





- В настоящий момент значительное внимание
исследователей уделяется разработке и анализу моделей надежности
программного обеспечения. Тысячи моделей предлагаются в
профессиональных журналах и на научных конференциях, каждая из
которых имеет свои допущения, ограничения и сферу применения. С
практической точки зрения многие модели невозможно формально
подтвердить, часть из них обладает нерациональной величиной
стоимости сбора данных для моделирования, некоторые не работают при
применении на реальных проектах. Наиболее заслуживающие внимания
результаты получены с применением методов статистического
моделирования, в частности, с использованием распределения Вейбулла
и экспоненциального распределения.
- Распределение Вейбулла используется достаточно широко в анализе надежности технических систем, начиная от моделирования жизненного цикла шарикоподшипников и заканчивая симуляцией разливов рек и сбоев в электронно-лучевых трубках [1]. Одна из таких моделей - модель Рейли, особенностью которой является то, что хвост ее функции плотности распределения асимптотически приближается к нулю, не достигая его. Функции распределения и плотности распределения Вейбулла выглядят следующим образом:
![]()
![]()
-
где m
– параметр формы кривой распределения; c
– параметр масштаба; t –
время.
- Применительно к программному обеспечению функция распределения Вейбулла может задавать зависимость плотности сбоев от времени, а функция плотности распределения Вейбулла задаёт накопление входящего потока сбоев, что было неоднократно подтверждено на практике [2]. На рис. 1 показаны графики различных вариаций функции плотности распределения Вейбулла для альтернативных выборок параметров.
- Модель Рейли – это особенный случай распределения Вейбулла для параметров m=2. Его функции распределения и плотности выглядят соответствующим образом:
- Применительно к программному обеспечению функция распределения Вейбулла может задавать зависимость плотности сбоев от времени, а функция плотности распределения Вейбулла задаёт накопление входящего потока сбоев, что было неоднократно подтверждено на практике [2]. На рис. 1 показаны графики различных вариаций функции плотности распределения Вейбулла для альтернативных выборок параметров.
![]()
![]() .
.
-
Функция плотности распределения для случая Рейли
увеличивается до своего локального максимума, после чего
асимптотически уменьшается до нуля. Параметр c
в модели Рейли рассматривается как функция tm,
момента времени, в которой кривая достигает своей вершины.

Рисунок 1. График функции плотности для распределения Вейбулла
-
- Для нахождения этого момента определим точку локального максимума, решив дифференциальное уравнение по функции плотности относительно t, получаем следующее значение tm:
![]() .
.
- Подставив данное сочетание в первоначальное выражение и введя масштабирующий коэффициент, который необходимо оценить вместе с tm, получим следующие функции, описывающие модель Рейли:
![]()
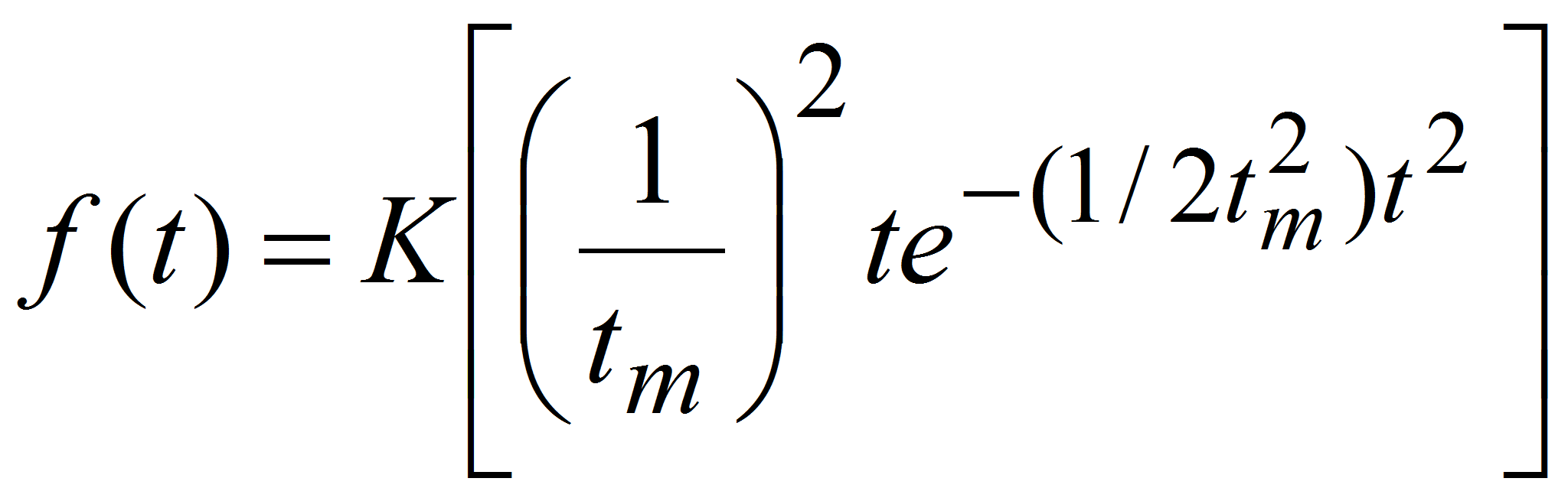 .
.
-
Эмпирически было неоднократно доказано, что жизненный
цикл программных проектов описывается кривой плотности распределения
Рейли [2, 3]. При этом, если ранние применения данной модели на
процессе разработки программного обеспечения в основном были
сосредоточены на оценке необходимых кадровых ресурсов на различных
этапах жизненного цикла, то более поздние работы отражают, что
обнаружение сбоев и их исправление также подчиняется распределению
Рейли [4].
- Дж. Гаффни Мл. получил модель, базирующуюся на шести фазах процесса разработки программного обеспечения, используемых в компании «IBM»: высокоуровневое проектирование, низкоуровневое проектирование, кодирование, модульное тестирование, интегральное тестирование и системное тестирование - и отметил, что кривая сбоев в процессе разработки по данным шести этапам асимптотически приближается к кривой распределения Рейли [5]. При этом следующая за этапом системного тестирования стадия ввода в эксплуатацию, а именно прогнозирование латентных ошибок в программном продукте, попадающих к конечным пользователям, была конечной целью исследования. Результатом экспериментов стало эмпирическое подтверждение возможности оценки текущей доли выявленных сбоев в программном продукте.
- Гипотеза о том, что при применении модели Рейли к полученным данным с высокой долей достоверности может быть спрогнозирована плотность латентных ошибок, получила развитие в работах Путнама [6, 7], где была проведена проверка работоспособности модели на завершенных проектах, для которых история обнаружения ошибок была известна (в том числе разработок, связанных с космическими шаттлами и радарной локацией). При этом было получено доказательство, что реальное отклонение плотности ошибок не превышает 5…10 % от прогнозируемых моделью Рейли. Следует отметить, что проверка модели Путнамом на нескольких программных продуктах была неудачной [7]. Однако достоверность истории ошибок по данным проектам также вызывает сомнения. Все исследования в этой области предполагали масштаб времени разработки в несколько месяцев.
- На рис. 2 показана статистика обнаружения ошибок для продукта IBM AS/400 в разрезе 6-ступенчатой парадигмы процесса развития проекта. Основной задачей является установление плотности обнаруживаемых ошибок после передачи продукта конечному пользователю на основе имеющейся статистики по процессу разработки.
- Дж. Гаффни Мл. получил модель, базирующуюся на шести фазах процесса разработки программного обеспечения, используемых в компании «IBM»: высокоуровневое проектирование, низкоуровневое проектирование, кодирование, модульное тестирование, интегральное тестирование и системное тестирование - и отметил, что кривая сбоев в процессе разработки по данным шести этапам асимптотически приближается к кривой распределения Рейли [5]. При этом следующая за этапом системного тестирования стадия ввода в эксплуатацию, а именно прогнозирование латентных ошибок в программном продукте, попадающих к конечным пользователям, была конечной целью исследования. Результатом экспериментов стало эмпирическое подтверждение возможности оценки текущей доли выявленных сбоев в программном продукте.
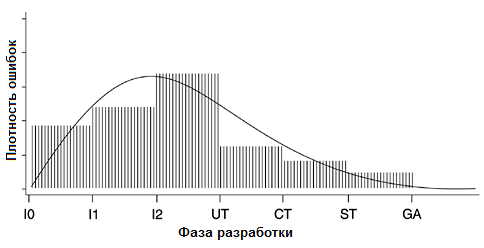
Рисунок 2. Модель Рейли и 6-ступенчатая парадигма процесса развития программных продуктов на примере статистики разработки IBM AS/400
-
Другая примечательная группа моделей анализа надежности
программного обеспечения – это модели роста надежности. В
отличие от модели Рейли, в которой описываются все этапы процесса
разработки, они обычно основаны на данных, полученных на различных
стадиях тестирования. Следовательно, наилучшую производительность
данные модели показывают на завершающих стадиях разработки, особенно
в случае, когда производится так называемое «ориентированное
на пользователя тестирование». Особенность такого процесса
заключается в том, что динамика сбоев и обнаружения ошибок при таком
тестировании моделирует период, когда программный продукт
используется конечными пользователями.
- Среди моделей данной группы наилучшие практические результаты показала экспоненциальная модель – частный случай распределения Вейбулла для значения параметра m=1. С высокой достоверностью она описывает процессы, показатели которых снижаются монотонно и асимптотически. Статистически подтверждено, что данные по сбоям многих разновидностей оборудования и процессов описываются экспоненциальной моделью: сбои банковских систем и систем финансового учёта, калькуляторов, компонентов радиолокационных комплексов и даже жизненного цикла функционирования ламп накаливания [8]. Поэтому в области исследования надежности технических систем экспоненциальное распределение играет такую же важную роль, как и нормальное распределение в других областях статистики. Функции экспоненциального распределения и плотность описываются следующим образом:
![]()
![]() .
.
-
Применительно к надежности программного обеспечения
вводится параметр
 ,
который определяет уровень обнаружения ошибок или мгновенный уровень
сбоев, или, в статистических терминах, интенсивность отказов. При
стандартном виде распределения полная площадь под кривой плотности
равна единице. В реальных приложениях они масштабируются
произведением на общее количество ошибок или полную их совокупность
K.
Основная задача, стоящая перед исследователем в процессе построения
экспоненциальной модели по полученному набору данных, – это
оценка параметров K
и λ.
,
который определяет уровень обнаружения ошибок или мгновенный уровень
сбоев, или, в статистических терминах, интенсивность отказов. При
стандартном виде распределения полная площадь под кривой плотности
равна единице. В реальных приложениях они масштабируются
произведением на общее количество ошибок или полную их совокупность
K.
Основная задача, стоящая перед исследователем в процессе построения
экспоненциальной модели по полученному набору данных, – это
оценка параметров K
и λ.
- В области исследования надежности программного обеспечения на базе экспоненциального распределения созданы и исследуются модели роста надежности. Успешным подтверждением достоверности подхода являются исследования П.Н. Мисры, который использовал экспоненциальную модель для оценки растущего потока сбоев в программном обеспечении системы приземления космических шаттлов для NASA [9]. Более того, было подтверждено, что рассмотренная ранее в работах Гэля и Окамото [10] модель негомогенного процесса Пуассона в разрезе оценки надежности ПО является, фактически, случаем экспоненциальной модели.
- На рис. 3 показаны результаты сравнения статистических данных, собранных на поздних этапах разработки (после начала системного тестирования) программного обеспечения для серверов IBM AS/400 и смоделированного экспоненциальным распределением прогноза показателей [8]. Динамика накопления обнаруженных сбоев на данном этапе задаёт плотность латентных сбоев после передачи системы в эксплуатацию.
- В области исследования надежности программного обеспечения на базе экспоненциального распределения созданы и исследуются модели роста надежности. Успешным подтверждением достоверности подхода являются исследования П.Н. Мисры, который использовал экспоненциальную модель для оценки растущего потока сбоев в программном обеспечении системы приземления космических шаттлов для NASA [9]. Более того, было подтверждено, что рассмотренная ранее в работах Гэля и Окамото [10] модель негомогенного процесса Пуассона в разрезе оценки надежности ПО является, фактически, случаем экспоненциальной модели.
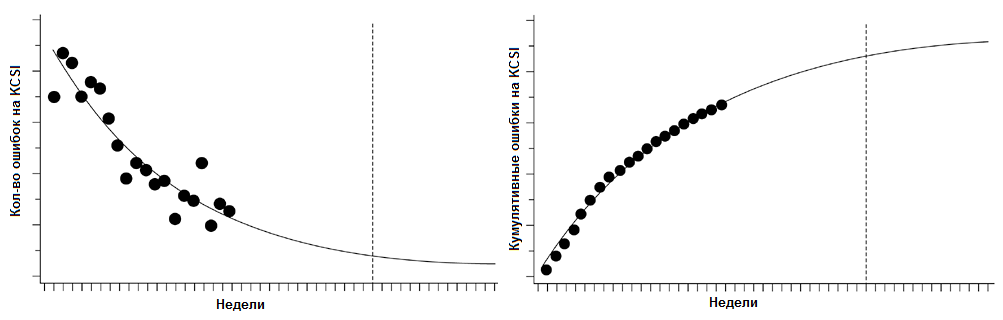
Рисунок 3. Количество еженедельных ошибок на тысячу измененных строк кода (Kilo Code Source Instructions – KCSI), плотность и функция
для экспоненциального распределения
- При применении экспоненциальной модели следует
иметь в виду, что она очень чувствительна к точности входных данных.
В качестве временной оси используются либо такты работы центрального
процессора (для маленьких проектов, оценки надежности отдельных
процедур и модулей, а также исследовательских задач), либо
календарные величины – недели, месяцы (для коммерческих
продуктов). Однако существует допущение, что при использовании
масштаба календарных величин процесс тестирования должен быть
однородным, иначе модель не показывает достоверных результатов [11].
Однородность процесса следует оценивать в разрезе таких величин, как
количество человеко-часов на тестирование каждого модуля,
проверочных прогонов, количество проверяемых вариантов входных
данных и т.д. В случае, когда процесс тестирования недостаточно
однороден, должна применяться нормализация полученных результатов
сообразно перепадам данных показателей. Исследования показали, что
удовлетворительное прогнозирование роста сбоев при применении
экспоненциальной модели происходит уже при 50…60 % выполнения
сценария системного тестирования [12].
- Основная задача, которая стоит перед исследователем при практическом применении описанных моделей, – это оценка параметров распределения. В случае применения модели Рейли это параметры tm и K, для экспоненциальной модели — K и λ. Статистическая теория предлагает на выбор несколько методов решения данной задачи, в частности, группа методик точечной оценки параметров распределения (метод максимального правдоподобия, метод моментов, метод квантилей), либо методы интервального оценивания. Интервальные оценки являются более полными и надежными по сравнению с точечными, они применяются как для больших, так и для малых выборок и заключаются в определении интервала (а не единичного значения), в котором с заданной степенью достоверности будет заключено значение оцениваемого параметра [13]. Интервальная оценка характеризуется двумя числами – концами интервала, внутри которого предположительно находится истинное значение параметра. Иначе говоря, вместо отдельной точки для оцениваемого параметра можно установить интервал значений, одна из точек которого является своего рода «лучшей» оценкой.
- После оценивания данных параметров полученный прогнозирующий вектор значений латентных сбоев может быть использован при построении комплексной оценки надежности программного проекта. При этом выбор используемой модели должен быть обоснован наличием и достоверностью данных по статистике сбоев на различных этапах разработки. В случае наличия исчерпывающего объема информации по всему периоду разработки проекта целесообразно использовать модель Рейли, а при наличии детальных данных о результатах системного тестирования применяются механизмы экспоненциального оценивания.
- Использование полученного параметризированного распределения на практике показывает наилучшую эффективность совместно с другими вероятностными оценками, например с различными взаимно коррелированными метриками продукта [14]. Математический механизм такого согласования специфичен для выбранного представления комплексной метрики. Например, при построении Байесовской сети доверия с применением плотностей распределения в качестве узловых точек конечной модели полученные функции согласуются с помощью механизма сопряженного априорного распределения [15].
Литература:
- 1. Tobias P. A., Trindade D. C. Applied Reliability. New York: Van Notrand Reinhold, 1986.
- Основная задача, которая стоит перед исследователем при практическом применении описанных моделей, – это оценка параметров распределения. В случае применения модели Рейли это параметры tm и K, для экспоненциальной модели — K и λ. Статистическая теория предлагает на выбор несколько методов решения данной задачи, в частности, группа методик точечной оценки параметров распределения (метод максимального правдоподобия, метод моментов, метод квантилей), либо методы интервального оценивания. Интервальные оценки являются более полными и надежными по сравнению с точечными, они применяются как для больших, так и для малых выборок и заключаются в определении интервала (а не единичного значения), в котором с заданной степенью достоверности будет заключено значение оцениваемого параметра [13]. Интервальная оценка характеризуется двумя числами – концами интервала, внутри которого предположительно находится истинное значение параметра. Иначе говоря, вместо отдельной точки для оцениваемого параметра можно установить интервал значений, одна из точек которого является своего рода «лучшей» оценкой.
2. Norden P. V. Useful Tools for Project Management // Operations Research in Research and Development. New York: John Wiley & Sons, 1963.
3. Putnam L. H. A General Empirical Solution to the Macro Software Sizing and Estimating Problem //IEEE Transactions on Software Engineering. Vol. SE-4. 1978.
4. Trachtenberg M. Discovering How to Ensure Software Reliability //RCA Engineer. Jan./Feb. 1982.
5. Gaffney Jr. J. E. On Predicting Software Related Performance of Large-Scale Systems // CMG XV. San Francisco. December, 1984.
6. Putnam L. H. A General Empirical Solution to the Macro Software Sizing and Estimating Problem //IEEE Transactions on Software Engineering. Vol. SE-4. 1978.
7. Putnam L. H., Myers W. Measures for Excellence: Reliable Software on Time, Within Budget, Englewood Cliffs. N.J.: Yourdon Press, 1992.
8. Kan, Stephen H. Metrics and models in software quality engineering. 2nd ed. Addison-Wesley, 2002.
9. Misra P. N. Software Reliability Analysis //IBM Systems Journal. Vol. 22. 1983.
10. Goel A. L., Okumoto K. A Time-Dependent Error-Detection Rate Model for Software Reliability and Other Performance Measures //IEEE Transactions on Reliability. Vol. R-28. 1979.
11. Ohba M. Software Reliability Analysis Models //IBM Journal of Research and Development. Vol. 28. 1984.
12. Ehrlich W. K., Lee S.K., Molisani R.H. Applying Reliability Measurement: A Case Study //IEEE Software. March, 1990.
13. Обработка экспериментальных данных на ЭВМ. Электронное пособие [Электронный ресурс] // СПб ГУТ: кафедра ОПДС [сайт]. URL: http://opds.sut.ru/electronic_manuals/oed/index.htm (дата обращения: 09.11.2010).
14. Карпов В.С., Ивутин А.Н., Суслин А.А. Подход к реализации методики оценки надежности ПО на основе комплексных метрик // Изв. ТулГУ. Технические науки. Вып. 4. Ч. 1. 2009. С. 116-125.
15. DeGroot M. H. Optimal Statistical Decisions // WCL. 2004
