





Одним из самых быстрых и удобных способов перевода информации из физического формата в электронный вид является сканирование документов. Результатом данного процесса будет электронный файл, представленный в виде графического изображения. Графическое изображение не позволяет производить необходимый набор действий, как при работе с текстом, что делает его менее функциональным. Основные отличия хранения текстовой информации, в отличии от графической: экономия затрат на хранении, более обширный список сценариев использование документа.
OCR — это система оптического распознавания символов. В настоящее время данная система имеет большую популярность, она применяется в большом количестве программ, связанных с распознаванием текста.
Алгоритм работы распознания текста всегда строится одинаково.В систему загружается отсканированный файл, представленный в виде растрового изображения страницы документа. Качества изображения играет важную роль в распознании текста: чем выше качество, тем выше точность. Поэтому первым этапом будет являться обработка поступившего изображения: снижение шума, повышения контраста, повышение резкости, бинаризация изображения, выравнивание угла наклона [1].
Обработанный файл передается в модуль сегментации, задачей которого является выявление структурных единиц текста — страниц, строк, слов и символов. После сегментации полученные данные собираются в обратном порядке в готовый файл.

Рис. 1. Порядок сегментации
Для начала документ делится на страницы, далее определяются текстовые блоки. Для выявления слов из текстового блока производится определение угла наклона текста, для уменьшения будущих погрешностей, поиск вертикальных просветов в тексте, показывающих границы слова [2].
Для разбивки слова на символы проводится аналогичный процесс, только с меньшими просветами. Данные операции будут более точными, если текст будет черного цвета на белом фоне, если оригинальный текст иного цвета, то применяется бинаризация изображения.

Рис. 2. Пример входного текстового блока
На выходе из модуля сегментации будут получены данные, в состав которых входят структуры и местоположение текстовых блоков на странице, строки в этих блоках и их сегментация на слова и символы. Данные могут содержать не только информацию об обычном текстом блоке, а также о колонках, таблицах и т. д.

Рис. 3. Пример обработанного текстового блока
Определенные фрагменты слов и символов отправляются в модуль классификатора, результатом работы которого будет являться информация о принадлежности символа к определенной букве или символу. Нейронная сеть для каждого входящего символа, используя его пиксельное изображение, определяет признаки принадлежности буквы к нечеткому множеству.
После определения признаков у символа начинается процесс составление из символов слов. Для этого нейронная сеть сравнивает возможность написания отдельных букв, частоту сочетаний букв в языке, производится проверка по модели слова и словарю [3].
Модель слова — модель, разделяющая слова на определенные типы, такие как сокращения, аббревиатуры, обычные слова, имена собственные, числа и т. д.
С этого момента проверяется насколько хорошо подходит к данной модели полученное слово.
.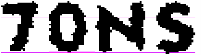
Рис. 4. Пример модели слова
Таблица 1
Пример списка моделей слов
|
Вариант распознания слова |
Модель |
|
TONS |
Заглавные буквы |
|
tons |
Прописные буквы |
|
Tons |
Первая заглавная буква в слове |
|
Tens |
Первая заглавная буква в слове |
|
Tans |
Первая заглавная буква в слове |
|
70NS |
Сокращение |
|
70ns |
Число с подстрочным знаком |
Для определения языка классификатор объединяет символы в массив, исключая повторяющиеся, затем сравнивает с существующими наборами графем присущими определенному алфавиту [4].
Литература:
- Квасников В. П. Улучшение визуального качества цифрового изображения путем поэлементного преобразования: учеб. пособие / В. П. Квасников, А. В. Дзюбаненко; Авиационно-космическая техника и технология, Москва, 2009 г., -204 c.
- Арлазаров В. Л. Распознавание строк печатных текстов: учеб. пособие / В. Л. Арлазаров, П. А. Куратов, О. А. Славин; Эдиториал, Москва, УРСС, 2000 г. -51 c.
- Выбор признаков для распознавания печатных кириллических символов: учеб. пособие / И. А. Багрова [и др.]; под ред. А. А. Грицай: Изд-во: Вестник Тверского Государственного Университета, СПБ, 2010 г. -73 c.
- Выделение графических примитивов и текстовых блоков на изображениях документов с помощью морфологических операций: учеб. пособие / А. В. Куроптев [и др.]; под ред. Д. П. Николаев: Изд-тво: МФТИ, Москва, 2008 г. -31.
