном счете нарушение безопасности функционирования объекта управления. Рассмотрим эти последствия, а также перечень и сущность различных видов угрожающих воздействий, которые являются причинами дискредитации системы защиты информационно-вычислительной системы.
Построение нечеткой модели идентификации параметров качества системы управления (СУ) и, в частности, процессов поддержки информационной безопасности (ИБ) характеризуется взаимосвязью входных и выходных параметров, а также взаимозависимостью выходных параметров от входных. В основу построения метода положена нечеткая оценочная модель ЛВС. При этом тип оценочной модели не должен существенно влиять на выбор средств поддержки ИБ на заданном уровне.
Рассматриваемый метод реализуется следующими шагами.
Шаг 1. Предварительная обработка статистической информации, характеризующей реализацию функций Y ЛВС в условиях воздействия угроз Х, т. е. Y=F(X).
Шаг 2. Выбор существенного состава входных (X) и выходных (Y) параметров и их количественных значений.
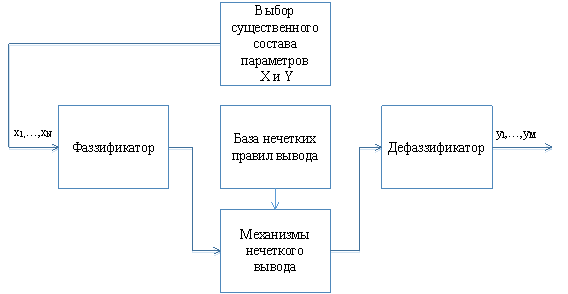
Рис. 1. Обобщенная модель поддержки предпочтительного уровня ИБ ЛВС
Шаг 3. Выбор типа шкалы и представление значений X и Y в виде функций принадлежности нечетких множеств.
Шаг 4. Фаззификация входных и выходных параметров. Выбор числа, видов и параметров термов функции принадлежности.
Шаг 5. Формирование множества правил вывода базы знаний (БЗ).
Шаг 6. Выбор механизма нечеткого вывода.
Шаг 7. Выбор метода и средств дефаззификации.
Рассмотрим реализацию выше приведенных шагов.
На шаге 1 выполняется предварительная обработка статистической информации, кластеризация, оценка репрезентативности и др. Важным аспектом, определяющим качество функционирования системы поддержки заданного уровня ИБ ЛВС, является выбор наиболее существенного состава входных (X) и выходных (Y) параметров. Такой выбор на шаге 2 реализуется оценкой существенности путем применения группы методов математической статистики (рис. 2).
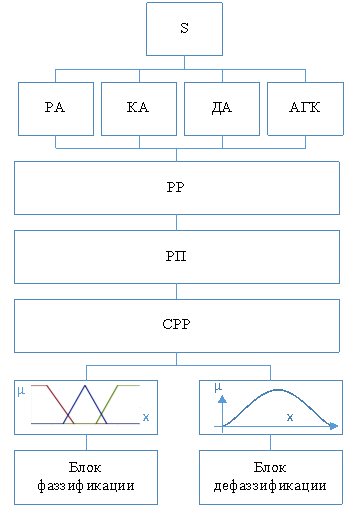
Рис. 2. Модель выбора существенного состава параметров
Здесь статистические данные S обрабатываются методами регрессионного (РА), корреляционного (КА) и дисперсионного (ДА) анализа, а также алгоритмом главных компонент (АГК).
По каждому из этих методов строятся соответствующие ряды ранжирования (РР) и далее по выбранному решающему правилу (РП) строится синтезированный ряд ранжирования (СРР) для входного (X) и выходного (Y) состава существенных параметров.
Реализация шага 3 выполняется одним из прямых или косвенных методов [1]. Параметры выбранных функций принадлежности термов лингвистических переменных выбираются на основе или статистических данных, или на экспертной основе и в последующем эти данные учитываются при обучении построенной нечеткой модели.
Результатами реализации шага 4 являются:
− наименование и состав лингвистических переменных (ЛП) X и Y;
− число термов ЛП;
− вид функции принадлежности;
− значения параметров функции принадлежности для выбранного состава термов параметров X и Y.
На следующем шаге осуществляется соотношение значений выходных параметров с соответствующими управляющими решениями и выделением их групп. Так, изменение состава угроз ЛВС x1,…,xN может приводить к комплексному изменению выходных параметров y1, …,yM.
Рассмотрим реализацию этого шага для трех входных угроз (x1, x2, x3) и двух выходных параметров (y1, y2). Иначе, рассмотрим нечеткую систему идентификации для трех входных ЛП и двух выходных (табл. 1).
Число термов обеих ЛП и их значение примем равным трем: М- «МАЛОЕ»; С- «СРЕДНЕЕ»; Б- «БОЛЬШОЕ».
Таблица 1
|
Параметры ИБ ЛВС иих значения |
|||
|
Вход (атака) |
Значение (интервал) |
Выход (решение по противодействию) |
Значение (интервал) |
|
«Преднамеренное разоблачение»: умышленный допуск к охраняемым данным субъекта, не имеющему на это право. |
Вероятность попадания информации абоненту, которому она не предназначена. P≈0,87 |
Ограничение доступа субъекта к категорийной информации. |
Вероятность доступа к охраняемой информации (в зависимости от метода ограничения доступа). P≈0,01–0,17 |
|
«Просмотр остатка данных»: исследование доступных данных, оставшихся в системе, с целью получения несанкционированного знания охраняемых данных. |
Вероятность попадания информации абоненту, которому она не предназначена. P≈0,56 |
Удаление временных файлов из системы после окончания работы. |
Вероятность прочтения удаленных файлов (за приемлемый для злоумышленника временной интервал). P≈0,03 |
|
«Аппаратно-программная ошибка»: ошибка системы, которая повлекла за собой системы данных. |
Вероятность выхода из строя системы. P≈0,01 |
Резервирование данных системы. |
Вероятность восстановление системы после сбоя. P≈0,99 |
|
«Кража»: получение доступа к охраняемым данным. |
Вероятность попадания информации абоненту, которому она не предназначена. P≈0,15 |
Использование средств защиты от копирования и использования несанкционированных физических носителей. |
Вероятность получения конечных данных (в зависимости от метода и средств защиты данных). P≈0,01–0,25 |
|
«Прослушивание (пассивное)»: обнаружение и запись данных, циркулирующих между двумя терминалами в системе связи. |
Вероятность попадания информации абоненту, которому она не предназначена. P≈0,19 |
Использование систем защиты каналов связи. |
Вероятность утечки исходной информации. P≈0,07 |
|
«Анализ трафика»: получение знания охраняемых данных путем наблюдения за изменением характеристик системы связи. |
Вероятность попадания информации абоненту, которому она не предназначена, дискредитация канала связи. P≈0,3 |
Использование криптопротоколов. |
Вероятность получения исходных данных из трафика (в зависимости от протокола и вычислительных мощностей злоумышленника). P≈0,05–0,2 |
|
«Анализ сигналов»: не прямое получение знания охраняемых данных или их изменение. |
Вероятность не прохождения сигнала тревоги или генерация ложных сигналов. P≈0,76 |
Использование защитных экранов. |
Вероятность предотвращения анализа сигналов (в зависимости от используемых средств защиты). P≈0,8–0,99 |
Формы ЛП термов примем в виде, представленном на рисунке 3.
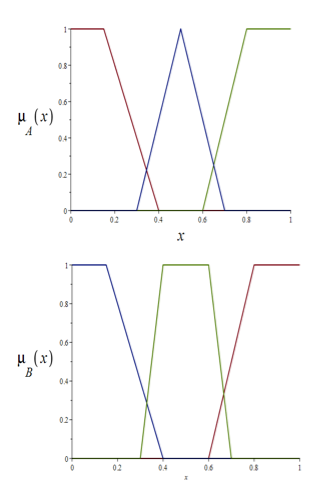
Рис. 3. Функции принадлежности термов параметров X и Y
Таблица 2
|
Соответствие значений термов Yрешениям Р. |
||||||||
|
Y1 |
Y2 |
типрешения |
||||||
|
P1 |
P2 |
P3 |
P4 |
P5 |
P6 |
P7 |
||
|
|
|
* |
||||||
|
|
|
* |
||||||
|
|
|
* |
* |
|||||
|
|
|
* |
* |
|||||
|
|
|
* |
* |
|||||
|
|
|
* |
||||||
|
|
|
* |
* |
|||||
|
|
|
* |
* |
|||||
|
|
|
* |
||||||
Из данной таблицы могут быть выделены однородные группы (G) решений нечеткой модели выбора.
- G1:P1;
- G2:P2 ^ P7;
- G3:P2 ^ P5;
- G4:P3 ^ P5;
- G5:P3 ^ P7;
- G6:P4 ^ P6;
- G7:P4 ^ P7;
На следующем (шаге 5) формируются правила вывода решений. В общем виде эти правила (Р) могут быть представлены следующим образом (табл. 3).
Таблица 3
|
Нечеткие правила модели |
||||||
|
Р |
Х |
У |
G |
|||
|
Х1 |
Х2 |
Х3 |
y1 |
y2 |
||
|
P1 |
|
|
|
|
|
G1 |
|
P2 |
|
|
|
|
|
G1 |
|
P3 |
|
|
|
|
|
G5 |
|
P4 |
|
|
|
|
|
G2 |
|
P5 |
|
|
|
|
|
G1 |
|
P6 |
|
|
|
|
|
G4 |
|
P7 |
|
|
|
|
|
G5 |
|
P8 |
|
|
|
|
|
G4 |
|
P9 |
|
|
|
|
|
G4 |
|
P10 |
|
|
|
|
|
G3 |
|
P11 |
|
|
|
|
|
G4 |
|
P12 |
|
|
|
|
|
G4 |
|
P13 |
|
|
|
|
|
G4 |
|
P14 |
|
|
|
|
|
G4 |
|
P15 |
|
|
|
|
|
G4 |
|
P16 |
|
|
|
|
|
G6 |
|
P17 |
|
|
|
|
|
G6 |
|
P18 |
|
|
|
|
|
G6 |
|
P19 |
|
|
|
|
|
G4 |
|
P20 |
|
|
|
|
|
G4 |
|
P21 |
|
|
|
|
|
G4 |
|
P22 |
|
|
|
|
|
G6 |
|
P23 |
|
|
|
|
|
G6 |
|
P24 |
|
|
|
|
|
G7 |
|
P25 |
|
|
|
|
|
G6 |
|
P26 |
|
|
|
|
|
G7 |
|
P27 |
|
|
|
|
|
G7 |
На шаге 5 правила вывода будут выглядеть следующим образом.
![]()
![]()
![]()
Шаг 6 реализуется одним из известных методов Мамдани, Тагаки-Сугено и др. в совокупности с нейро-нечеткой классификацией группы управляющих решений и нечеткой продукционной модели [3]. При этом модель нечеткой идентификации включает нейро-классификатор, включающий определенное число слоев и совокупность нечетких правил вывода.
Распределение функций по слоям нейро-нечеткого классификатора может быть следующим:
На первом слое выполняется расчет степени принадлежности входных параметров X={x1, …,xN}, второй слой реализует операции Т-нормы (max, min). На следующих слоях нейро-модели включается оценка элементов предыдущего слоя и выделение группы решений. Таким образом обеспечивается выбор предпочтительного решения из соответствующей группы G1, …,G7.
В итоге, алгоритм нечеткого вывода решений реализуется следующими шагами:
Шаг 1. Выбор значений существенных параметров x1, x2, x3. На выходе слоя 1 определяется степень принадлежности (истинности) входных параметров.
Шаг 2. Синтез степеней истинности входных параметров на основе операции T-нормы в слое 2.
Шаг 3. Активизация значений выходов y1, y2 для каждого из 27 правил P на основе результата синтеза значений и функции сигмоидного или треугольного вида в слоях 3 и 4.
В результате реализации шага 3 выделяются предпочтительные группы решений. После реализации полученных решений, в случае необходимости осуществляется обучение (подстройка) созданной нечеткой модели идентификации параметров и поддержки предпочтительного уровня информационной безопасности ЛВС в соответствии с выбранной политикой безопасности.
Литература:
- Круглов В. В., Борисов В. В. Искусственные нейронные сети. Теория и практика. — М., Горячая линия — Телеком, 2001.
- Ухоботов В. И. Введение в теорию нечетких подмножеств и ее применения. Челябинск: УрСЭИ АТ и СО, 2005. – 133 с.
- Тэрано Т. и др. Прикладные нечеткие системы М., Мир, 1993г. — 365 с.
- Sun C.-T. Jang J.-S. A neuro-fuzzy classifier and its applications // Iu Proc. IEEE. Int. Conference on Neural Networks, San Francisco, USA, 1993. — PP.
