





Используя базу данных матчей с 2003 по 2016 гг. разработана модель оценивания результатов будущих матчей, протестирована на матчах 2016 года и сравнена с результатами аналогичных работ.
Ключевые слова: machine learning, xgboost, random forest, нейронные сети
В базе данных имеется записи о 80 000 теннисных матчах и их различные характеристики (50 категорий). Они были разделены на 3 категории:
‒ основные характеристики игрока;
‒ дополнительные характеристики игрока (имеются пропуски в базе данных);
‒ характеристики матча.
|
Основные характеристики игрока |
Дополнительные характеристики игрока |
Характеристики матча |
|
Количество успешных подач |
Количество невынужденных ошибок |
Счет матча |
|
Количество эйсов |
Максимальная скорость подачи |
Тип корта |
|
Количество двойных ошибок… |
Количество выходов к сетке... |
Тип турнира… |
Перед построением модели введем определение задачи классификации.
Задача классификации: Имеется ![]() наблюдений (матчей)
наблюдений (матчей) ![]() , каждое из которых является вектором размера
, каждое из которых является вектором размера ![]() (количество характеристик):
(количество характеристик):
![]()
и вектор результатов
Каждому наблюдению ![]() соответствует результат
соответствует результат ![]() . Предполагается, что в векторе наблюдений
. Предполагается, что в векторе наблюдений ![]() не содержится информации, доступной после начала матча.
не содержится информации, доступной после начала матча.
![]()
После определения задачи, необходимо построить алгоритм ![]() , который оценивает вероятность победы
, который оценивает вероятность победы ![]() первого игрока из пары
первого игрока из пары ![]() над вторым игроком. Результатом работы алгоритма является вектор
над вторым игроком. Результатом работы алгоритма является вектор ![]() . Для оценки качества алгоритма используется логарифмическая функция потерь. Чем меньше значение функции потерь, тем точнее алгоритм.
. Для оценки качества алгоритма используется логарифмическая функция потерь. Чем меньше значение функции потерь, тем точнее алгоритм.
Определение 1. Логарифмическая функция потерь (logloss):
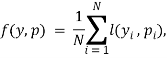
где ![]() — результат матча,
— результат матча, ![]() — вероятность победы первого игрока, вычисленная алгоритмом
— вероятность победы первого игрока, вычисленная алгоритмом ![]() .
.
Первым этапом всоздании модели будет модификации имеющийся базы данных, который разбит на 4 части:
- Исключение характеристик матчей, полученных после их начала.
- Добавление основных усредненных характеристик игроков за различные периоды.
- Включение в базу новых характеристик (стиль, усталость) и пропущенных значений дополнительных характеристик игроков. Используются методы машинного обучения.
- Добавление в базу дополнительных усредненных характеристик игроков за различные периоды.
Для построения усредненных характеристик использовались различные типы весов:
-
Вес по времени:
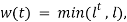 где
где 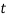 — временной интервал между датой матча и моментом анализа (в годах),
— временной интервал между датой матча и моментом анализа (в годах), 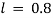 (значение взято из работы [5]).
(значение взято из работы [5]).
-
Вес покрытия корта: — используется коэффициент корреляции между процентами победам на кортах
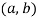 для всех игроков:
для всех игроков:
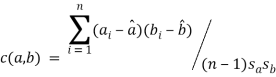
‒ ![]() — процент побед игрока
— процент побед игрока![]() на покрытии
на покрытии ![]() ,
,
‒
‒ ![]() — стандартное отклонение в проценте побед на покрытии
— стандартное отклонение в проценте побед на покрытии ![]()
‒ ![]() — средний процент побед на покрытии
— средний процент побед на покрытии ![]()
‒ ![]() — средний процент побед на покрытии
— средний процент побед на покрытии ![]()
‒ ![]() — количество игроков.
— количество игроков.
После определения весов мы можем посчитать усредненную характеристику ℎ для игрока p, временного интервала t и вектора значений характеристик ![]() по формуле
по формуле
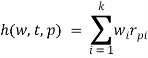 ,
,
где ![]() — вес матча i. Значение
— вес матча i. Значение ![]() равняется трем месяцем, шести месяцем, одному или двум годам. Вес равен единице. Также параметр
равняется трем месяцем, шести месяцем, одному или двум годам. Вес равен единице. Также параметр ![]() может не использоваться, тогда мы будем рассматривать все матчи игрока
может не использоваться, тогда мы будем рассматривать все матчи игрока ![]() за его карьеру. В этом случае веса равны единице, произведению веса покрытия и веса по времени.
за его карьеру. В этом случае веса равны единице, произведению веса покрытия и веса по времени.
Подсчитаем усталость игрока по формуле из работы [9]. В расчёт идут матчи, сыгранные за прошедшие 3 дня. Усталость для каждого игрока равна ![]() , где t — количество дней? прошедших с матча, g — количество геймов в матче.
, где t — количество дней? прошедших с матча, g — количество геймов в матче.
Также, для каждого теннисиста, был определен один из 8 видов стилей игры.
В итоге получена новая база данных, состоящая их усредненных характеристик игроков, характеристик матча, и новых характеристик.
Вторым этапом было применение алгоритмов машинного обучения к новой базе данных.
Для создания модели использовалось 3 метода машинного обучения:
- Gradient Boosting — алгоритм [2] состоит из комплекса простых алгоритмов и последовательно выполняет их так, чтобы каждый следующий улучшал качество всего комплекса. Использовалась реализация из библиотеки XGBoost.
- Random forest — алгоритм [1] также состоит из комплекса простых алгоритмов, но они строятся независимо друг от друга. Использовалась реализация из библиотеки Scikit-learn.
- Neural network — нейронная сеть [3] представляет систему соединённых и взаимодействующих между собой искусственных нейронов. Использовалась реализация из библиотеки Keras.
При использовании алгоритмов машинного обучения часто проявляется эффект переобучения, при котором ошибка обученного алгоритма, на тестовой выборке, получается существенно выше, чем ошибка на обучающей выборке. Поэтому, при обучении алгоритмов, нужно из обучающей выборки взять набор данных для проверки (валидации). Для обучения мы разбиваем наш временной интервал на 3 части:
- Обучение алгоритмов проводится на данных с 2003 по 2014 гг,
- Валидация алгоритмов проводится на данных 2015 г,
- Тестовый набор взят на данных 2016. На этом наборе мы протестируем итоговую модель.
Характеристика программы.
Программа написана на языке Python 3.5. Для работы с базой данной использовались библиотеки Pandas и Numpy.
Схема работы программы:
1. Первичная загрузка базы данных.
2. Первичная обработка базы данных для создания модели. Этот процесс занимает около 16 часов.
3. Обновление базы данных и добавление оценок для новых матчей. Оно занимает около 5 минут.
Результаты тестирования.
Модель была протестирована на выборке из 1030 матчей.
|
Алгоритм |
Значение logloss |
|
Модель M.Sipko [4] |
0.6111 |
|
Gradient Boosting 1 |
0.5738 |
|
Gradient Boosting 2 |
0.5726 |
|
Gradient Boosting 3 |
0.5754 |
|
Random forest 1 |
0.5826 |
|
Neural network 1 |
0.5836 |
|
Neural network 2 |
0.5837 |
|
Усреднение всех моделей |
0.5691 |
По критерию logloss, полученная модель лучше модели M.Sipko на 6.9 %.
Литература:
- Biau G. and Scornet E. A Random Forest Guided Tour // Sorbonne University, 2015.
- Chen T. and Guestrin C. XGBoost: A Scalable Tree Boosting System // University of Washington, 2016.
- Gurney K. An introduction to neural networks // University of Sheffield, 1997.
- Sipko M. Machine Learning for the Prediction of Professional Tennis Matches. // Imperial College London. Final year project, 2015.
