





С увеличением объема хранимой в базе данных информации, возрастает сложность хранения и быстрого поиска нужных пользователю данных.
Поиск нужной информации всегда был приоритетной задачей при работе с базами данных, а с ростом объемов данные распределяются по разным файлам, а также по разным серверам, нередко находящимся в разных зданиях и даже городах.. Методов оптимизации структуры таблиц и поиска данных существует множество, но универсальных среди них нет.
Одним из методов оптимизации хранения табличных данных и, соответственно, увеличения производительности SQL-запросов к серверу является секционирование таблиц. Секционирование подразумевает физическое разбиение таблицы на несколько секций, которые хранятся в разных файлах. Разбиение происходит по определенным параметрам, задаваемым администратором базы данных. Такой подход приносит ряд существенных преимуществ.
– Ускорение поиска данных. Действительно, если данные логически распределены по разным файлам, то при поиске данных, удовлетворяющих определенным условиям, нет необходимости сканировать все файлы, достаточно просканировать только те, где хранятся данные, удовлетворяющие заданному параметру;
– Дефрагментация данных. В процессе работы сервера базы данных одна и та же память используется многократно и беспорядочно, из-за чего замедляются операции ввода-вывода и сканирования таблиц. Секционирование позволяет реорганизовать физически хранение таблицы, так как данные разбиваются на файлы по определенному условию, что позволяет бороться с дефрагментацией.
Секционирование также влечет и ряд трудностей. Временные затраты на индексирование достаточно значительны, поэтому для его проведения необходимо выбирать время, когда база данных не в работе или минимально нагружена. Также секционирование проводится лишь по одному свойству, поэтому, если необходимо провести поиск по какому-то другому столбцу, то сканировать нужно будет все файлы. При этом стоит учитывать, что если таблица хранится в нескольких файлах, то воссоздание разбитых на файлы в данных в единую таблицу будет занимать больше времени.
Проверим производительность простых запросов к одной таблице. Будут рассматриваться запросы с сортировкой строк, группировкой, выборкой по условию (≈40 % от общего объема) и группировка с условием. При этом результатом запроса будет выборка всех полей таблицы. Примеры запросов представлены на Рис. 1:
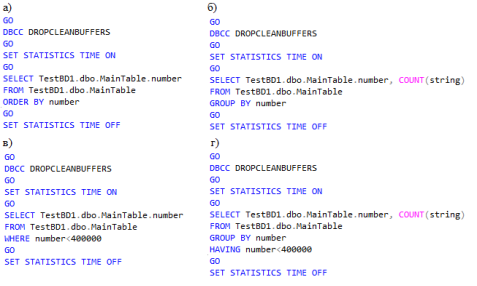
Рис. 1. Запросы к таблицам базы данных а) выборка всей таблицы с сортировкой; б) группировка по числовому столбцу; в) выборка по условию; г) группировка с условием
Тестировать различные запросы будем на таблицах, содержащих два поля: числовое и текстовое. Таблицы будут заполнены случайными данными (числа до 1000000 в числовом поле и строка из 10 символов английского алфавита — в текстовом). Проверять скорость выполнения запросов будем на разных объемах данных: 10000, 100000, 1000000 и 10000000 записей. Изначально таблицы не будут проиндексированы или секционированы. Перед каждым выполнением запроса будем очищать буфер сервера, так как сервер может хранить скомпилированные запросы и это ускоряет время их выполнения при последующих запусках, а для достоверности результатов каждый из них будет запускаться многократно, чтобы получить среднее время выполнения. Для сокращения времени вывода данных, результат выполнения запросов будет сохраняться в файл.
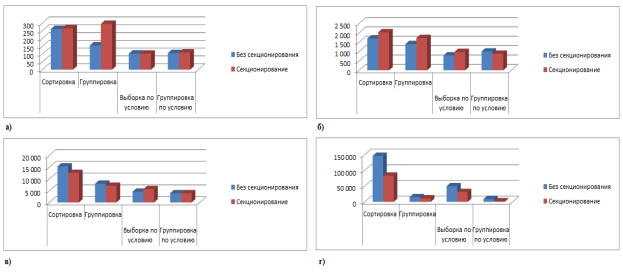
Рис. 2. Время выполнения различных запросов к таблицам данных а) 10000 записей, б) 100000 записей; в) 1000000 записей г) 10000000 записей
На Рис. 2 представлено сравнение времени выполнения запросов данных к секционированным и несекционированным таблицам. Полученные результаты показывают, что запросы к секционированным таблицам обрабатываются примерно за то же время, что и к обычной таблице при средних объемах данных, и даже замедляют выполнение запросов при объемах менее 100000 записей. Однако, при увеличении объемов данных до 10000000 записей эффективность секционирования резко возрастает, причем сравнимую производительность показывает только применение columnstore, который также эффективен на больших объемах данных, но не дает большого прироста к скорости на малых. Выбор того или иного метода зависит от особенностей использования таблицы.
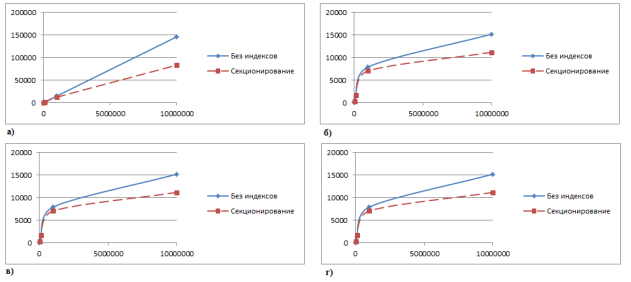
Рис. 3. График роста времени выполнения запросов при росте объема данных а) Запрос с сортировкой; б) Запросы с группировкой; в) Выборка по условию; г) Группировка по условию
На Рис. 3 отображено изменение скорости выполнения запросов при увеличении объема данных. Это позволяет дать приблизительные оценки того, насколько сильно скажется секционирование при дальнейшем увеличении объемов данных. Как видно по графикам, для всех запросов, кроме сортировки данных, зависимость близка к логарифмической, а значит, что эффективность секционирования будет расти гораздо быстрее роста объема данных.
На практике очень часто нет возможности самому оценить, каким образом можно ускорить время выполнения запроса из-за его сложности, объединения нескольких таблиц и т. д. В таких случаях очень полезно ознакомиться с планом выполнения запроса, который может подсказать, какие оптимизации уместны для тех или иных таблиц.
Рассмотрим запрос (Рис. 4). Он возвращает все числа из таблицы LargeTable (1000000 записей), которые встречаются в таблице GreatTable (10000000 записей), и количество раз, которое оно встречается.
![]()
Рис. 4. Запрос на объединение данных
Время выполнения запроса составило 16700 мс. А теперь рассмотрим план выполнения запроса (Рис. 5):

Рис. 5. План выполнения запроса
План запроса демонстрирует последовательность действий сервера и, самое важное, временные затраты на тот или иной шаг. Видно, что просмотр строк таблицы GreatTable (10000000 строк) занимает почти половину от общего времени, а еще четверть — агрегатная функция (группировки). Отметим также, что планировщик сразу указал на отсутствие индекса для LargeTable, давая понять, что добавление оного ускорит выполнение запроса.
Попробуем оптимизировать запрос, опираясь на план и используя индексы. После добавления предложенного планировщиком индекса время выполнения запроса составило 14535мс, однако, снова посмотрев на план, можно заметить, что главные временные затраты не изменились (Рис. 6). На рисунке также приведен увеличенный фрагмент предыдущего плана:
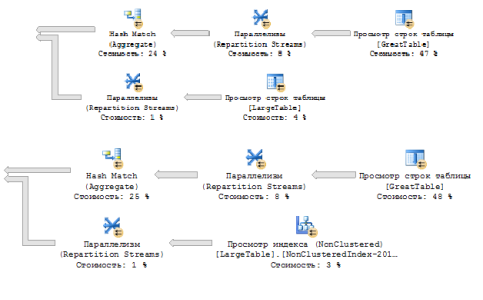
Рис. 6. Сравнение двух планов выполнения запроса
Очевидно, что нам нужно ускорить время обработки таблицы GreatTable. Данные, которые мы получили ранее, говорят о том, что секционирование этой таблицы даст ощутимый прирост во времени. Секционировав таблицу, мы получили время выполнения запроса 9720 мс. Наконец, отменим секционирование и некластеризованный индекс, заменив их кластеризованными на обеих таблицах. Время выполнения запроса составило 10812 мс. Это демонстрирует нам, что эффективная (как казалось) оптимизация, на деле лишь затормозила выполнение нашего запроса.
Литература:
- Дунаев, В. В. Базы данных. Язык SQL для студента / В. В. Дунаев. — М.: БХВ-Петербург, 2017. — 288 c.
- Аллен, Г. Тейлор SQL для чайников / Аллен Г. Тейлор. — М.: Диалектика, Вилья, 2015. — 416 c.
- Владимир, Михайлович Илюшечкин Основы использования и проектирования баз данных / Владимир Михайлович Илюшечкин. — М.: Юрайт, 2015. — 516 c.
- Карвин, Билл Программирование баз данных SQL. Типичные ошибки и их устранение / Билл Карвин. — М.: Рид Групп, 2018. — 336 c.
