





В статье рассматриваются такие понятия, как хранилище данных и база данных. Проводится сравнительный анализ рассматриваемых технологий, их назначение и ключевые отличия в промышленной эксплуатации. Также представлен краткий обзор современных решений от крупнейших мировых компаний-производителей, предлагающих системы для создания и развития промышленных хранилищ и баз данных.
Ключевые слова: база данных, хранилище данных, БД, ХД, СУБД, DWH, OLTP, OLAP, информационная система, анализ, фронт-офис, бизнес-приложение, ПО, ИС, ИТ.
Введение
С бурным развитием информационных систем и оснащением бизнеса и государственных структур средствами вычислительной техники, которое началось несколько десятилетий назад, активно развиваются технологии сбора и хранения больших массивов различного рода деловой и служебной информации. Средства, позволяющие создавать решения для накопления и управления большими объемами данных, называются системами управления базами данных. Наряду с базами данных существует и такой класс информационных систем, как хранилище данных, которое также предназначено для хранения и обработки больших массивов данных. В основном базы данных и хранилища данных используются в корпоративных системах, предназначенных для хранения и обработки информации, которые обслуживают бухгалтерию, информационные архивы, телефонные сети, регистрацию документов, банковские операции и т. д. На сегодняшний день многообразие подобных решений постоянно растет и без них уже невозможно представить ни одну промышленную информационную систему. Между тем базы данных и хранилища данных имеют ключевые различия, свои особенности и назначение, которым посвящена данная статья.
Понятия база данных и хранилище данных
Когда возникает потребность хранить и обрабатывать большие объемы данных, как правило, в промышленных масштабах, встает вопрос о том, как эффективно организовать эти процессы? Каким образом и где хранить данные, чтобы их легко можно было записывать, изменять, удалять? Не стоит забывать и о масштабируемости, чтобы в будущем, когда потребности предприятия вырастут, не пришлось нести большие дополнительные расходы, или вовсе отказываться от текущего решения в пользу нового.
При накоплении больших объемов данных, необходимо задуматься об архитектуре решения, учитывая потребности предприятия. Данные, объединенные по каким-либо признакам, правилам и имеющие определенную структуру — это и есть база данных (БД). Потребности в БД возникают тогда, когда необходимо организовать значительный по объему набор каких-либо данных (от десятков, сотен мегабайт и больше), изменять их и использовать.
Чтобы лучше понять суть и особенности БД, хотелось бы остановиться на их назначении. Основные функции БД, это возможность оперативно сохранить новые данные, быстро найти существующую запись, изменить и сохранить или удалить ее. Но также часто возникают потребности выбрать значительные объемы данных, преобразовать их для дальнейших исследований и анализа. Поскольку классические БД проектируются для оперативной работы одновременно с относительно небольшими объемами данных, для выполнения такой задачи необходима другая архитектура и организация данных. Именно для этого и существуют хранилища данных (ХД). Автор концепции ХД — Ralph Kimball описывал ХД, как «место, где люди могут получить доступ к своим данным». Более подробное определение ХД можно сформулировать следующим образом. ХД — это предметно-ориентированный, привязанный ко времени, не корректируемый, интегрированный, набор данных, собранный из других систем, для представления информации пользователям, статистического и бизнес-анализа, отчетов и для принятия стратегических и тактических решении в организации. Понятие «предметно-ориентированный» означает, что данные объединяются в категории и хранятся в соответствии с областями, которые они описывают, а не с приложениями, которые они используют. Понятие «интегрированный» означает, что данные объединены так, чтобы они удовлетворяли всем требованиям предприятия в целом, а не единственной функции бизнеса.
Рассмотрим свойства, основные характеристики БД и ХД, а также их назначение и различия.
Сравнительный анализ БД и ХД
Современные БД, как упоминалось выше, должны оперативно обрабатывать небольшие объемы данных и ключевым фактором является скорость обработки. Такие оперативные промышленные БД обрабатывают большой поток записей относительно небольшого размера. Подобного рода системы называются транзакционными или OLTP-системы (Online Transaction Processing) — системы обработки транзакций в реальном времени, когда небольшие по размерам транзакции идут большим потоком. Источником таких записей или инициатором запроса к системе могут быть, к примеру, операторы фронт-офисной системы или клиенты, проводящие операции через терминальные устройства.
Для ХД источниками, как правило, являются другие системы, в том числе OLTP-системы (см. Рис.1). «Сырые» данные собираются из не интегрированных, оперативных и унаследованных систем, очищаются от ошибок, агрегируются и загружаются в хранилища, например, для построения моделей (рисковых, скоринговых), для подготовки отчетности или передачи данных в другие системы. В ХД данные представляются в понятном бизнес-пользователям виде. Такие системы относятся к типу OLAP (Online analytical processing). OLAP — это технология комплексного многомерного анализа данных, назначение которой предоставить пользователям понятный и простой доступ к данным.
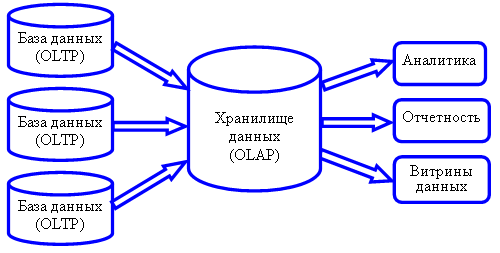
Рис. 1. Источники и потребители ХД
Может возникнуть вопрос: Почему нельзя использовать традиционные БД для тех же целей, что и ХД, т. е. для анализа данных и принятия решений? На самом деле можно использовать. Но ХД специально предназначено для поддержки принятия решений, а значит гораздо больше подходит для этих целей, чем БД. Т. е. требования к хранящейся информации в ХД и в БД имеют принципиальные отличия.
Рассмотрим подробнее требования к ХД и БД.
БД содержат огромное количество информации, не нужной для анализа. ХД должно быть предметно-ориентированным, т. е. загружать в него следует не все подряд, а максимально сокращенный спектр выбираемой информации, и использовать только те данные, которые необходимы для решения поставленной задачи.
ХД должно быть интегрированным. Из-за большого количества различных источников, одни и те же данные, показатели могут храниться по-разному и иметь различные форматы и значения. Подобные несоответствия должны устраняться программными средствами автоматически. Данные должны быть обработаны и унифицированы таким образом, чтобы удовлетворять требованиям всего предприятия. Это может быть одной из самых трудоемких задач при проектировании ХД.
Для ХД должна быть обеспечена высокая скорость извлечения большого объема данных. Оно должно представлять собой среду, оптимизированную таким образом, чтобы максимально быстро получать готовые срезы или массивы данных из очень больших объемов, при этом выполняя сложные, произвольные, не стандартизованные запросы, индивидуальные для каждой организации, отдела или даже аналитика. Для этого необходимо отказаться от главного принципа — нормализации, т. е. от дробления таблиц на мельчайшие элементы с тем, чтобы каждое значение встречалось в ХД только один раз. Таким образом, ХД — денормализовано, и одно и то же значение можно встретить как в детализированном виде, так и в агрегированном виде. В отличие от нормализованной БД, для которой принципиально важно оперативно выбирать лишь небольшие по объему порции данных, используя стандартизованные запросы.
В ХД необходима поддержка внутренней непротиворечивости данных. Это требование следует из предыдущих пунктов, т. к. обилие источников данных и денормализованная структура могут угрожать непротиворечивости внутри ХД, а этого допускать нельзя. Для обеспечения непротиворечивости данных существуют специальные механизмы. В БД их использование не требуются, т. к. непротиворечивость данных обеспечивается нормализацией.
В оперативных БД данные обрабатываются за относительно небольшой период времени, например, 1 месяц, и поддержка историчности не предусмотрена. Остальные данные, как правило, архивируются, переносятся на другой сервер и в дальнейшем не используются для расчетов. В ХД поддерживается привязка ко времени. Данные никогда не удаляются, а сохраняются в течение 5–7 и более лет. Это необходимо для построения закономерностей и прогнозов.
Как отмечалось ранее, в БД данные изменяются, а в ХД — нет. В случае изменения объекта/показателя, появляется дополнительная запись. Для каждого момента времени существует актуальная версия записи объекта/показателя. Данные не модифицируются, т. к. это может привезти к нарушению их целостности. Это требование также называется — неразрушаемая целостность данных, полнота и достоверность.
Подводя итоги сравнительного анализа, рассмотрим различия между БД и ХД. Кратко различия приведены ниже в Таблица 1.
- Детализация. БД предназначены, прежде всего, для быстрого извлечения одной записи, обработки и отправки для дальнейшего расчета. Поэтому данные детализированы. ХД предназначены для принятия стратегических решений, прогнозирования. Для этого необходимы агрегированные, обобщенные данные. Поэтому результаты агрегации из разных источников БД хранятся уже в готовом виде.
- Обновление. БД отражают состояние на текущий момент времени и могут изменяться в любой момент времени. В ХД интервалы загрузки и обновления данных регламентированы. Например, ежесуточно или несколько раз в сутки.
- Зависимость от времени. В БД нет зависимости от времени. Данные актуальны на текущий момент времени. В ХД обеспечивается поддержка историчности. Например, для возможности построения модели в зависимости от времени. Не только на конкретную дату, но и за период.
- Корректировка. Это свойство является следствием предыдущего. В БД запись изменяется, а предыдущее значение не сохраняется. В ХД запись не может быть изменена, а создается новая версия записи с актуальными значениями.
- Обработка. В БД, как уже упоминалось, обрабатывается одна запись за один запрос. В ХД выполняется работа с множеством записей. Составляются сложные запросы для построения моделей, нахождения закономерностей.
- Ориентированность. БД ориентированы на приложение, какую-то конкретную область. Архитектура ХД ориентирована на анализ и принятие решений, и все подчинено этим аспектам без привязки к какой-либо конкретной области.
- Избыточность. Основной принцип построения БД — нормализация и не избыточность. Любой показатель информации должен храниться в единственном экземпляре. Не должно быть дублирования, противоречий. В ХД данные избыточны. Т. е. одни и те же показатели/объекты могут храниться несколько раз, причем в разном виде. В разных представлениях, степенях детализации, агрегации и т. д. В данном случае свойством не избыточности пожертвовали ради скорости сбора и анализа.
Таблица 1
Различия между базами и хранилищами данных
|
№ |
Данные в БД |
Данные в ХД |
|
1 |
Детализированы |
Обобщены, агрегированы |
|
2 |
Обновляются произвольно |
Обновление регламентировано |
|
3 |
Точны в момент обращения |
Зависимы от времени |
|
4 |
Корректируются |
Не корректируются. |
|
5 |
Обрабатывается одна запись |
Обрабатывается массив |
|
6 |
Ориентированы на приложения |
Ориентированы на анализ |
|
7 |
Не избыточны |
Избыточны |
Крупнейшие мировые производители программного обеспечения для СУБД и ХД
На сегодняшний день можно выделить несколько широко известных компаний, чьи решения в области СУБД и ХД занимают лидирующие позиции и используются по всему миру. Крупнейшими среди них являются:
- Oracle
- Microsoft
- IBM
- Teradata
Остановимся на каждом из них и кратко рассмотрим плюсы и минусы предлагаемых на сегодняшний день решений.
У компании Oracle лидирующие позиции в области СУБД, которой принадлежит около 30 % мирового рынка. А на российском рынке компании принадлежит более 60 % рынка. Поддержка Oracle всех возможных вариантов архитектур, в том числе кластеров, симметричных многопроцессорных систем и свыше 80 вариантов операционной среды, включая мэйнфреймы IBM, мини-компьютеры DEC VAX, UNIX, Windows и множество других платформ — являются одними из важнейших характеристик. Их значимость очевидна для крупномасштабных организаций, где множество компьютеров различных моделей. Oracle предлагает решения от начального уровня, до высокопроизводительных систем, масштабируемых и безопасных, что также является критичным для бизнес-приложений. Среди плюсов Oracle также поддержка совместимости со старыми решениями (три четверти клиентов Oracle работают с Oracle Database более 10 лет) и высокие показатели удовлетворенности продуктами. К минусам Oracle можно отнести высокую стоимость и сложность лицензирования, а также проблемы, связанные с выпуском обновлений. При разработке ХД Oracle предлагает широкий спектр продуктов, от использования сертифицированной конфигурации до устройства, готового к настройке ХД и нагрузке. Также предлагаются фирменные решения Exadata: Oracle Exadata X2–2 для ХД и смешанных рабочих нагрузок, Oracle Exadata X2–8 для облачных решений и Oracle Exadata Storage Expansion Rack X2–2 для увеличения ёмкости ХД. Oracle сообщает о наличии более 300 тыс. клиентов по всему миру.
Компания Microsoft занимает прочные позиции на рынке CУБД, предлагая такие решения, как SQL Server DBMS и облачный сервис Azure SQL DATABASE. Компания получила самую высокую оценку от клиентов за удовлетворение потребностей заказчиков, соотношение цены и качества, обслуживание, поддержку и общий опыт. Также конкурентоспособность Microsoft повысила, запустив бесплатные инструменты Developer Edition of SQL Server и Database Migration Service для миграции баз данных SQL Server и Oracle в среду Azure SQL Database. Продукт SQL Server используется для работы с небольшими и средними по размеру БД, а также для крупных БД масштаба предприятия. Но, несмотря на сильные стороны, многие корпоративные заказчики по-прежнему не считают эту СУБД подходящей для критически важных приложений. По опыту использования стоит отметить, что если количество пользователей превышает 2000, то требуется переходить на СУБД более высокого уровня, например, от компании Oracle. На рынке ХД Microsoft предлагает свои решения SQL Server 2008 DBMS (Release 2) Business Data Warehouse и Fast Track Data Warehouse для обеспечения ХД клиентов, которым не требуется СУБД массово-параллельной архитектуры. Microsoft выпустила собственное устройство ХД массово-параллельной архитектуры — SQL Server 2008 R2 Parallel Data Warehouse (Microsoft) в ноябре 2010 года.
Корпорация IBM предлагает, как автономные решения СУБД, так и устройства для ХД. В настоящее время на рынке представлено семейство IBM Smart Analytics System (ISAS), ПО для ХД IBM — InfoSphere Warehouse доступно для Unix, Linux, Windows и z/OS. IBM имеет тысячи клиентов баз данных по всему миру. Стоит отметить богатую функциональность решений, в том числе облачные и гибридные возможности, которыми обладают продукты компании, а также активное использование популярных решений с открытым исходным кодом (Hadoop, Kafka, Parquet,Spark и др.) и функций резервного копирования и восстановления данных в/из Swift и AWS S3. Однако, выручка и доля IBM на рынке операционных СУБД сокращается уже несколько лет. СУБД DB2 проигрывает большинству конкурентов по скорости обработки транзакций и загрузки данных. Также существуют трудности с ценообразованием и лицензированием.
Компания Teradata существует более 30 лет на рынке ХД в сочетании с подготовленным оборудованием и специализированным ПО БД аналитики. Teradata имеет более 1 тыс. организаций-заказчиков по всему миру. Продукты Teradata включают решения для интеллектуального анализа данных, ведомственные решения, ориентированные на поиск данных и корпоративные решения, а также облачные решения и продукты для работы с большими данными. Aster Data добавила новые возможности в линейку продуктов Teradata (такие как MapReduce, неструктурированные данные и графический анализ).
Заключение
На сегодняшний день БД и ХД — это не только системы для надежного хранения и обработки служебной информации. ИС такого класса помогают обеспечивать целые спектры задач и услуг от проведения клиентских транзакций до планирования, прогнозирования и принятия тактических и стратегических решений на уровне крупнейших предприятий. На развитие ИТ-инфраструктуры компании готовы тратить огромные средства, понимая всю важность этой составляющей не только для повышения эффективности и получения прибыли, но и для повышения конкурентоспособности на рынке. Поэтому при выборе ИС крайне важно не только понимать цели компании, прогнозировать возможные изменения в будущем, но и хорошо ориентироваться в постоянно изменяющемся мире ИТ-технологий, предлагаемых решениях, их назначении, и политике работы и взаимодействия с клиентами компаний-разработчиков ИС, которые в свою очередь постоянно стремятся совершенствоваться и предлагают клиентам свои лучшие продукты.
Литература:
- Ralph Kimball, Margy Ross. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling. Third Edition. — John Wiley & Sons, 2013.
- Проектирование баз данных: Распределенные базы и хранилища данных. Лекция 2: Многомерное представление данных. Общая схема организации хранилища данных. Характеристики, типы и основные отличия технологий OLAP и OLTP. Схемы звезда и снежинка. Агрегирование // Национальный Открытый Университет «ИНТУИТ». URL: http://www.intuit.ru/studies/professional_retraining/953/courses/214/lecture/5508/ (дата обращения: 11.06.2018).
- Oracle Database Concepts, 11g Release 2 // ORACLE. URL: https://docs.oracle.com/cd/E18283_01/server.112/e16508.pdf (Дата обращения: 11.06.2018).
- Data Warehousing and Big Data // ORACLE. URL: http://www.oracle.com/technetwork/database/bi-datawarehousing/overview/index.html (Дата обращения: 12.06.2018)
- SQL Data Warehouse Documentation // Microsoft. URL: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/ (Дата обращения: 12.06.2018)
- Бергер А. Б. Microsoft SQL Server 2005 Analysis Services. OLAP и многомерный анализ данных / Бергер А. Б., Горбач И. В., Меломед Э. Л., Щербинин В. А., Степаненко В. П. / Под общ. Ред. А. Б. Бергера, И. В. Горбач. — СПб.: БХВ-Петербург, 2007.
- Overview of IBM Db2 on Cloud, IBM Db2 Warehouse on Cloud, and IBM Db2 Warehouse // IBM. URL: https://www.ibm.com/support/knowledgecenter/SS6NHC/com.ibm.swg.im.dashdb.doc/overview.html (Дата обращения: 12.06.2018)
- MapReduce and Teradata Aster SQL-MapReduce // Teradata. URL: https://www.teradata.com/products-and-services/Teradata-Aster/teradata-aster-sql-mapreduce (Дата обращения: 12.06.2018)
