





В данной работе рассказывается о проблеме «холодного старта» в рекомендательных системах.
Ключевые слова: бандитский алгоритм, машинное обучение, ACM, CTR.
Каждый день мы сталкиваемся с различными сайтами и социальными сетями. Все эти сервисы, предоставляя интересный контент, стремятся максимально угодить пользователям. Такие ресурсы изменяют свое содержание и наполнение, подстраиваясь к предпочтениям каждого конкретного пользователя. Одним из решений задач персонализации контента являются рекомендательные системы.
На сегодняшний день существует несколько подходов к построению таких систем: коллаборативная фильтрация [1], MAB (Multi-Armed Bandits) [2], графовые методы [3] и т. д. Так или иначе многие из этих подходов сводятся к задачам машинного обучения по имеющейся истории взаимодействий, выбирающих наиболее релевантный контент. Однако во многих ситуациях такой истории нет, например, для новых пользователей, и рекомендательная система не может дать качественный прогноз для данного пользователя. Это и называется проблемой «холодного старта». Далее будут рассмотрены некоторые вышеперечисленные методы в контексте проблемы «холодного старта». Необходимо для данной группы пользователей и ресурсов построить адекватные рекомендации.
Бандитские алгоритмы
Подробнее остановимся на алгоритмах многоруких бандитов из-за их малоизученности и специфичности применения.
Представим, что перед нами стоит N различных игровых автоматов. При нажатии на ручку мы получаем какой-то выигрыш. Необходимо максимизировать суммарную прибыль всех нажатий на ручки. Задача заключается в нахождении оптимального способа выбора ручки на очередном шаге. Математически это можно записать так:
A — множество доступных действий («ручек»);
![]() — контекст (информация об объектах и/или пользователях) на определенном шаге. Он определяется средой, в которой рассматриваются многорукие бандиты;
— контекст (информация об объектах и/или пользователях) на определенном шаге. Он определяется средой, в которой рассматриваются многорукие бандиты;
![]() — реальная награда, наблюдаемая на шаге t.
— реальная награда, наблюдаемая на шаге t.
![]()
![]()
![]()
В данной работе рассмотрены некоторые виды алгоритмов многоруких бандитов, а именно UCB1 и ε-greedy [4], disjoint-linUCB и hybrid-linUCB [2]. Проверка их эффективности проводилась на примере задачи Yahoo! [5] по рекомендации новостей пользователям. При этом использовалась метрика CTR (отношение числа кликов к числу показов). Результаты приведены на рисунках 1, 2.
При этом во время работы алгоритмов считалось, что изначально все объекты и пользователи являются новыми для системы, т. к. до старта алгоритмов не использовалась никакая информация об истории показов. Вся работа методов основана на статистических данных и признаковых представлениях объектов и пользователей (только для контекстных алгоритмов).
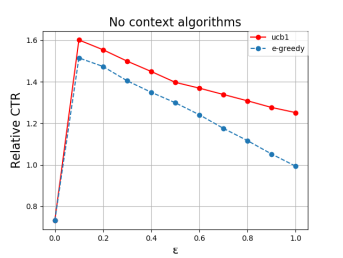
Рис. 1: Бесконтекстные алгоритмы
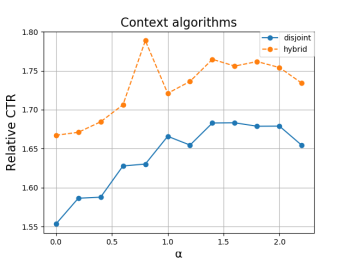
Рис. 2: Контекстные алгоритмы
«Холодный старт» в рекомендательных системах.
Как уже упоминалось ранее, проблема «холодного старта» является одной из основных задач, возникающих при построении рекомендательных систем: что рекомендовать новым пользователям и кому показывать новые объекты. В бесконтекстных алгоритмах эта задача решается с помощью накопленной статистической информации. В частности, новому пользователю чаще всего будут показаны наиболее популярные объекты (с большим значением
Заключение
В результате проведенного исследования выявлено, что бандитские алгоритмы достаточно хорошо справляются с проблемой холодного старта. Это видно на рисунках, демонстрирующих эффективность алгоритмов. Также стоит заметить, что данные методы работают хорошо и для старых объектов. В дальнейшем будет продолжено исследование в области применения класса многоруких бандитов с более сложными моделями как для задач рекомендации, так и в новых областях науки и человеческой деятельности.
Литература:
- MachineLearning.ru — профессиональный информационно- аналитический ресурс, посвященный машинному обучению, распознаванию образов и интеллектуальному анализу данных. [Электронный ресурс]: URL:http://www.machinelearning.ru (дата обращения: 17.06.19).
- Li L., Chu W., Langford J., Schapire R. E. A contextual-bandit approach to personalized news article recommendation // Proceedings of the 19th International Conference on World Wide Web. 2010. P. 661–670.
- Musical recommendations and personalization in a social network // Proceedings of the 7th ACM Conference on Recommender Systems. 2013. P. 367–370.
- Auer P., Cesa-Bianchi N., Fischer P. Finite-time analysis of the multiarmed bandit problem // Machine Learning. 2002. Vol. 47. No 2–3. P. 235–256.
- Yahoo! Front page today module user click log dataset, version 1.0 (1.1 GB) [Электронный ресурс]: URL:https://webscope.sandbox.yahoo. com/catalog.php?datatype=r&did=49 (дата обращения: 17.06.19).
