





Text detection has gotten a great attention as highly active application-oriented research area in computer vision, artificial intelligence, and image processing.
In this article, we implement the algorithm for text logo detection in images with a complex background by using a contour information of images.
To understand how effective an algorithm of enhancement is, the quality of the processed images is evaluated. Firstly we use pre-treatment algorithms, then make formation of a contour representation. Secondly follows suppression of unnecessary boundaries, the formation of a binary mask and the application of morphological processing. Final steps are suppression of minor areas and formation of text zones.
Finally, we evaluated results in three categories: accuracy of detection, localization accuracy and false positives.
Key words: Text Detection, Image Processing, Localization, Text Logo Detection, Computer Science.
Introduction
Recently there are situations when sponsors need to check whether their logos (advertising of their product or product) appeared in the intended place. So when analyzing broadcasts on different telegraphs, data is used not only about trademarks, but also logos of TV channels, which allows to find out at what time and where the advertising of the goods was broadcast. Similar tasks are also put on the Internet in front of organizations that monitor content. For example, for sampling graphic material on which the logo of a certain company is present. In practice, the process of searching for such information is time-consuming and requires a considerable amount of time.
At the moment, there are many different approaches to the implementation of logo detection systems on images, ranging from various variations on the topic of comparing the resulting image with a template image, to the construction of complex 3D models. But, unfortunately, there are no effective methods for detecting objects, including text logos, without complicated systems.
Related works
The purpose of detection and localization is to determine the presence of an object on the image and to find its position in the coordinate system of the pixels of the original image. The position of the object, depending on the choice of the detection algorithm, can be determined by the coordinates of the rectangle bordering the object, either by the outline of this object, or by the coordinates of the points most characteristic for the object.
Known are the following approaches to detecting text logos on images:
1) Based on the use of contour information (each symbol has a clearly expressed contour structure). For the localization of the text, the following methods are used here: skeletonization [6], edge detection and corner detection [7], methods based on invariant methods [8], etc. In the case Images with a complex background, fast processing of data obtained during the preprocessing phase can be a non-trivial task [1].
2) Based on the color information (the target text areas have uniform colors / intensity and satisfy the size and shape constraints); The most popular tools are the histogram method [9], the analysis of the main components (connected component analysis) [10] and various adaptive binarization algorithms — including the algorithms Niblack, Sauvola, Chistian, Bernsan, Otsu, etc. [7]. The methods allow working with arbitrary font sizes and arbitrary text orientation, however they do not work well on images with a complex background that have noise and blurriness, and also use a large number of heuristics.
3) Based on the analysis of textural information (text zones can significantly differ from the background, which allows using different frequency filters for the «pyramid» of images); To identify the necessary zones can be used as classical methods of pattern recognition — the method of support vectors (support vector machines), artificial neural networks (neural networks) [3], expert systems (expert systems), etc., and special, for example, the method of spectrographic Textures.
All logos are designed in such a way that they can be easily read and, accordingly, they differ from the background, and therefore have a pronounced contour structure and special color characteristics. In this regard, it was decided to use technology based on the search for contours.
To effectively develop the system, it is necessary to consider methods for detecting and localizing text logos based on the outline representation.
Detecting logos based on contour information of images
Detection and localization of text logos on images occurs step by step [3]:
1) Pre-treatment.
2) Formation of a contour representation.
3) Suppression of unnecessary boundaries, the formation of a binary mask, the application of morphological processing.
4) Suppression of minor areas.
5) Formation of text zones.
Consider the most significant stages of detecting text logos on the image:
Image pre-processing
The detection of textual information on images is affected by the quality of the original image. So in the image in the case of getting it through various capture devices (scanner, camera, camera, etc.), various kinds of noise can appear, which can introduce visual distortions in the field of logos. To suppress noise in images, spatial filters are used that produce pixel processing with respect to some local neighborhood. So the most widely known are the median filter and the Gaussian filter [7].
The median filter is most effective in the case where, the noise in the image has an impulsive character. When implementing this filter, a two-dimensional window is used, which usually has a central symmetry, and its center is located at the current filtering point.
To understand the working principle of the median filter, we designate the working sample as a one-dimensional array; The number of its elements is equal to the size of the window, and their arrangement is arbitrary. Usually, windows with an odd number of points n are used (this is automatically provided for the central symmetry of the aperture and for the entry of the central point into its composition). When ordering a sequence, for example in ascending order, its median will be that selection element that occupies a central position in this ordered sequence. The number so obtained is the result of filtering for the current frame point. The formal designation of the procedure for applying the filter can be represented in the form:
![]() ,
,
where med is the designation of the median value calculation function.
Median filtering has its drawbacks [5]. So the authors of the article, experimentally found that this method has a relatively weak efficiency in filtering the so-called fluctuation noise. In addition, when the size of the mask is increased, the contours of the image blur and, as a consequence, reduce the clarity of the image.
A Gaussian filter is an image blur filter that uses a normal distribution to calculate the transformation applied to each pixel of the original image [9]. The Gaussian distribution equation in the one-dimensional implementation has the following form:
![]()
or, in a particular case, for a two-dimensional implementation:
![]() ,
,
where![]() is the distance from the origin to the horizontal axis;
is the distance from the origin to the horizontal axis;
![]() is the distance from the origin to the horizontal axis;
is the distance from the origin to the horizontal axis;
![]() is the standard deviation of the Gaussian distribution.
is the standard deviation of the Gaussian distribution.
In the case of two dimensions, this formula specifies surfaces that look like concentric circles with a Gauss distribution from the central point. Pixels, where the distribution is different from zero, are used to construct a convolution matrix that is applied to the original image [8]. The value of each pixel becomes a weighted average for the neighborhood. The original pixel value assumes the greatest weight, and the neighboring pixels take on smaller weights, depending on the distance to them. In theory, the distribution at each point of the image will be non-zero, which would require calculating the weighting coefficients for each pixel in the image.
Formation of a contour representation
Algorithms for forming a contour representation are applied after preliminary image processing. There are a lot of different methods, among which I highlight methods based on gradients (derivative) and second derivative. Gradient methods are based on the principle that different objects in the images correspond to regions with more or less identical values of brightness [4]. At the borders, the brightness changes significantly. So the magnitude or modulus of the gradient vector determines the «strength» of the boundary, i.e. How much the boundaries of the object and its surroundings differ at a given point of the border. To form a contour representation, you can use gradient methods such as Roberts, Sobel and Previtt. The computation in these methods is based on performing convolution of the image by small integer filters (operators). In general, the calculation of the response, pixel values of the contour representation, for these methods is carried out using the formula [2]:
![]()
The Roberts method is the simplest and fastest. He works with a two-dimensional aperture two by two, which can be represented as follows [10]:
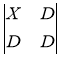 ,
,
where X — processed pixel;
D — neighboring pixels.
Operators Roberts can be represented as follows:
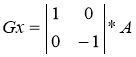 ,
, 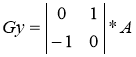 .
.
The methods of forming contour representations using Sobel and Previt operators work with a larger aperture — a three by three aperture. These operators use the intensity values in a single neighborhood, the processed pixel to calculate the approximation of the corresponding image gradient [5]. In general, the aperture for the Sobel and Previt methods looks as follows:
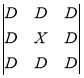 ,
,
where X — processed pixel;
D — neighboring pixels.
When forming the contour representation can be used as operators oriented direction corresponding Cartesian coordinate system, and using the diagonal directions. Operators Sobel in different combinations have the following form [1]:
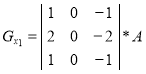 ,
, 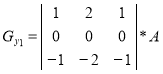 ,
,
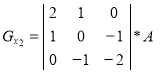 ,
, 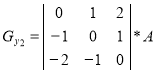 .
.
To drastically reduce the amount of information contained in the image, it is necessary to apply binarization algorithms.
Binarization with upper threshold
The operation of threshold separation, which results in a binary image, is called binarization. In the binarization process, the original halftone image having a certain number of brightness levels is converted to a black and white image whose pixels have only two values — 0 and 1 [3].
Binarization with an upper threshold is calculated by the formula:
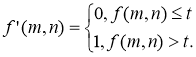
Incomplete Threshold Processing
This transformation gives an image that can be easier for further analysis, as it becomes devoid of background with all the details present on the source image:
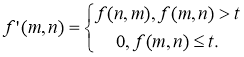
To extract some properties of the image, useful for its presentation and description, it is necessary to perform post-processing of images. For example, contours, convex shells.
Postprocessing images
Dilatation (morphological extension) — convolution of the image or selected area of the image with some nucleus. The kernel can have an arbitrary shape and size. In this case, a single leading position (anchor) is allocated in the core, which is combined with the current pixel in the computation of the convolution. In many cases, a square or a circle with a leading position in the center is chosen as the core [5].
Erosion (morphological narrowing) is the inverse dilatation operation. The effect of erosion is similar to dilatation, the only difference is that the local minimum search operator is used.
Suppression of minor areas
Thus, to remove a minor zone, the main rule is a discrepancy to the minimum dimensions, as the additional rules can be the ratio of the width / height ratio, the determination of the distribution density within the text area area or the distribution density, taking into account the block weight.As typical test criteria, the following can be distinguished:
‒ small height (eg less than 12);
‒ small width (for example, less than 6);
‒ height is too high (for example, more than 64);
‒ inconsistency of the proportion of the width / height ratio (for example, for a text block of two symbols, the proportion ratio is less than 1.3).
Experiments
In each category, there were about thirty different images with different arrangement of logos. Based on the results of processing, the system showed the best result when working with images of the third category in three parameters, namely:
accuracy of detection is a value that reflects the number of images in which the areas containing the logo have been correctly identified;
localization accuracy is a value that characterizes the accuracy of the logo's highlighting, that is, matching the area of the logo identified by the algorithm with the area indicated by the expert;
false positives is a value that indicates the percentage of incorrectly defined areas, more precisely the areas that have been highlighted as areas with a logo, but do not contain a logo. The pipeline of method demonstrated in Fig1.

Fig. 1
The results of image of the comparative analysis is shown in Fig. 2.
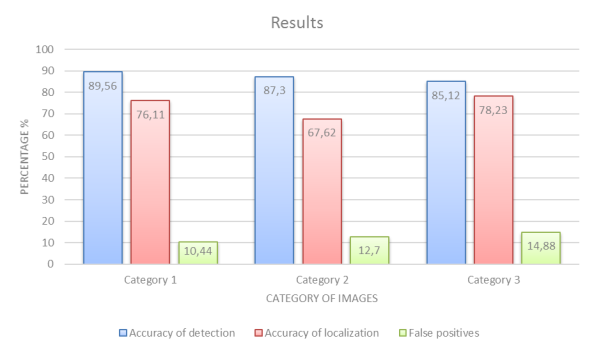
Fig 2. Results of experiments
Conclusion
Summing up, we can say that the methods considered are most simple in terms of programming, but they do not give very high accuracy. So, for example, without using preliminary processing and additional checks at high quality of the original the accuracy of localization can be about 97 %. In this case, in the case of images of not high quality localization accuracy will be in the area 70 %. The proposed ways to improve the accuracy of detecting text symbols depending on the conditions of their use can improve the accuracy the method works by 10–40 % and reduce false detection by 20–40 %.
References:
- Meshram S A, Malviya A V. Traffic surveillance by counting and classification of vehicles from video using image processing. International Journal of Advance Research in Computer Science and Management Studies, 1(6), November 2013.
- Rybalka R, Honcharov K. Method for pre-processing of level crossing image. Transport problems, 10(1), 2015.
- Xu X, Liu W, Li L. Low resolution face recognition in surveillance systems. Journal of Computer and Communications, 2, 2014.
- Jerian M, Paolino S et al. A forensic image processing environment for investigation of surveillance video. Forensic Science International, 167, 2007.
- Asirvadam V J, Altahir A A, Sebastian P. Event triggering with crisp set using images of surveillance systems. IJVIPNS-IJENS, 10(02), 2010.
- Fralenko V P. Analysis of spectrographic textures of Earth remote sensing data. Artificial intelligence and decision making, 2010.
- Sivakumar, Dr. K Thangavel, P Saravanan. Computed Radiography Skull Image Enhancement using Weiner Filter. IEEE, ID:978–1-4673–10390/12, June 2012.
- Xu C., Wang J., Wan K., Li Y., and Duan L., Live sports event detection based on broadcast video and web-casting text // Proc. ACM Multimedia, 2006, pp. 221–230 http://dx.doi.org/10.1145/1180639.1180699
- Ćalić J., Campbell N., Mirmehdi M., Thomas B., Laborde R., Porter S., Canagarajah N. ICBR — Multimedia management system for Intelligent Content Based Retrieval // Lecture Notes in Computer Science, 2004, vol 3115, pp. 601–609 http://sal.cs.bris.ac.uk/Publications/Papers/2000116.pdf
- Küçük D., Yazıcı A. A semi-automatic text-based semantic video annotation system for Turkish facilitating multilingual retrieval // Expert Systems with Applications (2013) http://dx.doi.org/10.1016/j.eswa.2012.12.048
