





Introduction
- Problem Background
PVA is a not-for-profit organization that provides programs and services for US veterans with spinal cord injuries or disease. With an in-house database of over 13 million donors, PVA is also one of the largest direct mail fund raisers in the country.
The mailing included a gift (or «premium») of personalized name & address labels plus an assortment of 10 note cards and envelopes. All of the donors who received this mailing were acquired by PVA through similar premium-oriented appeals such as this.
One group that is of particular interest to PVA is «Lapsed» donors. These are individuals who made their last donation to PVA 13 to 24 months ago. They represent an important group to PVA, since the longer someone goes without donating, the less likely they will be to give again. Therefore, recapture of these former donors is a critical aspect of PVA's fund raising efforts.
However, PVA has found that there is often an inverse correlation between likelihood to respond and the dollar amount of the gift, so a straight response model (a classification or discrimination task) will most likely net only very low dollar donors. High dollar donors will fall into the lower deciles, which would most likely be suppressed from future mailings. The lost revenue of these suppressed donors would then offset any gains due to the increased response rate of the low dollar donors.
Therefore, to improve the cost-effectiveness of future direct marketing efforts, PVA wishes to develop a model that will help them maximize the net revenue (a regression or estimation task) generated from future renewal mailings to Lapsed donors.
Evaluation rules
The goal of this research is outcome prediction per customer in the database. A marketer will mail to a customer so long as the expected return from an order exceeds the cost invested in generating the order, i.e., the cost of promotion. With package cost (including the mail cost) of $0.68 per piece mailed the measure is: Sum (the actual donation amount — $0.68) over all records for which the expected revenue (or predicted value of the donation) is over $0.68.
Data exploration
- Attribute selection
The dataset contains 479 attributes. The fields TARGET_B and TARGET_D are target attributes and not included in the validation data set.
Basing on the expert decision and correlation matrix were select set of 64 attributes:
- ID & targets: CONTROLN, TARGET_D;
- demographics: ODATEDW, OSOURCE, STATE, ZIP, PVASTATE, DOB, RECINHSE, MDMAUD, DOMAIN, CLUSTER, AGE, HOMEOWNR, CHILD03, CHILD07, CHILD12, CHILD18, NUMCHLD, INCOME, GENDER, WEALTH1, HIT;
- donor interests: COLLECT1, VETERANS, BIBLE, CATLG, HOMEE, PETS, CDPLAY, STEREO, PCOWNERS, PHOTO, CRAFTS, FISHER, GARDENIN, BOATS, WALKER, KIDSTUFF, CARDS, PLATES;
- promotion history: CARDPROM, MAXADATE, NUMPROM, CARDPM12, NUMPRM12;
- summary variables of giving history: RAMNTALL, NGIFTALL, CARDGIFT, MINRAMNT, MAXRAMNT, LASTGIFT, LASTDATE, FISTDATE, TIMELAG, AVGGIFT;
- RFA status: PEPSTRFL, RFA_2F, RFA_2A, MDMAUD_R, MDMAUD_F, MDMAUD_A;
-
others: CLUSTER2, GEOCODE2.
- Data sampling
Records in learning dataset are separated in 2 classes (attribute TARGET_B). The main part of records belongs to class 0 (img. 1), and only 5.1 % (9686 records) to class 1 — responsible donors.
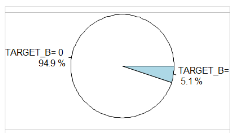
Img. 1. Part of responsible donors in whole dataset
- Data clearing
On the next stage were studied distributions of all selected attributes. For example, attribute HIT contains outliers above 100 (img. 2), which should be corrected to median value.
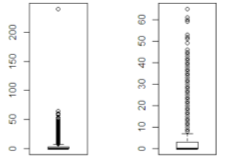
Img. 2. HIT attribute before and after clearing
Illustrations of some other attributes are shown below (img. 3–5) and recommendation for outliers cleaning and exclusion of reduced data are collected in the table 1.
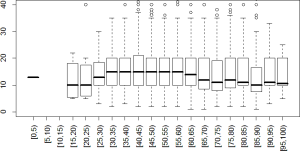
Img. 3.AGE attribute with correlation on TARGET_D
Img. 4. NUMCHLD attribute with correlation on TARGET_D

Img. 5. RFA_2A attribute with correlation on TARGET_D
Table 1
Outliers clearing and empty values filling
|
attribute |
rule |
replacing value |
|
HIT |
HIT > 200 |
mean=3.512 |
|
AGE |
AGE < 15 OR AGE = ' ' |
median=63 |
|
HOMEOWNR |
HOMEOWNR = ' ' |
'U' |
|
NUMCHLD |
NUMCHLD = ' ' |
NULL |
|
INCOME |
INCOME = ' ' |
median=4 |
|
GENDER |
GENDER ('F','M','J') |
'U' |
|
WEALTH1 |
WEALTH1 = ' ' |
median=6 |
|
MINRAMNT |
MINRAMNT > 50 |
median=5 |
|
MAXRAMNT |
MAXRAMNT > 500 |
median=16 |
|
LASTGIFT |
LASTGIFT > 300 |
median=15 |
|
AVGGIFT |
AVGGIFT > 250 |
median=10.88 |
Next attributes were excluded as not representative or low correlation with the target: PVASTATE, DOB, RECINHSE, MDMAUD, CHILD03, CHILD07, MAXADATE, HPHONE_D, MDMAUD_R, MDMAUD_F, MDMAUD_A.
- Model construction
For building of model was selected method «Conditional inference trees» [1]. This method requires to define 4 parameters: MinSplit, MinBusket, MaxSurrogate and MaxDepth. Parameters can be defined by recursive building of trees with different settings and selecting of the best combination of the parameters. Relating to our task was found that this parameters do not give perceptible difference, so were selected those parameters which let to prevent over-fitting:
‒ MinSplit — 1000;
‒ MinBusket — 400;
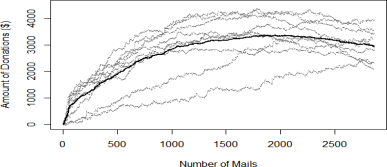
Img. 6. Predicted income for different models. Bold line shows average value
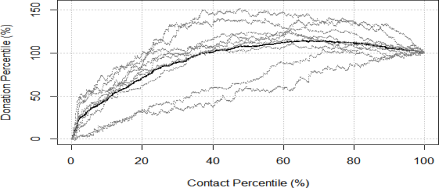
Img. 7. Predicted income in percentile form
‒ MaxSurrogate — 4;
‒ MaxDepth — 10.
Basing on random sampling of training dataset to the learning (70 %) and testing (30 %) parts were constructed 9 model. Img. 6 show predicted income in cumulative sum depending on the count of sent mails. Values sorted in descending order and negotiate cost of mail sending (0.68$).
For better analyze of the models convert diagram from the absolute values to the percentiles (img. 7). As values are sorted in descending order good model should quickly rise on the first part of contacts (big donations). Also, as the most of donation do not outreach the cost of mail sending, model achieve upper limit on 40 % of contacts and begin decreasing. Basing on this reasoning was selected conforming model with the best predicted income.
- Model propagation
Now constructed model can be applied to the validation dataset.
Model was constructed on the training dataset and is very sensitive to the values of nominal (categorical) attributes. So, first of all, it should be checked that new data values conform to the sets of values of training data and replace all inappropriate values with 'NA' (NULL) term.
On the second step the model was used to predict donation values. As was said before the most of donations are not exceed the cost of mailing (0.68$), so the summary income calculated on validating dataset after diminution of the mailing cost is 10560$. But if we limit mailing only to the high responsible donors (with predicted TARGET_D > 0.68), income can compose 12133$.
Effect of this work let increase in net donation on 13 %. Comparing to the results of the KDD-CUP-98 competition (img. 8) our result is between 8 and 9 places.
References:
- Hothorn, T., Hornik, K., Strobl, C., Zeileis, A., 2010. Party: a laboratory for recursive partitioning.
- Yanchang Zhao, 2013. R and Data Mining.
- http://dx.doi.org/10.1016/B978–0-12–396963–7.00001–5
