





В статье описывается процессы обработки естественного языка, виды шкал определения тональности, подходы к определению тональности текста и методы оценки качества тональности текста.
Ключевые слова: обработки естественного языка, анализ тональности.
Обработка естественного языка — направление машинного обучения и компьютерной лингвистики, направленное на изучение проблемы синтеза естественных языков и компьютерного анализа. Основными направлениями обработки естественного языка являются: распознавание речи, генерация естественного языка и понимание естественного языка.
В обработке естественного языка применяется предобработка текста в формат удобный для дальнейшей работы. К примеру:
– Перевод всех букв к верхнему или нижнему регистру;
– Удаление цифр;
– Удаление пунктуации;
– Удаление стоп-слов;
Стемминг — процесс выделения основы слова. Альтернатива для русского языка: лемматизация — приведение слова к одинаковой форме:
– для существительных — именительный падеж, единственное число;
– для прилагательных — именительный падеж, единственное число, мужской род;
– для глаголов, причастий, деепричастий — глагол в инфинитиве несовершенного вида.
– Векторное представление слов — для документа создается вектор размерности словаря, в него записывается насколько часто слово встречается в документе.
Анализ тональности
Анализ тональности — класс методов анализа текстовых данных, предназначенный для определения эмоциональной окраски текста и в нахождении эмоциональной оценки авторов по отношению к объектам, речь о которых идет в тексте.
Виды шкал для определения тональности
В области анализа тональности текста, как правило, использую одну из следующих шкал разделения текстов по тональности:
1) Бинарная шкала
2) Два класса оценок: позитивная и негативная. Минус данного подхода в том, что не во всех случаях удается однозначно определить к какому классу относиться документ: текст может содержать признаки позитивной и негативной оценки одновременно.
3) Многополосная шкала
4) Расширение задачи классификации документов от оценки “положительный или отрицательны” в сторону трех и четырех бальной системе оценки.
5) Системы шкалирования
6) Словам ставится в соответствие числа по какой-то шкале, например, от
7) —10 до 10 (от резко негативного до резко положительного). Текст анализируется инструментами обработки естественного языка, затем найденные термины изучаются с целью понимания значения этих терминов.
Подходы копределению тональности текстов
В проблеме анализа тональности существует два основных подхода: лексический подход и подход машинного обучения. В лексическом подходе определение тональности основано на анализе отдельных слов, используются эмоциональные словари [1]: в тексте ищутся эмоциональные лексические элементы из словаря, веса их тональности уже подсчитаны, и применяется некоторая агрегированная весовая функция для определения тональности текста на основе всех элементов.
Задача извлечения тональности текста с помощью машинного обучения рассматривается как общая проблема классификации текста [2] — деятельность по маркировке текстов на естественном языке тематическими категориями из предопределенного набора, в ней применяются заранее размеченные по тональности корпусы данных, на которых происходит обучение модели, которая в дальнейшем используется для классификации.
Формальная постановка задачи классификации текста:
Имеется множество классов ![]()
Имеется множество документов ![]()
Неизвестная целевая функция ![]()
Необходимо построить классификатор
У каждого подхода есть свои преимущества и недостатки. Лексическому подходу не нужны размеченные по тональности корпусы данных и процедура обучения, следовательно, решения, принятые классификатором, легко объяснимы. Однако необходимы огромные лингвистические ресурсы, такие как эмоциональный словарь. Так же термины словаря должны иметь вес, адекватный предметной области документа. Например, слово «большой» по отношению к размеру мобильного телефона является отрицательной характеристикой, но положительной по отношению к объему памяти жёсткого диска.
При машинном обучении словарь не требуется, и на практике методы демонстрируют высокую точность классификации. Но классификатор, обученный для одной области, в большинстве случаев не работает в других.
Оценка качества анализа тональностей
Для того чтобы понять, насколько хорошо построенный алгоритм работает с данными, необходима численная метрика его качества. Для каждого класса отдельно составляется таблица классификации.
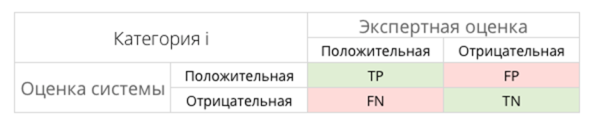
1) TP — истинно-положительное решение;
2) TN — истинно-отрицательное решение;
3) FP — ложноположительное решение;
4) FN — ложноотрицательное решение.
- Полнота (Recall)
- Полнота системы — это доля найденных классификатором документов, принадлежащих классу относительно всех документов этого класса в тестовой выборке.
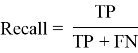
- Точность (Precision)
- Точность системы в пределах класса — это доля документов, действительно принадлежащих данному классу относительно всех документов, которые система отнесла к этому классу.
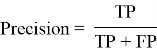
- F-мера (F-measure)
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
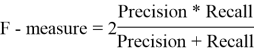
- Cross-validation
- Для оценки качества классификации используется метод кросс-валидации (cross-validation) — данные делятся на k частей. Затем на k-1 частях производится обучение модели, а оставшаяся часть используется для тестирования. Процедура повторяется k раз и в итоге каждая из k частей данных используется для тестирования.
Литература:
- Pang, B., Lee, L. Opinion Mining and Sentiment Analysis // Foundations and Trends® in Information Retrieval. Vol. 2. 2008. P. 1–135.
- Sebastiani F. (2002), Machine learning in automated text categorization, ACM Computing Surveys, Vol. 34, P. 1–47.
