





В работе представлена концепция организации диалога между человеком и искусственным интеллектом, управляющим квазиживым объектом. Сформулированы требования к программному продукту, обеспечивающему перевод как текста, так и диалога и установлено, что классические методики непригодны, поскольку не учитывают модели и память, как сторон диалога, так и социумов сторон.
Предложенная модель переводчика позволит при её реализации обеспечить диалог с искусственным интеллектом на основе нечёткой логики. Дополнительно появится возможность преобразовывать тексты естественного языка, адаптируя его под уровень подготовки читателя, либо деформируя по-отдельности как свойства объектов, так и их эвентуальные мировые линии или параметры взаимодействия.
Ключевые слова: когниция, управление, искусственный интеллект, квазиживая система, нечёткая логика, перевод, информация, метаязык, целевой язык, адаптация текста, технологический уклад.
Цивилизация вошла в шестой технологический уклад. Искусственный интеллект уже удовлетворительно справляется с распознаванием образов и ситуаций в потоках видео- и аудиоинформации, а также обработкой статусов с датчиков состояния. Более или менее успешно решаются задачи управления оборудованием в реальном времени. Идут процессы создания зачатков когнитивных систем, использующих пока когнитивный аппарат людей, которые управляют процессами и ставят задачи исполнительным механизмам в условиях неполноты информации.
На следующем технологическом укладе мы уверенно можем ожидать появления квазиживых объектов (систем), способных самостоятельно управлять процессами при неполноте информации и обладающих когницией. Различия между живой и квазиживой системами по мере развития технологий постепенно стираются. Важнейшим отличием квазиживой системы от живой — это искусственное происхождение и наличие «смысла жизни» или целеполагания.
Для взаимодействия с подобными системами человеку потребуется либо разрабатывать языки общения, либо создавать системы, которые смогут переводить речь человека на естественном языке в понятные для системы команды и обратно, то есть получать информацию как о текущем состоянии объекта управления, так и об ожидаемых изменениях и вариантах выхода из проблемных ситуаций.
В чём-то это задача старая и давно решённая нашими предками, которые сумели приручить животных, например собак, птиц или слонов. Не далеко от неё ушла и задача начального обучения детей, которые при рождении не способны к обмену информацией с помощью второй сигнальной системы. В основу её положен путь навязывания приручаемому или обучаемому постепенно усложняемого набора команд, кодируемых голосом, жестом или механическим воздействием на обучаемого. Граница обучаемости определяется возможностями когнитивного аппарата (процессора) обучаемого и для кого-то ограничена десятком простейших команд, а для кого-то — формированием навыков использования для обратной связи второй сигнальной системы.
С неживыми автоматизированными системами взаимодействие пошло иным путём — создаётся язык команд, который привязан к управляющему звену системы, и человек просто изучает его, чтобы иметь возможность отдавать команды и следить за их исполнением. То есть учится не когнитивный процессор системы, а человек. Однако по мере усложнения квазиживых систем такой путь становится тупиковым, поскольку число параметров, которые обрабатываются системой, и скорость их обработки намного превышают возможности человека в их восприятии и оценке. Для следующего поколения квазиживых систем, когниция которых построена на нечёткой логике, этот путь уже бессмысленен.
В современных системах обмены идут уже давно на уровне нечёткой логики и на ней же строится управление, построенное на нейросетях. Предложить человеку общаться с когнитивным процессором объекта на языке нечёткой логики можно, но бесполезно, хотя бы потому, что такого числа параметров, которым оперирует даже сравнительно несложная система управления сегодня, мозг уже охватить не может и время осознания человеком информации по текущему состоянию системы может оказаться дольше времени его жизни.
Получается, что вскоре потребуется создавать нечто, позволяющее общаться человеку с созданным им же искусственным разумом. При этом пора понять, что речь идёт не о фантастике, а ближайшем будущем и к проблеме следует подойти основательно, потому как её решение потребует существенных вложений средств и времени. Более того, становится ясно, что не человеку придётся учить язык машины, а машине как более шустрому компоненту пары придётся изучать язык человека.
Фактически речь идёт о неком переводчике, который сможет транслировать кодированную человеком во второй сигнальной системе информацию в нечёткую логику искусственного разума и обратно. Вопрос, где он будет размещён — в самой системе или будет являться внешним устройством или окажется облачным сервисом, — на данном этапе не существенен.
Рассмотрим поэтапно, что должен уметь переводчик, который будет встроен в процессы обменов между человеком и квазиживой системой с когницией.
Термины и определения, используемые в тексте
Будем использовать термины и определения, уже привычные для специалистов [1, 2, 3].
Базовый двуязычный морфологический словарь. В этом словаре устанавливается пословное соответствие каждой словоформы исходного языка словоформам целевого языка.
Гомеостазис — способность открытой системы поддерживать равновесие при наличии возмущений, обусловленных как внешними, так и внутренними факторами.
Грамматическая полисемия— совпадение разных грамматических форм одной лексемы.
Диалог — двустороння передача информации с обратной связью, позволяющая корректировку информации в процессе обменов.
Исходный язык— язык оригинала.
Квазиживая система — открытая система, обладающая когницией и способная к поддержанию гомеостазиса, а также обменивающаяся с окружающей средой массой, энергией и информацией.
Когнитивный процессор — ядро когнитивной системы.
Когниция — инструмент, благодаря которому открытая система способна поддерживать гомеостазис при неполноте информации об окружающей среде и взаимодействовать с окружающей средой, хранить информацию, обучаться. Когниция позволяет выйти системе на более высокую ступень реагирования, нежели это наблюдалось при рефлекторной и инстинктивной деятельности.
Корпус параллельных текстов. Корпус содержит тексты на исходном языке оригинала и их переводы на целевой язык. При нахождении предложения или его фрагмента в корпусе параллельных текстов в текст перевода вставляется его соответствие на целевом языке. На использовании корпуса текстов построена технология памяти переводов.
Лексическая полисемия— способность одного слова служить для обозначения разных предметов и явлений действительности.
Метаязык — либо промежуточный внутренний язык системы перевода, либо естественный/искусственный язык «второго уровня», описывающий язык «первого уровня».
Лексико-грамматический классификатор. При анализе исходного текста каждое слово в нём должно получить соответствующие морфологические характеристики: признак части речи, род, падеж, наклонение, число и др.
Нейросеть — самообучающаяся программа, способная имитировать деятельность человеческого мозга, не просто выполняя последовательность действий по заданному алгоритму, а выбирая оптимальные действия даже при недостатке или противоречиях входных данных.
Неологизмы — слова, возникшие в процессе развития языка или заимствованные из других языков. Объекты и понятия, описываемые неологизмами, ещё не стали повседневными и привычными.
Нечёткая логика — обобщение классической теории множеств и классической формальной логики при описании процессов в сложных системах, требующих многопараметрических базисов.
Полисемия (от греч. polysemos — многозначный) (многозначность) — наличие у единицы языка более одного значения — двух или нескольких. Часто, когда говорят о полисемии, имеют в виду многозначность слов как единиц лексики.
Семантический словарь (тезаурус, онтология). Словарь содержит информацию о семантической сочетаемости лексем, о лексико-семантических полях и применяется на этапе построения семантического графа предложения.
Синтаксический словарь. Словарь содержит информацию о синтаксической сочетаемости членов предложения как в исходном языке, так и в целевом языке, а также синтаксические соответствия, необходимые при переводе.
Словарь идиом. Применяется до синтаксического анализа, поскольку очень часто идиома является одним членом предложения и рассматривается как единое целое; при переводе идиома на исходном языке может соответствовать одному слову на переводном языке.
Словарь сокращений иаббревиатур. Словарь используется на этапе разбиения исходного текста на слова и предложения. Сокращения и аббревиатуры должны быть по возможности расшифрованы, так как они могут являться членами предложения, следовательно, их необходимо учитывать при синтаксическом и семантическом анализе.
Терминологические словари по предметным областям. Дополнительные словари подключаются при необходимости перевода специализированных текстов.
Целевой язык — язык, на который выполняется перевод.
Язык-посредник — он же метаязык перевода. Между структурами исходного языка и структурами целевого языка создаётся или используется хорошо развитый промежуточный язык, на который по соответствующим правилам последовательно транслируются выражения исходного языка. Анализ и синтез при использовании языка-посредника принципиально разделяются. Анализ ведётся в категориях исходного языка, а синтез — в категориях целевого.
Технологии современного перевода
Прежде чем перейти к анализу задачи управления квазиживым объектом с использованием естественного языка, напомним, как на сегодня выполняется перевод между различными языками нашего мира [4,5,6].
Дадим краткий обзор сложившейся ситуации с переводом между языками. Понять проблемы на этом уровне крайне важно, поскольку следующий шаг будет намного сложнее. Итак, на сегодня есть всего 4 системы «машинного» перевода:
– системы на основе грамматических правил (Rule-Based Machine Translation, RBMT);
– статистические системы (Statistical Machine Translation, SMT);
– гибридные системы;
– нейро-машинный перевод (Neural Machine Translation, NMT).
Разбор методов перевода можно найти в [6,7], тут же дадим их краткую характеристику, которая пригодится для последующего анализа.
Системы на основе грамматических правил [8,9] производят анализ текста с помощью встроенных словарей для выбранной языковой пары: анализируются грамматики, охватывающие семантические, морфологические, синтаксические закономерности обоих языков. На основе всех этих данных исходный текст фреймируется, а затем последовательно, предложение за предложением, преобразуется в текст на целевом языке.
Преимуществами систем на основе грамматических правил являются грамматическая и синтаксическая точность, стабильность результата, возможность настройки на предметную область. Недостатки подобных систем связаны с необходимостью создания, поддержки и обновления лингвистических баз данных, привязываемых к предметным областям.
Статистические системы при своей работе используют двуязычные корпуса текстов [10]. Система анализирует статистику межъязыковых соответствий, синтаксических конструкций и т. д.
Модель работы статистической системы основана на поиске в таблице переводов нескольких самых вероятных переводов для каждого слова исходного предложения, комбинировании полученных из целевого языка слов в разных сочетаниях и формировании списка возможных вариантов. Затем все предложения из этого списка оцениваются на основе семантических, морфологических и синтаксических закономерностей целевого языка. Предложение, которое получает максимальный балл, принимается за перевод исходного предложения.
Система частично самообучаема, поскольку набирается статистика, особенно при работе с обратной связью. С каждым переведённым текстом, проверенным живым переводчиком, улучшается качество последующих переводов.
Статистические системы отличаются быстротой настройки и лёгкостью добавления новых направлений перевода. Среди недостатков наиболее значительными являются наличие многочисленных грамматических ошибок и нестабильность перевода.
Гибридные системы являются синтезом RBMT и SMT. При их создании предполагалось, что в результате получится технология перевода, которая будет обладать возможностями как статистических систем, так и систем, основанных на правилах.
Нейронные алгоритмы анализируют каждый кусочек текста и пытаются распознать его контекст, определяя значение каждого слова в переводимом секторе. Технология NMT выходит за рамки грамматических правил, семантики и языковой структуры, обнаруживая неожиданные лингвистические шаблоны и делая открытия, на которые не способен даже разум человека. Затем целые предложения на исходном языке деконструируются и вновь восстанавливаются уже на целевом языке.
Обратим внимание, что пока мы рассмотрели перевод однонаправленный, использующий текст в качестве промежуточного кодирования информации. В конечном итоге нам необходим несколько иной режим перевода, который обычно называют синхронным, то есть режим, поддерживающий двустороннюю передачу информации в реальном времени.
Подобных систем перевода пока создано мало, и они работают крайне нестабильно. Поэтому используются «живые» переводчики. То есть когнитивные процессы, необходимые при переводе, обеспечиваются специально обученными людьми (иногда парой — по одному на каждое направление перевода).
При этом учитываются и невербальные формы, в частности жестикулирование и визуальное представление информации, понятное обеим сторонам диалога без перевода.
Однонаправленный перевод текста
Рассмотрим процесс перевода художественного текста, который исходно предполагает процесс одностороннего обмена информации (simplex) от автора к читателю.
С техническими текстами ситуация несравнимо проще, поскольку словари меньше, система определений жёстче, практически не используются художественные приёмы, в частности метафора, аллегория, гипербола, ирония, перифраз и тому подобное.
На Рис. 1 показан процесс, который общепринят на настоящий момент, начиная от выявления (создания) исходного образа до его восстановления читателем.
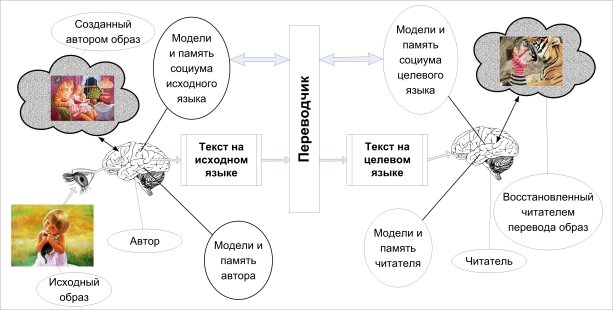
Рис. 1. Схема однонаправленного перевода
Рассмотрим цепочку, показанную на Рис. 1. Исходный образ воспринимается автором текста с использованием органов чувств. Затем он преобразуется в собственный — ментальный — образ, который, помимо исходной информации, задействует собственные модели и память. На это накладывается модель и память социума, в котором обитает автор. В результате, используя совокупность знаний и представлений, а также ограниченность исходного языка, автор создаёт текст на исходном языке.
Затем текст, возможно по прошествии времени, обрабатывается переводчиком. Чем располагает переводчик, независимо от его природы (человек или машина)? Максимум — ограниченным объёмом модели и памяти социума, в котором существовал автор, а в основном — лишь текстами на исходном языке, которые как-то и кем-то были переведены на целевой язык.
Имея заведомо неполную информацию, переводчик формирует текст на целевом языке, более или менее причёсанный в рамках синтаксиса и грамматики целевого языка.
На последней фазе читатель создаёт свой собственный ментальный образ, который, помимо исходной информации, задействует собственные модели и память читающего. На это накладываются модель и память социума, в котором он обитает.
Итоговый образ может иметь общие черты с исходным, но весьма приблизительно, что и показано на Рис. 1. Связано это, как мы видим, не только с потерей информации при описании любого объекта или события, но и с особенностями социума и внутреннего мира автора и читателя.
Рассмотрим теперь упрощённый вариант. Допустим, что целевой язык и исходный совпадают, а переводчик производит тождественную операцию, то есть оба текста идентичны. Казалось бы, что исходный и восстановленный образы должны быть если не идентичны, то близки, хотя бы потому, что модели и память социума идентичны. Однако такое утверждение нельзя признать истинным. Связано это с тем, что модели и память автора и читателя вовсе не обязаны совпадать. Даже если принять за основу идеальной модель автора, то читатель, например математик, пятилетний ребёнок и алкоголик, может обладать совершенно различными моделями и памятью.
Что же мы видим? Можно сделать ряд практически очевидных заключений:
– любой текст не передаёт информацию об описываемом образе в полном объёме;
– прочтение любого текста позволяет восстановить исходный образ множеством вариантов, каждый из которых неполно описывает исходный образ;
– воспринимаемый образ определяется не только текстом, но и моделью и памятью читателя.
А это означает, что добиться адекватного перевода, особенно художественного текста, невозможно. Причина такой ситуации обусловлена тем, что при переводе не учитываются модели и память ни автора, ни читателя.
Вывод: полноценный перевод возможен только при учёте моделей и памяти обеих сторон процесса — как автора текста, так и читателя.
Модели и память социума как автора, так и читателя можно считать сформированными за годы существования социумов, и их связь между собой более или менее выстраивается путём анализа корпуса параллельных текстов и создания комплекса словарей:
– морфологический базовый двуязычный словарь;
– словарь сокращений и аббревиатур;
– словарь идиом;
– словарь неологизмов;
– терминологические словари по предметным областям;
– словарь перевода специализированных текстов;
– синтаксический словарь.
А вот модели и память автора — индивидуальны, и разложить их по подобной схеме уже так просто не получается. Из очевидного: необходимо было бы создать частотные словари всех указанных выше типов, а также в базисе нечёткой логики оценить автора по ряду параметров, в частности общей грамотности, уровню чувства юмора, склонности к художественным приёмам и частоте их использования, принадлежности к социальной группе и т. п. Говоря о памяти автора, следовало бы получить профиль по времени по всем параметрам, которые мы указали выше.
Но самое интересное то, что для создания полноценного перевода нам нужно иметь профиль читателя в тех же координатах! Но это неразрешимая задача, а потому остаётся выбрать некий набор параметров, аналогичных применённым к автору, а затем формировать профиль читателя в рамках нечёткой логики. И только после этого делать перевод.
И вот тут становится ясно, что получится вовсе и не перевод, а адаптированный к уровню подготовки и жизненному опыту группы читателей текст.
В принципе, логично в такой ситуации переводить текст на внутренний метаязык системы в существенно избыточном варианте, включая в него не только материал автора, но и фрагменты модели и памяти социума, а также профиль автора. Ну а затем, уже используя образ текста на метаязыке, излагать его с учётом модели и памяти как социумов, так и автора с читателем.
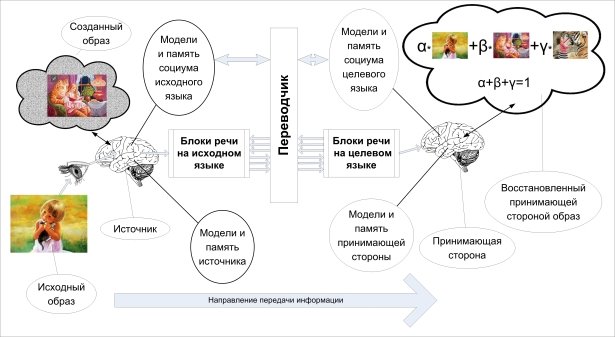
Рис. 2. Схема однонаправленного перевода с обратной связью
После этого можно ожидать получения более или менее адекватного перевода текста, адаптированного к времени, социуму и возможностям читателя.
Надо отметить, что так поступают опытные переводчики. Они не переводят текст по предложениям до того, как не сформируют для себя полный профиль автора и читателя. Конечно, предполагается, что модели и память социумов обеих сторон также известны переводчику.
Рассмотрим теперь перевод с обратной связью, схема которого показана на Рис. 2.
Разница с предыдущей схемой в том, что сторона источника доступна для контакта и может отвечать на уточняющие вопросы стороны принимающей стороны.
Фактически мы имеем процесс перевода (передачи информации) с обратной связью. Совершенно неважно, на разных или одинаковых языках говорят стороны, важно то, что в процессе обменов на принимающей стороне формируется образ, который должен быть адекватен исходному.
На схеме (Рис. 2) хорошо видно, что получить идентичность исходного и восстановленного образа проблематично, поскольку он формируется теперь из исходного, созданного на стороне источника и восстановленного на принимающей стороне с весовыми коэффициентами α, β и γ. Идеально было бы, чтобы весовой коэффициент α был максимально близок к единице, что вряд ли достижимо даже при совпадении языков сторон из-за того, что модели и память автора и читателя не могут быть идентичными.
Обмен информацией в диалоге
Обмен информацией в двустороннем режиме (duplex) предполагает наличие возможности перевода в обе стороны, а сам процесс может использовать обратные связи для уточнения и корректировки корректности, получаемой сторонами информации.
Начнём с того, что не существует диалога «вообще», а существует множество видов диалога, каждый из которых соотносится с различными видами коммуникаций. В литературе существует множество определений видов диалога [11,12,13], различающихся между собой по ряду признаков.
Простейшая классификация видов диалога даёт 6 вариантов (3 симметричных и 3 с активными-пассивными сторонами).
Симметричные диалоги:
– этикетный, бытовой, заполнение временного интервала;
– обмен мнениями, согласование позиций;
– переговорный с целью достижения общей цели.
Активно-пассивные диалоги:
– побуждение, команда, стимулирование;
– расспрос, допрос, получение необходимой информации;
– критика, осуждение, воспитательные действия.
Обычно в литературе выделяют разные группы диалога в зависимости от того, какие позиции занимают стороны в социуме:
– равноправные участники;
– подчинённость одного из участников;
– отсутствие связей в социуме между участниками.
К тому же коммуницирующие стороны могут иметь различия в уровне когниции:
– когниции участников имеют близкие уровни;
– один из участников имеет уровень когниции намного выше второго;
– когниции участников неравноценны по объёмам знаний и скорости обработки информации.
Даже при такой, предельно упрощённой, классификации имеем 54 варианта. А если начать анализировать более подробно, то количество вариантов увеличится в десятки раз. Именно этим и объясняется огромное количество определений диалога, которые можно найти в литературе.
Односторонний перевод текста и двусторонний в реальном времени перевод диалога существенно различаются как по внутренней организации, так и по требованиям к качеству перевода. Связано это с тем, что в диалоге есть возможность уточнить полученную информацию и методом последовательных приближений достичь максимально точной передачи образа, то есть увеличить α до максимального значения.
Диалог между человеком и квазиживой системой с когницией
Почему в поставленной задаче взаимодействия человека и квазиживого объекта важно разобраться как в переводе речи человека для когнитивного процессора системы, так и в обратном переводе? Дело в том, что мы должны организовать диалог, в котором одна из сторон представляет внешний мир, а другая — внутренний мир объекта. Более корректно это выглядит следующим образом.
Человек имеет информацию об окружающем мире, социуме, в котором обитает, знания о прошлом и задачи на будущее. При этом он представляет для квазиживого объекта человеческий социум, которому подчинён объект. И последним важным фактором является то, что по когнитивным возможностям (скорости обработки и объёму информации) человек уступает во много раз (а то и порядков) объекту управления. Речь, конечно, идёт о будущем, когда квазиживой объект получит полноценный когнитивный аппарат — то есть не ранее вступления мира в седьмой технологический уклад.
Схема взаимодействия между человеком и когнитивным процессором квазиживого объекта показана на Рис. 3.
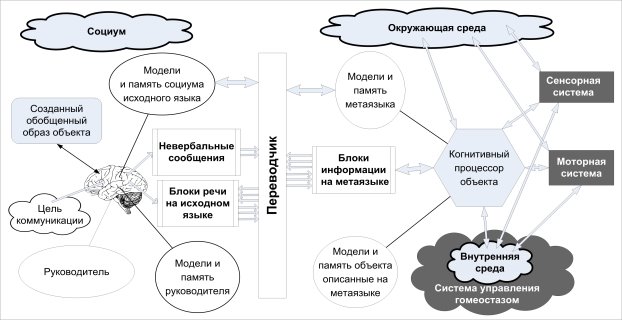
Рис. 3. Схема организации диалога между человеком и квазиживым объектом
В данном случае необходимо организовать двусторонний перевод диалога, при котором активной стороной является человек. Цель диалога для человека сводится к получению необходимой информации о состоянии объекта в целом и его подсистем, а затем выдаче команд и/или рекомендаций на последующий период времени. Язык диалога для человека — это, безусловно, тот, которым он хорошо владеет, а для квазиживого объекта — некий универсальный метаязык. Кроме обычного языка в виде текста или речи, переводчик обязан понимать и интерпретировать и невербальные коды человека, в частности жесты, касания экрана, направление взгляда и тому подобное. Требования к такому метаязыку обсудим в следующем разделе.
При этом важно осознавать, что скорость обработки информации и принятия решений когнитивного аппарата квазиживого объекта несопоставимо выше, чем у человека, а потому роль последнего практически равна нулю при решении задачи поддержания гомеостазиса и управления. А потому на человеке лежит лишь взаимодействие с окружающим миром и постановка задачи на следующий этап жизнедеятельности.
В обратном направлении, то есть от объекта к человеку, должна идти генерализированная, то есть максимально обобщённая информация о состоянии компонентов, запасах ресурсов и существующих или ожидаемых проблемах. Любая другая информация просто не может быть воспринята человеком за разумное время.
Метаязык и переводчик для когнитивного процессора
На настоящий момент существующие метаязыки не имеют общепринятой архитектуры и различаются по своим исходным параметрам:
– взятым за основу языком «первого уровня»;
– трактовкой «значения предложения»;
– полнотой описания значения любого предложения средствами метаязыка;
– набором словарей;
– грамматикой метаязыка.
Рассмотрим требования и предполагаемые особенности метаязыка и программно-аппаратного комплекса (условно названный переводчиком), который был бы ориентирован на общение с квазиживой системой.
Полнота и избыточность.
Нам не нужно, чтобы метаязык был полон, то есть он не должен быть знаковой системой, содержащей все возможные комбинации элементов из заданного множества [14].
С другой стороны, нет смысла и бороться с избыточностью, которая раньше считалась недопустимой для метаязыков, предназначенных для диалога человек-машина. Избыточность метаязыка для квазиживой системы позволит ей в дальнейшем развиваться и эффективно обучаться.
Неполнота и избыточность присутствуют также и в естественных языках. И если неполнота позволяет языку развиваться, то избыточность увеличивает надёжность (снижает вероятность ошибок) при передаче информации.
Типы обрабатываемой информации.
Метаязык для общения с когнитивными системами, обладающими практически неограниченными (по сравнению с человеком) логическими способностями, должен иметь возможность оперировать с неограниченным спектром типов информации, которая может быть эксплицирована и использована когнитивным процессором квазиживого объекта. При этом глубина импликации соответствующих фрагментов информации должна быть также практически неограниченной, поскольку без этого у когнитивного процессора не получится добиться полноценного понимания смысла предложения-высказывания человека. Естественно, что это должно быть выстроено на гибкой платформе, позволяющей системе обучаться.
Обработка невербальной информации.
Важно, чтобы переводчик имел также словари невербальных кодов, в частности связь между понятиями на метаязыке с жестами, касаниями экрана, направлением взгляда и тому подобное. Соответственно, указанные коды могут различаться не только для социумов, но и для конкретных людей. Последнее крайне важно для того, чтобы обеспечить однозначность обработки команд руководителя. Любая ошибка, к примеру на АЭС, может быть фатальной.
Мультиязычность метаязыка.
На сегодня такие проблемы не возникали, поскольку метаязыки привязывались к исходному языку. В случае работы с квазиживым объектом совершенно естественно, чтобы команды отдавались на родном языке руководителя, так же, как и поступающая к нему информация от когнитивного процессора системы.
Представляется наиболее вероятным, что мультиязычность будет строиться на основе расширения метаязыка, уже собранного на базе одного из наиболее разработанных языков (например, русского или английского), а затем он будет пополняться либо полным комплектом очередного языка, либо связками на основе нечёткой логики. То есть в первом варианте — вложением структур второго языка с полным их сохранением, а во втором — с указанием связей с базовым.
Учёт моделей и памяти социума.
Следующим важным компонентом системы обработки потока информации переводчиком должен быть доступ к набору описаний моделей социума и участвующих в диалоге людей. Очевидно, что они будут более или менее едины для больших групп, но также должны корректироваться по мере развития социума. В общем случае модели могут быть как внешними модулями переводчика, так и встроенными с возможностью расширения и дополнения.
Память социума тоже важна, поскольку без неё информация, предназначенная для объекта управления, не будет корректно эксплицирована. Объем её велик, поскольку информация долэна не только включать в себя совокупность наработанных устойчивых стереотипов, но и их историю.
При расширении метаязыка путём внедрения мультиязычности потребуется хранить и наборы описаний моделей социума, которые присущи каждому внедряемому в метаязык исходному языку.
Возможность обмена опытом.
Отметим, что устройство «переводчика» должно быть таким, чтобы это позволяло осуществлять обмен «опытом» между «переводчиками», причём не путём замены баз данных, а взаимного обогащения за счёт накопленных при функционировании и самообучении фрагментов. Таким образом, каждый переводчик мог бы пополнять базы остальных своим опытом. Как это организовать — вопрос будущего, но уже ясно, что это потребует либо мощного ЦОД, либо облачных сервисов.
Естественно, что для этого потребуется обеспечить их защищёнными каналами связи, что на самом деле уже достаточно просто.
Учёт модели и памяти руководителя.
В любой структуре, требующей централизованного управления, личность руководителя играет большое значение. Это верно для первобытного общества и для суперсовременного производственного комплекса. И тут возникает две совершенно независимых проблемы.
А. Идентификация иаутентификация.
До настоящего времени доступ к любой конфиденциальной информации предполагал предварительную идентификацию и аутентификацию пользователя. Технологии идентификации и аутентификации на сегодня уже достаточно развиты. В комплексе с аудио- и видеоконтролем окружающей обстановки можно добиться практически 100 % исключения несанкционированной выдачи команд управления объектом.
На сегодняшний день уже может использоваться система распознавания лица по видеокартинке. Остаётся только аутентификация собеседника, которая со временем также станет простейшей процедурой.
Фактически двухфакторную аутентификацию (2FA) давно используют. В основе двухфакторной аутентификации лежит модель, которая требует, чтобы пользователь имел два из трёх типов идентификационных данных:
– нечто, ему известное (код, пароль);
– нечто, у него имеющееся (токен, ключ, сотовый телефон);
– нечто, только ему присущее (биометрические параметры).
В будущем пароль и код, очевидно, станут анахронизмом, поскольку даже в вариативной MFA (Multi-factor authentication) можно использовать биометрические параметры, которые могут быть считаны быстро и достаточно надёжно:
– распознавание лица по видеокартинке;
– распознавание тембра голоса по произносимым стандартным фразам;
– сканирование ладони видеокамерой системы (пропорции пальцев);
– сканирование радужной оболочки глаза;
– соответствие времени и места входа в диалог (терминал, помещение…), согласно заранее оговорённым требованиям.
В результате руководитель и его полномочия могут проверяться в любой момент, особенно при выдаче критических команд.
Б. Учёт личностных особенностей.
Модель поведения руководителя, его словарный запас, используемые обороты речи также могут быть использованы системой перевода для повышения надёжности и точности приёма руководящих указаний.
В данном случае необходимо заранее сформировать набор параметров по основным характеристикам, в частности, типичные для данного человека формулировки, словарный запас, используемые идиомы, склонность к использованию образных выражений, терминологические поля и тому подобное.
Однако и на момент диалога также целесообразно выстраивать текущий профиль руководителя, например эмоциональный уровень, самочувствие, благодушное или озлобленное состояния и ещё целый ряд параметров, актуальных только на текущий момент диалога.
Построенный по подобной схеме метаязык совершенно бесполезен без «переводчика», который хранит модели и память социумов потенциальных руководителей, а также умеет подстраиваться под каждого конкретного человека, которому социум доверит руководство объектом.
Использование метаязыка для обработки текстов на естественных языках
Построенный для ведения диалога между человеком и квазиживой системой с когницией комплекс из переводчика, набора баз и метаязыка может быть использован совершенно неожиданным образом.
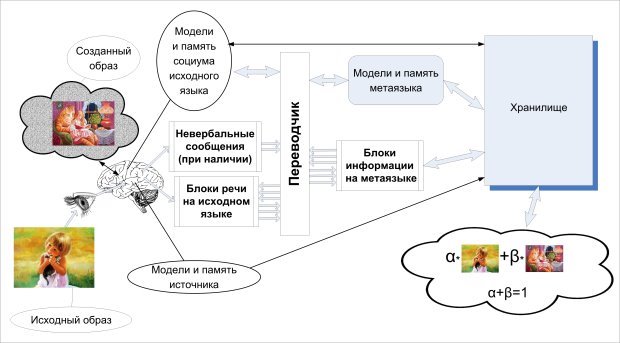
Рис. 4. Перевод на метаязык
Возьмём текст и прогоним его через переводчика, который преобразует его в код метаязыка. При этом, сохраним в базе вместе с текстом на метаязыке также блок данных (или отсылку к нему), который содержит информацию о модели и память социума на момент создания текста, а также информацию о модели и памяти источника (создателя текста). По возможности можно использовать и невербальную информацию, например если текст зачитывают вслух или есть видеоролик с авторским текстом. Схема работы переводчика с исходного (естественного) языка на метаязык показана на Рис. 4.
В результате получится весьма объёмный по нынешним представлениям материал, но, поскольку возможности хранилищ информации и производительность процессов растут экспоненциально, это скоро не будет проблемой.
При рассмотрении задачи перевода практически во всех известных моделях отталкиваются от того, что переводиться должно предложение или его часть, если оно составное. В данной схеме выделение фреймов также необходимо, но они совершенно не обязаны быть жёстко привязаны к предложениям. Это могут быть фрагменты любого размера, вплоть до текста в целом. Более того, это могут быть предложение и фрагменты описаний из основного текста.
Как это можно визуализировать? Если мы строим метаязык на основе естественного, а затем, переводя на него, фактически присваиваем веса всем мыслимым комбинациям в цепочках, то фактически мы вводим некий базис, в котором существительные становятся главными компонентами, а присваиваемые им свойства задаются в локальной системе отсчёта существительного. То есть мы приходим к фазовому пространству, в котором описываемый объект становится точкой (а точнее, облаком, ввиду невозможности полностью описать его состояние).
В таком случае простейший фрейм текста описывает положение этого облака и его форму. Естественно, следующим шагом будет выделение фрейма, описывающего окружающую среду.
Например, возьмём предложение: «Мушкетёр устало брёл по засыпающему маленькому средневековому городу». Тут мы имеем два фрейма в одном предложении. Один описывает среду, а другой — объект и его состояние. Могло быть и иначе: несколько предложений описывало бы состояние мушкетёра, а между ними рассказывалось бы о времени действия и городе. В любом варианте мы получили бы в нашем фазовом пространстве область, соответствующую городу и его состоянию, и облако, описывающее объект — мушкетёра.
Следующий шаг — фрейм, описывающий изменения либо самого объекта при неизменности окружающей среды. Например, возьмём фрагмент текста: «И тут ему на голову нагадила птичка, и он посмотрел вверх». Положение героя в фазовом пространстве не изменилось, а состояние — существенно. То есть изменилась форма облака, описывающего его состояние.
Иной вариант — изменилось место пребывания объекта. В фазовом пространстве это описание перемещения облака объекта в целом.
Практически любые процессы, происходящие с объектом, сведутся к изменению облака, описывающего его внутренние изменения и положения в окружающей среде.
Таким образом, мы получаем эвентуальную мировую линию объекта в фазовом пространстве и пространстве-времени.
Объектов может быть несколько, и тогда у каждого будет своя эвентуальная мировая линия. Новым же будет взаимодействия между собой объектов как парные, так и групповые. При этом совершенно не важен тип взаимодействия — реальный или виртуальный контакт.
Интересно теперь взглянуть на тексты, которые могут быть отработаны и переведены на метаязык в рассматриваемой модели. Роды литературы в нашем рассмотрении не интересны, а вот попытаться классифицировать виды (или жанры) вполне возможно [15,16]. Конечно, детально разбирать каждый жанр нет смысла, поскольку нам важно убедиться в работоспособности подхода, а не решать глобальные проблемы лингвистики.
Возьмём для примера самые часто используемые жанры:
– рассказ, новелла, очерк или миниатюра — представляют собой описание короткого отрезка эвентуальной мировой линии одного или небольшого числа взаимодействующих объектов с незначительными перемещениями в пространстве и времени;
– повесть — представляет собой достаточно большой отрезок эвентуальной мировой линии нескольких взаимодействующих объектов с существенными перемещениями в пространстве и времени;
– роман и роман-эпопея — представляют собой большой отрезок эвентуальной мировой линии множества взаимодействующих объектов с существенными перемещениями в пространстве и времени. При этом эвентуальная мировая линия отслеживается для главных героев от начала до её конца.
Внутреннее деление жанров весьма широко, но в данном случае оно выходит за пределы нашего исследования.
Помимо самого обработанного текста, в базе должна сохраняться информация о социуме, в котором происходят те или иные действия. С точки зрения рассматриваемой модели, информация о социуме уточняет, а порой и определяет положения объекта в окружающей среде, поскольку автор может вообще не включать сведения о социуме в свой текст, полагая, что это известно читателю по умолчанию.
С другой стороны, важна также полная информация об авторе. Очевидно, что, находясь внутри социума или вовне, автор совершенно по-разному опишет происходящее. Визуализировать такое можно, представив, что автор заходит с разных сторон баррикады, а описывает одно и то же событие.
Восстановление текста
Теперь мы можем попытаться выполнить обратную процедуру — перевод с метаязыка на любой другой целевой язык. Схема подобного перевода проста и показана на Рис. 5. Перевод производится достаточно просто, если есть модель и память метаязыка. Точность такого одностороннего перевода заведомо выше, чем в классической схеме, показанной на Рис. 1, потому что при кодировании уже учтены модель и память автора исходного текста.
Однако, если заранее собрать модель читателя, особенно с учётом его реального статуса, то точность перевода вырастет ещё больше.
Собственно говоря, мы можем при этом рассчитывать на максимальное значение α в восстановленном образе.
На первый взгляд мы получили крайне усложнённую схему перевода, которую нереально создать быстро при существующих хранилищах и производительности процессоров — либо затраты станут запредельными. Более того, по мере развития как средств обработки и хранения информации, так и программного продукта, мы можем ожидать существенного улучшения качества перевода с использованием нейросетей.
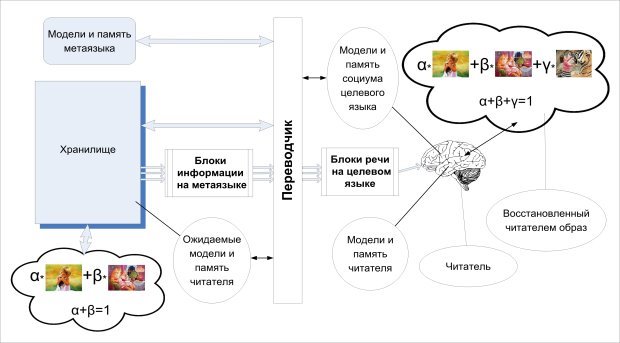
Рис. 5. Перевод на естественный язык читателя
Однако посмотрим с другой стороны на то, что получилось. Мы получили в некий программный продукт, который способен обработать и перевести на метаязык любой текст, а затем преобразовать его в текст на любом языке, при этом адаптируя его к некому среднему по выбранной группе читателю. Более того, если потребуется, то можно адаптировать текст для любого конкретного индивида. При этом, помимо исходного теста, хранится и информация о социуме, то есть существенно уточняется положение объектов и героев в фазовом пространстве и пространстве-времени, а также информация об авторе, что тоже важно для понимания, с какой позиции описываются события и взаимодействия героев.
А теперь перейдём к самому интересному. Система перевода не только имеет информацию о происходившем значительно более широкую, чем это описано автором, но и способна учесть особенности социума читателя и, что ещё важнее, его индивидуальные свойства.
Никакие переводчики в классической схеме этого в принципе не способны сделать просто потому, что адаптация к читателю никогда не предполагалась в их работе, как у ручного перевода, так и, тем более, машинного.
Фактически мы получили технологию перевода с использованием мультиязычного метаязыка, которая позволяет оптимально подстроить перевод под группу читателей или даже индивида. Это можно сравнить с адаптивным изложением материала, а не просто с переводом, поскольку исходный язык и целевой могут даже совпадать. При этом гарантируется не просто передача материала, но и устранение мелких ошибок или опечаток автора, которые практически всегда присутствуют в текстах.
Применение подобных систем может дать серьёзный прорыв в библиотечном деле. Каждый читатель может, создав свой профиль, получать из хранилища текст, который способен полноценно понять.
Где такое может быть применено? В первую очередь, для ознакомления детей по мере их взросления с классикой и научной литературой, которая не может быть правильно воспринята просто из-за нехватки знаний. При этом гарантируется предельно близкая к оригиналу передача информации с учётом возможностей читателя.
Не менее полезная задача, решаемая на таком пути, — это получение выжимки из текста, с минимизацией избыточности, или удаление эмоциональной нагрузки исходного материала.
Перенос и деформации текста
Есть ещё одно интереснейшее применение обсуждаемой технологии. При наличии текста, переведённого на метаязык, он может быть не просто переведён на целевой язык с учётом уровня читателя и социума, к которому он принадлежит, но и преобразован.
Рассматривать будем только деформации без изменений исходного материала, поскольку иное будет означать создание нового текста на безе имеющегося.
Итак, что можно преобразовывать, не трогая вообще исходный текст? Есть четыре основных компоненты, которые можно менять, — модель и память, причём как социума, так и индивида обеих сторон — источника и читателя. Вариантов множество, причём надо понимать, что будут и парные, и тройные преобразования, да и вообще все четыре можно менять. При этом уровень корректировки может быть различный.
Фактически это перенос материала в другую среду и изменение точки наблюдателя…
В качестве примера можно заметить, что фантастические произведения в большинстве своём создаются путём конформного отображения траекторий объектов и героев в фазовом пространстве из настоящего либо в прошлое или будущее, либо в иную культуру, либо в придуманные автором миры. Обусловлено это тем, что создать иной мир легко, а когнитивные процессы и взаимодействия объектов — крайне сложно. По сути, это просто использование одного и того же сюжета в разных декорациях. Либо смена наблюдателя, что также может давать существенно новое представление о происходящем.
Вариант с корректировкой материала под уровень подготовки читателя мы уже рассмотрели в предыдущем разделе.
Есть ещё три интересные возможности получить новый вариант прочтения — это преобразования облаков объектов, траекторий в фазовом пространстве и правил взаимодействия пар. Это процедуры можно назвать деформациями, причём качественно разных видов — объекта, траектории и парных взаимодействий.
Так, например, деформация облака героя может сделать из милого пупсика свирепого монстра, деформация траектории — получить новое прочтение материала, а изменение правил взаимодействия пар — перестроить процессы перехода между точками на эвентуальных мировых линиях объектов.
Заключение
Создаваемый искусственный интеллект, который со временем будет управлять открытыми системами, в частности, производственными комплексами или сетецентрическим оружием, приведёт к возникновению объектов, обладающих когнитивными способностями. Поскольку законы развития для открытых систем едины, то используется термин — квазиживые системы.
В связи с необходимостью взаимодействия человека с квазиживыми системами, имеющими вначале зачатки, а в дальнейшем и полноценный когнитивный аппарат, потребуется создание «переводчика», позволяющего в режиме диалога с минимальными потерями обмениваться информацией. Роль человека в такой паре — стратегическое руководство, поскольку функционирование, поддержание гомеостазиса и прочая деятельность, направленная на выполнение стоящих перед системой задач, будет полностью управляться самим квазиживым объектом.
В работе предполагается, что строить подобный переводчик придётся на нечёткой логике с использованием метаязыка. В процессе формирования требований к программному продукту проанализированы процессы перевода текста (simplex) и диалога (duplex) и установлено, что классические методики в данном случае могут оказаться неудовлетворительными, поскольку не учитывают модели и память, как сторон диалога, так и социумов сторон.
Построенный на основе перевода в промежуточный внутренний метаязык переводчик может оказаться полезен и для переводов текстов на естественных языках.
Более того, при подобном построении возможно не только обеспечить адаптацию текста в зависимости от уровня и знаний читателя, но преобразовать текст с учётом особенностей социума, как автора, так и читателя. Применение подобного алгоритма крайне интересно для создания обучающих материалов, настраиваемых индивидуально для любого читателя.
Интересна также и возможность планомерно видоизменять любой художественный текст, деформируя по-отдельности как облака свойств объектов, так и их эвентуальные мировые линии или параметры взаимодействия.
Литература:
- Жеребило Т. В. Словарь лингвистических терминов. 5-е изд., испр. и доп. — Назрань: Пилигрим, 2010
- Энциклопедический словарь. /Под редакцией А. А. Ивина. — М.: Гардарики, 2004.
- Языкознание. Большой энциклопедический словарь / Гл. ред. В. Н. Ярцева — 2-е изд, — М.: Большая Российская энциклопедия, 1998.
- Баранов А. Н. Введение в прикладную лингвистику. — М., 2001.
- Зубов А. В., Зубова И. И. Основы искусственного интеллекта для лингвистов. — М., 2007.
- Обзор систем машинного перевода // Мокрушин А. А., Андреева А. Д., Меньшиков И. Л. «Молодой учёный», 12 (59), 2013
- Комиссаров В. Н. Теория перевода. — М.: Высшая школа, 1990
- Виноградов В. С. Введение в переводоведение (общие и лексические вопросы). — М.: Изд-во института общего и среднего образования РАО, 2001.
- Гридина Т. Л., Коновалова II. И. Современный русский язык. Словообразование: теория, алгоритмы анализа, тренинг: учеб, пособие. 2-е изд. — М.: Наука: Флинта, 2008
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio. // Cornell University, 2014 URL: https://arxiv.org/abs/1406.1078
- Виноградов В. С. Введение в переводоведение (общие и лексические вопросы). — М.: Изд-во института общего и среднего образования РАО, 2001.
- Назарчук А. В. Теория коммуникации в современной философии. — М.: Прогресс-Традиция, 2009
- Maranhão, Tullio. (1990). The Interpretation of Dialogue. University of Chicago Press. — ISBN 0–226–50433–6.
- Толковый переводоведческий словарь. — 3-е издание, переработанное. — М.: Флинта: Наука. Л. Л. Нелюбин. 2003.
- Какие жанры есть в литературе, URL: https://brainapps.ru/blog/2017/10/kakie-zhanry-est-v-literature/
- Литературные жанры в таблицах, URL: https://pishi.pro/kak-stat-pisatelem/teoriya-literatury/90-literaturnye-zhanry-v-tabliczah.html
