





Введение
Задача классификации изображений является актуальной в настоящее время. Существует множество областей, где решение данной задачи востребовано, например, судебное делопроизводство или компании с повышенным требованием к безопасности.
В данной статье рассматриваются методы классификации изображений с отсканированным рукописным текстом по авторам.
Распознавание рукописных символов делится на 2 группы:
− Распознавание рукописной информации, введенной с помощью специальных сенсорных экранов (online).
− Распознавание рукописной информации с бумажных носителей (offline).
Онлайн распознавание текстов учитывает начертательные особенности человека — силы нажима, быстроты написания. В свою очередь, офлайн распознавание текста получает на вход уже готовый документ, поэтому является более сложным процессом. В данной статье рассматривается только офлайн распознавание.
Также, рассматриваются только пространственные признаки рукописного текста — это рассмотрение объекта с точки зрения структуры, выделения составляющих элементов и их взаиморасположения. Этими признаками могут быть: расстояние между словами, расстояние между буквами, левый и правый отступы. Выбор данной темы обусловлен тем, что данные признаки текста не зависят от языка, семантики или назначения документа.
В следующих пунктах сравниваются 2 метода классификации изображений: а именно, метод опорных векторов (SVM) и Сверточные Нейронные сети (CNN).
SVM (SupportVectorMachine)
Пусть имеется обучающая выборка:
Метод опорных векторов строит классифицирующую функцию F в виде ![]() , где
, где ![]() — скалярное произведение, w — нормальный вектор к разделяющей гиперплоскости, b — вспомогательный параметр. Те объекты, для которых F(x) = 1 попадают в один класс, а объекты с F(x) = -1 — в другой. Выбор именно такой функции неслучаен: любая гиперплоскость может быть задана в виде
— скалярное произведение, w — нормальный вектор к разделяющей гиперплоскости, b — вспомогательный параметр. Те объекты, для которых F(x) = 1 попадают в один класс, а объекты с F(x) = -1 — в другой. Выбор именно такой функции неслучаен: любая гиперплоскость может быть задана в виде ![]() для некоторых w и b. Далее, мы хотим выбрать такие w и b которые максимизируют расстояние до каждого класса. Можно подсчитать, что данное расстояние равно
для некоторых w и b. Далее, мы хотим выбрать такие w и b которые максимизируют расстояние до каждого класса. Можно подсчитать, что данное расстояние равно ![]() . Проблема нахождения максимума
. Проблема нахождения максимума ![]() эквивалентна проблеме нахождения минимума
эквивалентна проблеме нахождения минимума ![]() . Запишем все это в виде задачи оптимизации:
. Запишем все это в виде задачи оптимизации:
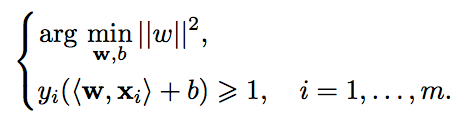
Данная задача является стандартной задачей квадратичного программирования и решается с помощью множителей Лагранжа.
CNN (Сверточные нейронные сети)
Сверточная нейронная сеть — это специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном в 1988 году и нацеленная на эффективное распознавание образов, входит в состав технологий глубокого обучения. Идея сверточных нейронных сетей заключается в чередовании сверточных слоёв и слоёв нелинейного уплотнения. Структура сети — однонаправленная, многослойная.
Когда компьютер принимает данные на вход, в данном случае данные — это отсканированные образцы почерков, то он видит массив пикселей. В зависимости от разрешения и размера изображения, например, размер массива может быть 32х32х3, где 3 — это значения каналов RGB. Каждому из этих чисел присваивается значение от 0 до 255, которое описывает интенсивность пикселя в этой точке. В качестве выхода мы требуем вектор, каждое число которого будет принадлежать диапазону от 0 до 1 и обозначать вероятность принадлежности данного объекта к каждому из классов. После этого объект будет относиться к классу с наибольшей вероятностью.
СНС пропускает изображение через серию сверточных слоев, слоев объединения и полносвязных слоёв. Основа CNN — сверточный слой. Он получает на вход матрицу пикселей, которая обрабатывается с помощью фильтров, других матриц меньшего размера. Данная операция называется сверткой. Пример свертки представлен на Рис.1.
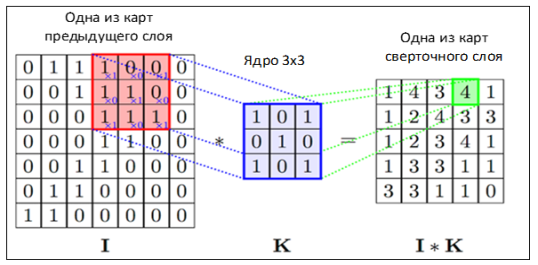
Рис. 1.
Обучение
Для обучения рассмотренных методов использовалась база данных IAM Handwriting Database, которая содержит формы рукописного текста, которые были отсканированы с разрешением в 300 точек на дюйм и сохранены в формате PNG c 256 градациями серого. Данные содержат 1,539 англоязычных рукописных текстов 657 различных авторов.
Оценкой классификации служат выбранная метрика — accuracy метрика. Accuracy является самой простой и понятной метрикой, она показывает отношение правильно классифицируемых объектов ко всем объектам выборки.

Результаты
SVM метод классификации показал точность 73.21 % при выборе лучших параметров путем поиска GridSearch.
CNN показал точность 89,94 %. Параметры размера и количества фильтров подбирались практически. В качестве активационных функций сверточных слоев была использована функция RELU. На выходном слое — SoftMax.
Заключение
Были рассмотрены два метода классификации изображений: SVM и CNN. Сравнивая, показатели точности этих алгоритмов на коллекциях изображений, пришли к выводу, что в среднем, Сверточные Нейронные сети работают лучше.
Литература:
- Christopher M. Bishop. Pattern recognition and machine learning, 2006.
- К. В. Воронцов. Лекции по методу опорных векторов.
- Л. В. Степанов. Моделирование конкуренции в условиях рынка.
