





В эпоху дешевого дискового хранилища, высокоскоростного интернет-соединения и огромного увеличения вычислительной мощности сбор даже больших объемов данных стал настолько невероятно простым. Однако простые данные сбора не раскрывают его бизнес-ценность. Чтобы превратиться в значимую информацию, данные должны обрабатываться и анализироваться.
Ключевые слова: Oracle, прокси-объекты, Oracle Enterprise R, базы данных, Oracle Advanced Analytics, SQL.
Известная своей способностью эффективно работать с большими объемами данных, база данных (БД) Oracle идеально подходит для размещения тех магических, но ресурсоемких процедур, которые могут получать значимую ценность из необработанных данных, тем самым реализуя концепцию перемещения обработки данных ближе к данным. Oracle Enterprise R, являющийся компонентом опции Oracle Advanced Analytics для БД Oracle, превращает эту концепцию в реальность, предоставляя основу для интеграции R — языка статистического программирования с открытым исходным кодом, который лучше всего подходит для анализа данных — с БД Oracle, производительность в исполнении в базе данных команд и скриптов R.
Знакомство с Oracle Enterprise R требует, чтобы вы поняли, как это работает и как вы можете эффективно использовать его. Хорошая структура, которой следует следовать при обучении Oracle Enterprise R, включает:
- Уровень прозрачности, который позволяет пользователям:
‒ Использовать прокси-объекты — данные остаются в базе данных.
‒ Использовать перегруженные функции R, которые переводят функциональность в SQL
‒ Использовать стандартный синтаксис R для управления данными базы данных
- Параллельные распределенные алгоритмы, которые позволяют пользователям:
‒ Улучшение масштабируемости и производительности
‒ Использовать в базе данных алгоритмы из ODM
‒ Использовать дополнительные алгоритмы на основе R, выполняемые на сервере базы данных
- Выполнение Embedded R, которое позволяет пользователям:
‒ Хранить и вызывать скрипты R в базе данных Oracle
‒ Выполнять параллельное и непараллельное выполнение данных
‒ Использовать пакеты CRAN с открытым исходным кодом
Будучи языком статистического программирования, R предсказуемо предлагает богатый набор инструментов для анализа данных. Oracle Enterprise R расширяет эту функциональность, введя набор объектов и функций для эффективной работы с данными, хранящимися в базе данных Oracle [1, с. 285].
Oracle Enterprise R предоставляет возможность доступа к таблицам базы данных в виде R data.frames и подталкивать R data.frames к базе данных в виде таблиц, создавая соответствующие прокси-объекты Oracle R Enterprise, которые нужно манипулировать в языке R. Использование прокси-объектов для таблиц позволяет преодолеть память ограничения сеанса клиента R и использование мощности обработки сервера базы данных при выполнении операций анализа данных. Фактически, Oracle Enterprise R перегружает множество стандартных функций R, чтобы они трансформировали операции R в SQL, которые выполняются в базе данных.
Пользователи также могут извлекать объекты базы данных в локальные объекты R. Для выполнения этих операций push и pull вы можете использовать функции ore.push и ore.pull, соответственно. Первая создает временную таблицу базы данных из локального объекта R. Например, вы можете использовать ore.push, чтобы направить объект data.frame R в базу данных как временную таблицу, получив объект ore.frame как прокси R для этой таблицы. Строго говоря, объект ore.frame сопоставляется с таблицей или представлением базы данных, представляющей объект прокси-сервера Oracle Enterprise R для этого объекта базы данных — это подкласс data.frame. С другой стороны, вы можете использовать ore.pull, чтобы вытащить данные таблицы базы данных в объект data.frame R [1, с. 169].
Схематически это может выглядеть так [2, с. 1024], как показано на рис. 1.
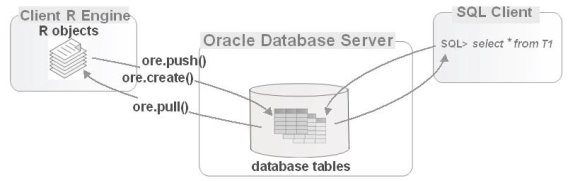
Рис. 1. Oracle Enterprise R позволяет придвигать объекты R в базу данных в виде таблиц, вытаскивать данные обратно в R (при желании) и перегружать функции R, чтобы неявно переводить операции R в SQL для взаимодействия с этими таблицами
Когда сеанс клиента R отключается от базы данных, все несохраненные временные таблицы, созданные для объектов R, перемещаемых во время сеанса, автоматически удаляются. Если вы хотите создать объекты proxy ore.frame для постоянных таблиц базы данных, вы можете использовать функцию ore.create. Такой подход может быть очень полезен для случаев, когда вы хотите получать доступ к своим данным не только с помощью R, но также и с SQL и выполнять вычисления в базе данных.
Важным ограничением извлечения данных в R является то, что вы можете вытащить таблицу базы данных или просмотреть в R-кадр данных только в том случае, если данные могут вписаться в локальную память сеанса R. Это может быть проблемой, когда дело доходит до больших наборов данных. Более того, нет причин для вытягивания, если вы планируете подавать набор данных в одну или несколько функций ORE [3, с. 588]. Oracle R Enterprise (ORE) входит в опцию Oracle Advanced Analytics. Oracle R Enterprise позволяет использовать язык R для бесшовной интеграции с Oracle Database, позволяя использовать мощь и масштабируемость базы данных Oracle. С помощью Oracle R Enterprise вы можете быстро и легко перенести свою расширенную аналитику R для использования базы данных Oracle с минимальными изменениями кода в своих R-сценариях. Наличие языка R в качестве элемента кода Oracle Database значительно расширяет статистические, аналитические и графические возможности Oracle Database.
Oracle предлагает 4 основных решения, основанных на языке R:
‒ Oracle R Enterprise: это версия языка R, которая была создана для работы в составе базы данных Oracle. Это позволяет запускать ваш R-код и скрипты в Oracle Database, используя производительность и масштабируемость сервера Oracle Database.
‒ R Oracle: пакет R, который позволяет вам подключаться к базе данных Oracle. Этот пакет специально настроен для использования Oracle Net для обеспечения эффективной связи с Oracle Database и для сверхбыстрого перемещения данных между клиентской машиной и Oracle Database.
‒ Oracle R Distribution: это настраиваемая версия языка R с открытым исходным кодом, которая предоставляется бесплатно Oracle. С Oracle R Distribution Oracle настроила определенные пакеты и функции для эффективной работы с Oracle Database.
‒ Oracle R Advanced Analytics для Hadoop: это позволяет запускать ваш R-код для доступа и запуска на Hadoop с использованием рамок программирования MapReduce для пользователей R. Этот пакет является частью программного пакета Oracle Big Data Connectors Software Suite [4, с. 98].
Когда вы работаете над вашими научными проектами, вы, как правило, создаете несколько временных объектов. При работе с R они сохраняются в вашей локальной среде. Но когда вы работаете с вашими данными (большими или малыми) и используя Oracle R Enterprise для работы с данными в базе данных, вы можете открыть для вас три основных варианта для сохранения этих временных объектов. Первый вариант — сохранить их на локальном компьютере. Но по мере роста объемов данных это может стать проблемой. Кроме того, это также проблема безопасности данных, так как в конечном итоге вы будете обрабатывать различные части данных вашего предприятия, расположенные на локальных машинах. Это может не быть проблемой для небольшой команды, но если это средние и большие, то это может стать проблемой. Второй вариант — хранить временные объекты в таблицах в базе данных. Это может быть не идеальным, поскольку вы будете смешивать основные данные с временными рабочими наборами данных. Опять же, как растет ваша научная команда, это может стать проблемой, поскольку вы не будете знать, что является основным, а что нет. Третий вариант — использовать и ORE Data Store. Это позволяет хранить эти временные объекты вместе в базе данных, но отдельно от основных данных, над которыми вы работаете. В дополнение к различным подсистемам данных вы также можете использовать хранилище данных ORE для хранения множества других объектов R.
При работе с временными объектами ORE они будут существовать только на время ваших соединений. Поэтому, когда вы отключите сеанс ORE, все временные объекты, созданные в базе данных, также будут удалены и удалены из базы данных. Было бы полезно, если бы мы могли сохранить эти временные объекты для последующего использования без необходимости выполнять дополнительные шаги по созданию таблиц для хранения данных. Кроме того, с использованием ORE вы можете создавать другие типы объектов, такие как модели интеллектуального анализа данных, которые мы хотим использовать позже. То, что мы не хотим делать, — это повторить шаги по созданию этих объектов снова и снова [5, с. 79].
С помощью Oracle R Enterprise мы можем создать и ORE Data Store в нашей базе данных. В этом хранилище данных ORE мы можем хранить все эти объекты ORE, которые мы создали. Мы можем совместно использовать хранилище данных ORE с другими аналитиками и учеными-аналитиками данных, но, возможно, самой важной особенностью хранилища данных ORE является то, что мы можем использовать его, когда мы выполняем встроенное выполнение ORE в SQL.
Примеры, приведенные в этой статье, касаются создания хранилища данных ORE, сохранения объектов в нем, поиска объектов, получения информации о хранилище данных ORE, удаления объектов и, наконец, удаления хранилища данных ORE.
Идея состоит в том, что пользователь R сохраняет свой знакомый набор инструментов, как правило, что-то вроде RStudio, но теперь может использовать аналитическую и вычислительную мощь масштабирования базы данных для больших наборов данных и использовать встроенный параллелизм оптимизатора базы данных. ORE на самом деле также включает разъемы hadoop, но в этой статье я сосредоточусь только на функциях базы данных.
Ключевыми особенностями ORE являются:
‒ Уровень прозрачности
‒ Вызов базы данных, встроенный R из R
‒ Вызов базы данных, встроенный R из SQL
‒ Легкая визуализация анализа
Эта статья намеревается показать два варианта для начала работы с ORE. Большая виртуальная машина BigDataLite, которая на сегодняшний день является самой простой, и выполняет «обычную» установку, которая дает больше информации о внутренней работе ORE [6, с. 24].
R-дистрибутив и ORE, установленные таким образом, попытаются подключиться к архиву CRAN или одному из его зеркал. При установке пакетов с использованием «install.packages» система запустит GCC, скомпилировав все его зависимости и установив их на ОС хоста базы данных. Это отлично подходит для быстрых экспериментов, но если ORE предназначен для использования в качестве «производства», убедитесь, что эта настройка совместима и что системные администраторы знают и способны управлять пакетами. В худшем случае вам может понадобиться локальное проверенное зеркало CRAN, из которого вам разрешено устанавливать пакеты.
Часть R в базе данных порождает процессы R, используя EXTPROC на узлах (узлах) базы данных. В большой степени это замечательно, так как позволяет этим пакетам CRAN работать независимо от конкретной доступности объектов и алгоритмов в самой базе данных, тем самым расширяя аналитические возможности. Однако это также означает, что сам механизм базы данных не имеет «реального» контроля над этими процессами и их многопоточности или параллелизма (или их отсутствия). Преимущества параллелизма базы данных связаны с преобразованием объектов R в объекты ORE, что позволяет оптимизатору базы данных работать со своей магией.
Выполнение встроенного R, либо через R, либо SQL, позволяет разделить данные и управлять количеством процессов R, начатых для обработки этих разделов. Таким образом, достигается большая степень параллелизма в сочетании с параллельным вариантом в самой базе данных. Вся обработка выполняется на узлах базы данных, чтобы они могли мешать друг другу. Относительная простота импорта данных и перенос их в базу данных потенциально могут стать альтернативным инструментом ETL. Будьте осторожны, хотя происходит некоторое неявное преобразование типов. Преимущества производительности с использованием ORE непосредственно на данных оракула по-прежнему в значительной степени зависят от тщательного моделирования. Если ORE применяется к плохой модели данных, мы получаем плохие результаты, даже при использовании встроенного механизма R. Потенциал заключается в том, что промежуточные результаты обычно не нужно возвращать в рабочее пространство R для дальнейшей обработки, что ограничивает стоимость транспортировки данных [6, с. 214].
В этой статье вы рассмотрели, что такое Oracle Enterprise R — это надстройка над языком, которая позволяет использовать мощь СУБД Oracle для анализа на языке R больших объемов данных. Кроме того, Oracle Enterprise R делает возможным не выносить данные из базы данных для анализа, что очень важно для больших промышленных СУБД, как Oracle R Enterprise соединяет R с базой данных Oracle, обеспечивая возможность переноса большой обработки данных, выполняемой функциями R на сервер базы данных. Вы узнали, что Oracle Enterprise R перегружает многие функции R, так что построенная модель в R может использовать преимущества и возможности обработки сервера баз данных, такие как параллелизм.
В этой статье вы рассмотрели, что такое Oracle Enterprise R — это надстройка над языком, которая позволяет использовать мощь СУБД Oracle для анализа на языке R больших объемов данных. Кроме того, Oracle Enterprise R делает возможным не выносить данные из базы данных для анализа, что очень важно для больших промышленных СУБД, как Oracle R Enterprise соединяет R с базой данных Oracle, обеспечивая возможность переноса большой обработки данных, выполняемой функциями R на сервер базы данных. Вы узнали, что Oracle Enterprise R перегружает многие функции R, так что построенная модель в R может использовать преимущества и возможности обработки сервера баз данных, такие как параллелизм.
Литература:
- Рик Гринвальд, Роберт Стаковьяк, Гэри Додж, Дэвид Кляйн, Бен Шапиро, Кристофер Дж. Челья. Программирование баз данных Oracle для профессионалов = Professional Oracle Programming. — М.: «Диалектика», 2007. — ISBN 978–5-8459–1138–4.
- Фейерштейн С., Прибыл Б. Oracle PL/SQL. Для профессионалов. 6-е изд. СПб.: Питер, 2015. — ISBN 978–5-496–01152–5.
- Роберт Кабаков. R в действии = R in Action. — ДМК-Пресс, 2014. — ISBN 978–5-947060–077–1.
