





В данной работе рассматриваются подходы для классификации новостей с сайта правительства government.ru. Для этого были загружены документы за все года, с момента создания сайта. Так как у каждого документа может быть несколько категорий, то задача классификации является «множественной классификацией меток» (mutilabel calssification). Нами рассмотрены различные методы представления текстовой информации и классификации.
Ключевые слова: машинное обучение, классификация, правительство
Введение
Классификация текстовых документов является классической задачей в машинном обучении. Люди классифицируют объекты для облегчения ежедневных задач: нахождения книги по жанру, новостей по интересующим тематикам, документов по категориям и т. п. Существует несколько вариантов, как могут быть представлены данные перед построением модели: они могут быть размечены экспертом и, зная эти категории, можно построить обучающую модель. В таком случае у каждого документа может быть одна категория (muliclass classification) [1], может быть несколько категорий (mutilabel classification) [1]. Также данные могут не иметь проставленных меток. В таком случае могут быть применены методы кластеризации или тематического моделирования [2]. Документы, представленные на сайте правительства РФ [3] имеют проставленные метки и при этом, один документ может иметь несколько категорий. Поэтому перед нами стоит задача множественной классификации (mutilabel calssification).
Постановка задачи
Дан набор текстовых документов D с проставленными метками Y для каждого из них. Необходимо построить модель α: d’ → ŷ, где d’ — некоторый новый текстовый документ, а ŷ — предсказанный набор категорий.
Анализ данных
Рассмотрим документы, которые представлены на сайте правительства. Каждый документ имеет заголовок, краткое описание и приложенный текстовый файл. Также у него может быть от 1 до 5 категорий. Нами были выгружены документы с 2013 по 2016 года. Всего было получено 4606 документов. С полученным датасетом можно ознакомиться по ссылке [4]. Рассмотрим, сколько документов имеет различное количество категорий на Таблице 1.
Таблица 1
Количество документов иколичество категорий
|
Документы/категории |
1 |
2 |
3 |
4 |
5 |
|
Документы |
4606 |
456 |
24 |
4 |
3 |
В датасете представлены 34 категории, которые имеются в датасете, и сколько раз они встречаются в различных документах. Нами были выбраны категории, которые встречаются больше 100 раз, поскольку раньше этого числа, как правило, категории имеющие слишком локальный характер, например «Оперативный штаб по урегулированию вопросов, связанных с временным приостановлением авиационного сообщения с Арабской Республикой Египет (до 12.12.2015)». Поэтому на Рис. 1 представлено распределение выбранных 24 категорий.
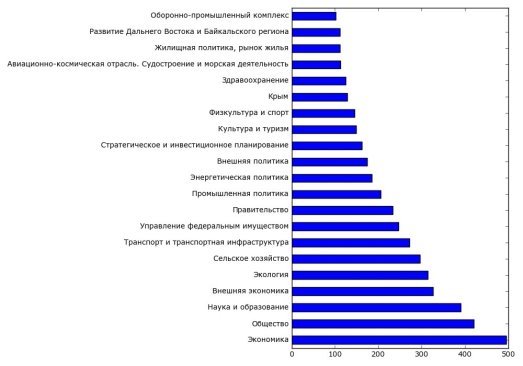
Рис. 1. Распределение категорий
Предобработка текстовой информации
Во-первых, важно исключить все возможные стоп-слова из рассмотрения, вроде «а, ты, мы, они» и т. п. Во-вторых, исключим все слова, частота которых по документам ниже 5 и выше 80 %. В третьих, лемматизируем их с помощью алгоритма snowball из библиотеки nltk [link].
В итоге получим частоты лемм слов по документам. Затем найдем представление слов в виде векторов с помощью технологии word2vec [5] и отдельно нормализуем матрицу частот с помощью инвертированной частоты слов по документам (idf) [6].
Реализацию word2vec возьмем из библиотеки gensim [7], а предобратоку через idf возьмем sklearn [8].
Классификация
Существует несколько подходов для работы с множественными категориями:
- Свести задачу множественной классификации к многоклассовой. Для этого, необходимо для каждой категории документа выделить отдельный документ, продублировав его.
- Построить бинарную матрицу Y из множества категорий размерности [n ⨉ k], где n — количество документов, а k — количество категорий. Соответственно каждый элемент матрицы будет означать наличие категории у документа (значение 1) или отсутствие (значение 0). Используя такую матрицу можно построить множество классификаторов по правилу один против всех (one-vs-rest) [1]. Этот подход предусматривает отсутствие связи между категориями.
- Построить бинарную матрицу по правилу из пункта 2, однако для классификации воспользоваться правилом цепочки (chain rule) [9]. При построении классификатора по такому правилу учитывается то, насколько коррелируют друг с другом категории. В таком случае добавляется информация о том, насколько связаны категории, встречающиеся вместе.
Нами будут применены все три подхода. Для сравнения эффективности алгоритмов воспользуемся стандартными метриками: точностью (precision), полнотой (recall) и F1 мерой [6].
В качестве базового алгоритма классификации, воспользуемся алгоритмом Random Forest.
Реализацию one-vs-rest и Random Forest возьмем из библиотеки sklearn [10]. А правило цепочки из skmultilearn [11].
Результаты
После применения классификаторов к полученным данным, получается картина, представленная в Таблице 2. На ней введены следующие обозначения:
‒ Тип классификатора — по какому правилу был построен классификатор:
- OVR — один против всех;
- CHAIN — по правилу цепочки;
- SINGLE — задача сведена к многоклассовой классификации.
‒ Тип подготовки данных — как были подготовлены текстовые данные:
- TFIDF — нормализованные частоты слов;
- W2V — вектора слов полученные, с помощью word2vec, а для каждого документа суммируем все полученные вектора.
• precision — точность. Определяет, сколько раз был найден релевантный документ среди всех найденных;
• recall — полнота. Определяет, сколько раз был найден релевантный документ среди всех релевантных;
• f1 — среднее гармоническое между двумя величинами.
Таблица 2
Результаты классификации
|
Тип классификатора |
Тип подготовки данных |
precision |
recall |
f1 |
|
OVR |
TFIDF |
0.89 |
0.40 |
0.53 |
|
CHAIN |
TFIDF |
0.90 |
0.38 |
0.51 |
|
OVR |
W2V |
0.83 |
0.22 |
0.33 |
|
CHAIN |
W2V |
0.84 |
0.23 |
0.34 |
|
SINGLE |
TFIDF |
0.61 |
0.61 |
0.60 |
|
SINGLE |
W2V |
0.45 |
0.44 |
0.44 |
Как видно в Таблице 2, самые точные результаты получаются с помощью цепного правила и применением преобразованием текстов с помощью tfidf. При этом, CHAIN уступает OVR по полноте выдаваемых результатов, наиболее полные результаты получаются при сведении задачи к многоклассовой классификации. Также видно, что представление слов в виде векторов не повышает точности классификации.
Выводы
По полученным результатам можно судить, что категории являются независимыми, поскольку точность классификации возрастает, при использовании более продвинутого подхода — цепного правила, однако полнота падает. Также можно сделать такой вывод, поскольку полнота, полученная при многоклассовой классификации, является значительно выше полноты из множественной классификации.
Применение продутых технологий, вроде word2vec также не повышает точности, что может означать, что полученные вектора слов не отражают категории слов.
Заключение
По полученным данным, получается, что если требуется получить наиболее точные результаты классификации документов, то лучше всего справляется представление слов через tfidf и построение классификатора с помощью цепного правила. Если требуется получать как можно более разнообразные категории, то лучше всего с этой задачей справляется сведение задачи множественной классификации к многоклассовой.
Литература:
- Многоклассовая и множественная классификации на sklearn [Интерент ресурс]: http://scikit-learn.org/stable/modules/multiclass.html (дата обращения: 29.05.2017)
- Document Clustering with Python [Интерент ресурс]: http://brandonrose.org/clustering (дата обращения: 29.05.2017)
- Сайт правительства РФ [Интернет ресурс]: http://government.ru (дата обращения: 29.05.2017)
- Выгруженные данные с http://government.ru и обувная word2vec модель [Интернет ресурс]: https://yadi.sk/d/dOGUKF9R3Hs9WT (дата обращения: 29.05.2017)
- Mikolov, T., Sutskever, I., Chen, K., Greg S. C., Dean, J. Distributed Representations of Words
- Manning C.\:D., Raghavan P. and Schutze H. Introduction to Information Retrieval // Cambridge University Press 2008.
- Radim R., Sojka P. Software Framework for Topic Modelling with Large Corpora // Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. Valletta, Malta: ELRA, 2010. С. 45–50.
- TfidfVectorizer [Интернет ресурс]: http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html#sklearn.feature_extraction.text.TfidfVectorizer (дата обращения: 29.05.2017)
- Read, J., Pfahringer, B., Holmes, G. et al. Mach Learn (2011) 85: 333.
- Random Forest classifier [Интерент ресурс]: http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html (дата обращения: 29.05.2017)
- Szyma P., Kajdanowicz, T. A scikit-based Python environment for performing multi-label classification // ArXiv e-prints. 2017.
