





- После проведения этапов предварительного анализа исследуемой системы, составления детального плана сбора исходной статистической информации (планирования экспериментов) и непосредственного сбора исходных статистических данных наступает этап их передачи в систему обработки данных для последующего анализа [1]. Данные для этого этапа представляются в виде таблицы, столбцы которых делятся на две совокупности:
Факторы (признаки, аргументы, предсказывающие переменные) - независимую переменную величину, влияющую на параметр оптимизации. Каждый фактор имеет область определения - совокупность всех значений, которые может принимать фактор [2].
Отклики (зависимые переменные, параметры оптимизации) – реакция (отклик) на воздействие факторов, которые определяют поведением системы.
- Строки таблицы экспериментальных данных показывает соответствие
определенным значениям аргументам-факторам значения зависимых
переменных и называются наблюдениями.
- Для дальнейшего анализа полученных данных в системе обработки экспериментальных данных, необходимо обеспечить их хранение. Нетривиальность хранения табличных данных заключается в том, что они принадлежат к классу слабоструктурированных данных - фактическое количество столбцов, а также их тип (целое, дробное, строка, и др.) заранее не известны, т.е. метаданные определяющие структуру таблицы могут быть произвольными. Например, в базах данных таблицы имеют фиксированную структуру, т.к. определяются на этапе проектирования, тогда как в дальнейшем она не меняется.
- В рамках статьи предложена классификация вариантов хранения, изображенная на рисунке 1. Классификация базируется на признаке «место хранения», т.е. на месте в вычислительной системе, где непосредственно хранится таблица. Место хранения определяет некоторое подмножество способов хранения, т.е. каким образом табличные данные переносятся на формат хранилища, определенный местом хранения.
- Перед рассмотрением способов хранения определим три операции, которые требуется обеспечить в рамках хранилища:
- Для дальнейшего анализа полученных данных в системе обработки экспериментальных данных, необходимо обеспечить их хранение. Нетривиальность хранения табличных данных заключается в том, что они принадлежат к классу слабоструктурированных данных - фактическое количество столбцов, а также их тип (целое, дробное, строка, и др.) заранее не известны, т.е. метаданные определяющие структуру таблицы могут быть произвольными. Например, в базах данных таблицы имеют фиксированную структуру, т.к. определяются на этапе проектирования, тогда как в дальнейшем она не меняется.
Импорт таблицы в хранилище;
Получение таблицы из хранилища;
Удаление таблицы из хранилища.
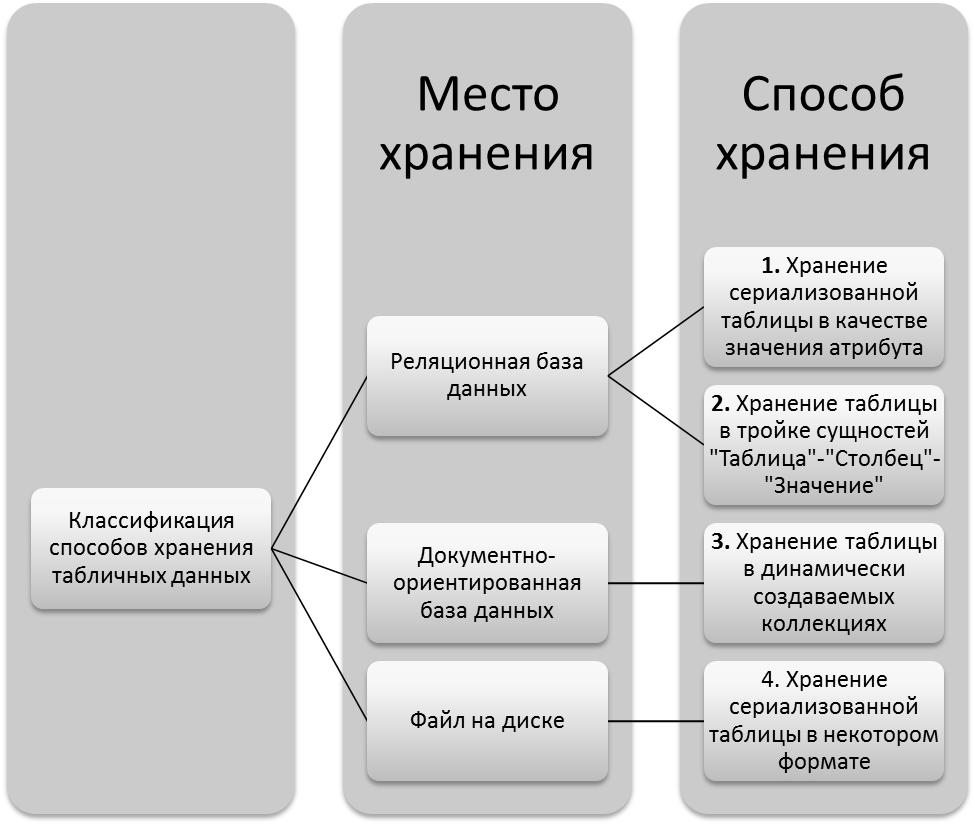
Рисунок 1 - Классификация способов хранения табличных данных по месту хранения
Хранение сериализованной таблицы в качестве значения атрибута- Этот способ хранения предполагает наличия некоторой сущности в
реляционной СУБД, один из атрибутов, которой содержит хранимые
табличные данные в сериализованном виде. На рисунке 2 иллюстрируется
этот способ хранения.
- К достоинствам этого способа хранения можно отнести
высокую скорость поиска даже при большом количестве хранимых таблиц за счет применения индексов на уровне СУБД;
Для получения таблицы необходим лишь один запрос;
Гибкость в отношении выбора формата сериализации.
- Очевидных недостатков у этого способа автору выделить не удалось.
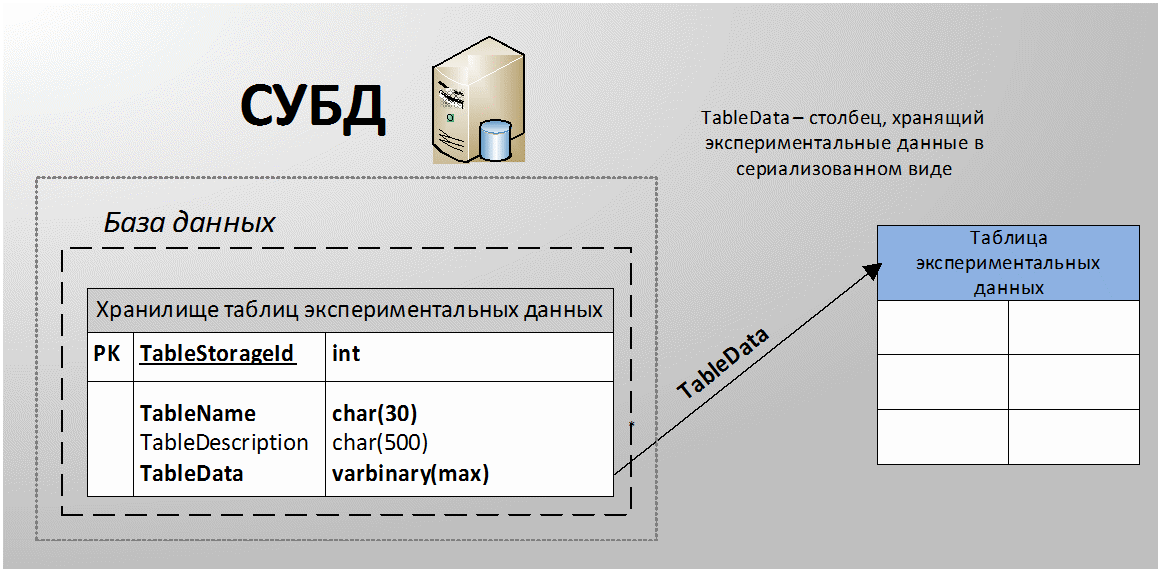 Рисунок
2 - Иллюстрация к способу хранения на основе СУБД и сериализованной
формы
Рисунок
2 - Иллюстрация к способу хранения на основе СУБД и сериализованной
формы
- Т.к. использование реляционных баз данных предполагает фиксированную структуру сущностей, то естественной является попытка осуществить декомпозицию табличных данных в понятиях реляционной модели. Одним из возможных вариантов такой декомпозиции является хранение данных в трех сущностях:
Сущность «Таблицы» (Tables) содержит метаданные таблицы и отношение «один ко многим» с сущностью «Столбец». Метаданные таблицы – это ее имя (Name), описание (Description) и флаг (TempTableFlag) того, что таблица является временной (например, хранится не как результат импорта исходных для эксперимента данных, а как результат расчета после парциальной обработки, сортировки столбца исходной таблицы и др.).
Сущность «Столбцы» (Columns) содержит метаданные столбца (имя (Name) и описание (Description)) и внешний ключ для связи с сущностью «Значение».
Сущность «Значения» (ColumnValues) содержит в строковом виде значение ячейки хранимой таблицы, а также номер наблюдения (RowNumber).
- На рисунке 3 проиллюстрирован этот способ хранения таблиц, где
можно заметить дополнительную сущность «Типы» (Types).
Эта сущность отвечает за хранение типов данных, в которых могут быть
представлены значения столбцов.
- У данного способа хранения можно выделить лишь одно достоинство – обеспечение хранения полностью вписывается в реляционную модель. Главный недостаток – очень низкая производительность всех основных операций (импорта, получения, удаления), что подтвердилось в результате тестирования.
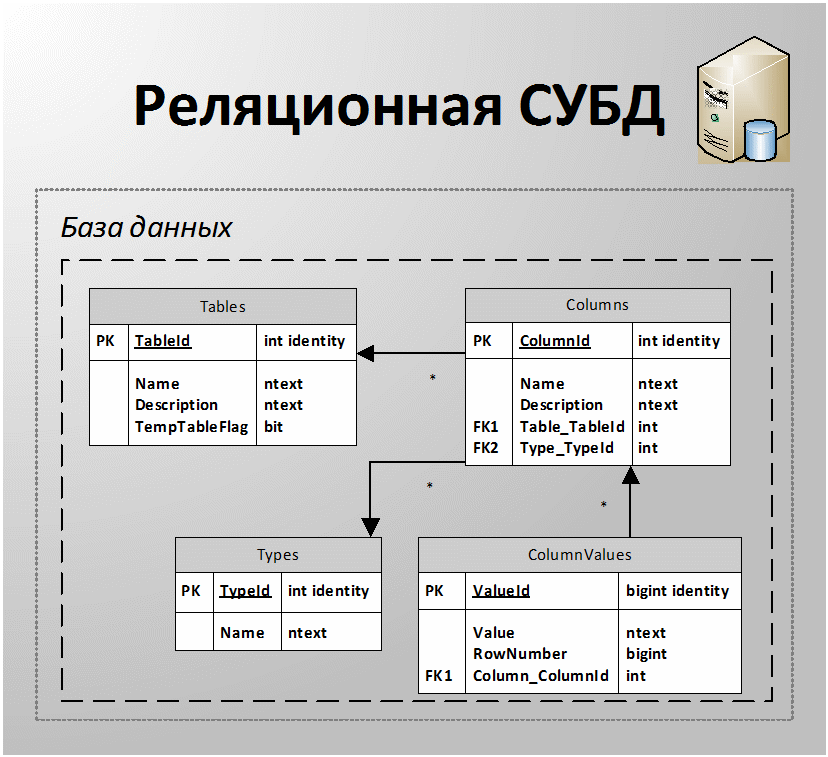
Рисунок 3 - Хранение табличных данных в тройке реляционных сущностей
Хранение таблицы в динамически создаваемых коллекциях- Документно-ориентированные базы данных получают все большее
распространение в области разработки ПО в последнее время. Основной
причиной для этого является их гибкость в отношении
слабоструктурированных данных. Еще одной важной их особенностью
является возможность создавать коллекции динамически, причем это
является допустимой практикой, в отличие от реляционных баз данных,
где сущности создаются на этапе проектирования (или доработки), но
не в процессе непосредственной работы (создания, чтения,
редактирования, удаления записей сущностей).
- Иллюстрация этого способа хранения приведена на рисунке 4.
 Рисунок
4 - Хранение табличных данных в динамически создаваемых коллекциях
Рисунок
4 - Хранение табличных данных в динамически создаваемых коллекциях
- На рисунке показана дополнительная коллекция «TableRegistry»,
которая отвечает за общий учет импортированных в хранилище таблиц и
содержит только метаданные, а также коллекция «sales.dbf»
каждый документ (термину документ в реляционных баз данных примерно
соответствует понятие запись) которой хранит одну запись таблицы.
- Достоинствами этого способа хранения является высокая скорость всех основных операций (импорта, получения и удаления) из-за лежащего в основе хранения с помощью хеш-таблиц (документно-ориентированные БД получили свое развитие из так называемых «key-value» хранилищ). К недостатком же такого способа можно отнести низкую горизонтальную масштабируемость из-за отсутствия механизма репликации. Однако стоит отметить, что стали появляться СУБД с реализацией механизма MapReduce, позволяющим восполнить этот недостаток.
- Этот способ хранения является наиболее простым из рассмотренных. При его использовании программное представление таблицы (так называемый граф объектов) переводится в последовательную (от англ. serial - последовательный) форму, т.е. сериализуется в выбранном формате (двоичный, XML, SOAP, JSON, BSON и др.). Достоинствами этого способа являются:
Потенциально очень большая скорость основных операций (импорт, получение и удаление);
Гибкость в выборе форматтера (объект, реализующий преобразование графа объекта в последовательную форму);
Гибкость в добавлении дополнительных этапов. Например, добавить сжатие сериализованной формы перед записью в файл.
- Единственным недостатком этого способа является необходимость большего по сравнению с другими способами дискового пространства, т.к. сериализованная форма имеет больший размер, чем представление таблиц в специальном формате (например, dBase).
- Можно заметить, что в предложенной классификации отсутствуют такие комбинации рассмотренных способов, как хранение данных в документно-ориентированных БД, но в сериализованной форме или при использовании файла как места хранения, использовать уже известный специальный формат (dBase, .csv, .dif). Однако, целью статьи является рассмотрение и тестирование именно наиболее полярных (ортогональных) способов, для чего ее можно считать пригодной.
- В тестировании участвуют все рассмотренные способы, кроме
хранения сериализованной таблицы в качестве атрибута в БД.
- В качестве платформы для реализации использован Microsoft .NET Framework 4, программирование осуществлялось на языке C#. Для реализации хранилищ были применены следующие программы и программные компоненты:
Для хранилища на основе тройки сущностей использован Microsoft SQL Server 2008 R2, а также ORM Entity Framework 4.1.
Для хранилища на основе динамически создаваемых коллекций была использована документно-ориентированная база данных MongoDB 1.8.1 и драйвер mongodb-csharp.
Для сериализации использован BinaryFormatter в составе .NET Framework.
- На рисунке 5 изображена диаграмма классов программного представления таблицы:
Класс «StorageTable» обеспечивает интерфейс доступа к таблице в целом, ее метаданные, доступ к коллекции столбцов. Реализует паттерн «Фабричный метод» для создания объекта таблицы на основе объекта «StorageTableMetadata» (объект метаданных таблицы).
Класс «StorageColumn» предоставляет интерфейс доступа к столбцу таблицы, метаданным столбца и коллекции значений столбца.
Класс «StorageColumnValue» отражает значение хранимое в столбце, номер записи, тип и свойства (C# class property) для доступа к значению.
Класс «StorageTableMetadata» и вложенный в него класс «StorageTableColumnMetadata» отражают метаданные таблицы и столбцов. Он используется для создания реестра импортированных в хранилище таблиц.

Рисунок 5 - Диаграмма классов программного представления таблицы
- На рисунке 6 показана диаграмма классов провайдеров созданных хранилищ. В соответствии с принципами объектно-ориентированного программирования был выделен абстрактный класс «StorageTableProviderFactory» определяющий общий интерфейс доступа к хранилищу. Класс реализует паттерн «Абстрактная фабрика» для поддержки сценария совместного использования разных типов хранилищ. Например, когда один тип хранилища лучше подходит для данных малого объема, а другой - для большого. Общими для всех классов являются следующие методы:
ImportStorageTable – импортирует объект таблицы в хранилище.
GetStorageTable – обеспечивает получение импортированной в хранилище таблицы как ранее рассмотренного объекта «StorageTable».
DeleteStorageTable – удаляет таблицу из хранилища.
 Рисунок
6 - Диаграмма классов хранилищ
Рисунок
6 - Диаграмма классов хранилищ
- Остальные классы реализуют рассмотренные способы организации хранилищ:
Класс «FileStorageTableProvider» реализует хранилище на основе файлов, содержащих сериализованную форму;
Класс «SqlStorageTableProvider» обеспечивает функционал хранилища на основе реляционной СУБД и тройки сущностей Таблица-Столбец-Значение;
Класс «MongoDbStorageTableProvider» реализует функционал хранилища на основе документно-ориентированных БД и динамически создаваемых коллекций.
- Ряд классов, реализующий такой функционал как конвертацию таблиц из разных форматов (dBase, Microsoft Excel и др.) в объект «StorageTable», преобразование «StorageTable» в «System.Data.DataTable» для обеспечения привязки данных к элементам управления и другие классы, использованные в реальном проекте, не приведены, т.к. не важны в рассматриваемом контексте.
- Для тестирования использован компьютер с процессором Intel
Core 2 Quad
Q9400 2.4 GHz @
3.2 GHz, оперативной памятью 4 Gb
DDR2 800
MHz и операционной системой Microsoft
Windows 7 Professional.
- Исходными данными для теста являлись три таблицы, условно разделенные на три категории:
Малая – 72 записи * 2 столбца = 144 значения;
Средняя – 8052 записи * 6 столбцов = 48312 значения;
Большая – 95114 записи * 6 столбцов = 570684.
- Таким образом, по результатам теста можно сделать вывод об
эффективности хранилища в зависимости от размера хранимых таблиц.
- В рамках тестирования замерялось время выполнения каждой операции (импорта, получения и удаления таблицы) в миллисекундах, перед тестированием все хранилища были пусты. Число итераций теста для малой, средней и большой таблицы составило 500, 50 и 100 соответственно. Для средней таблицы сделано всего 50 итераций по причине очень долгого выполнения теста для хранилища на основе реляционной СУБД и тройки сущностей. В тесте с большой таблицей этот способ построения хранилища не использован.
- На рисунке 7 приведено среднее время выполнения каждой операции для реализованных хранилищ, полученное в результате теста. Можно заметить существенное отставание хранилища на основе реляционной СУБД и тройки сущностей, что особенно заметно на операции импорта таблицы. Это можно объяснить большим числом операций SQL-вставки равное число столбцов * число записей, что для таблицы из 5 столбцов и 8000 записей соответствует 40000 операций вставки. В отношении операции получения и удаления видно отставание на 1-2 порядка по сравнению с другими способами хранения.
- Хранилище на основе документно-ориентированной БД и динамически создаваемых коллекций обеспечивает наименьшее время в операциях получения и удаления, но уступает хранилищу с использованием файла и сериализованной формы в отношении операции импорта.
- В рамках тестирования замерялось время выполнения каждой операции (импорта, получения и удаления таблицы) в миллисекундах, перед тестированием все хранилища были пусты. Число итераций теста для малой, средней и большой таблицы составило 500, 50 и 100 соответственно. Для средней таблицы сделано всего 50 итераций по причине очень долгого выполнения теста для хранилища на основе реляционной СУБД и тройки сущностей. В тесте с большой таблицей этот способ построения хранилища не использован.

Рисунок 7 - Среднее время операция хранилищ для таблицы малого размера
- На рисунке 8 показаны результаты теста для таблицы среднего
размера. Число итераций теста было равно 50, что связано с очень
низкой производительностью хранилища с использованием реляционной
СУБД. Ситуация изменилась по сравнению с таблицей малого размера –
среднее время получения существенно превосходит время импорта.
Неприемлемо высокие значения для этих операций тяжело объяснить, и
скорее всего они связаны с большим влиянием ORM.
- В отношении других способов хранения можно заметить, что хранилище на основе документно-ориентированных коллекций уступает хранилищу на основе сериализованного файла в операции импорта, однако показало меньшее время для операций удаления и импорта. Эта картина отличается от той, что мы наблюдали для таблицы малого размера.

Рисунок 8 - Среднее время операция хранилищ для таблицы среднего размера
- На рисунке 9 показаны результаты тестирования большой таблицы.
Ввиду неприемлемо низкой производительности хранилища на основе
реляционной СУБД и тройки сущностей в дальнейшем оно не
тестировалось. Тест был проведен на 100 итерациях.
- Картина результатов этого теста полностью совпадает с той, что мы наблюдали для таблицы среднего размера. Однако, стоит отметить, что среднее время операций получения и импорта для хранилища на основе сериализованного файла растет существенно быстрее, чем для хранилища на основе динамически создаваемых коллекций, что можно видеть на рисунке 10а и 10б.
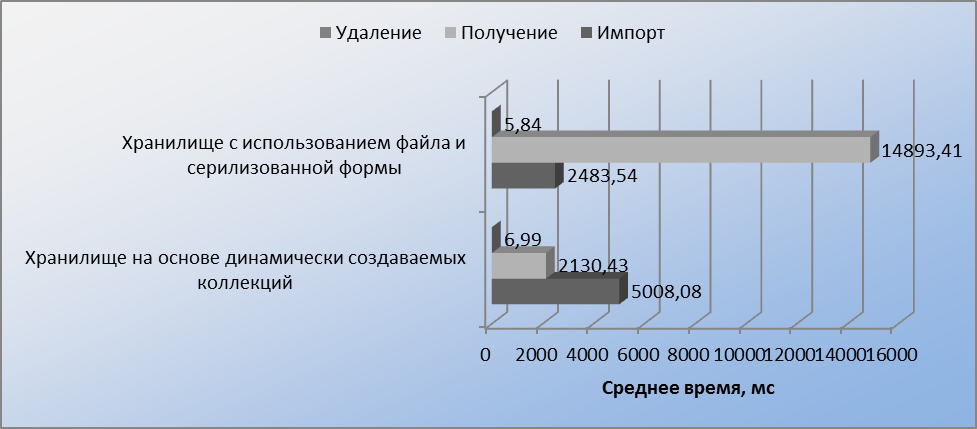
Рисунок 9 - Среднее время операция хранилищ для таблицы большого размера
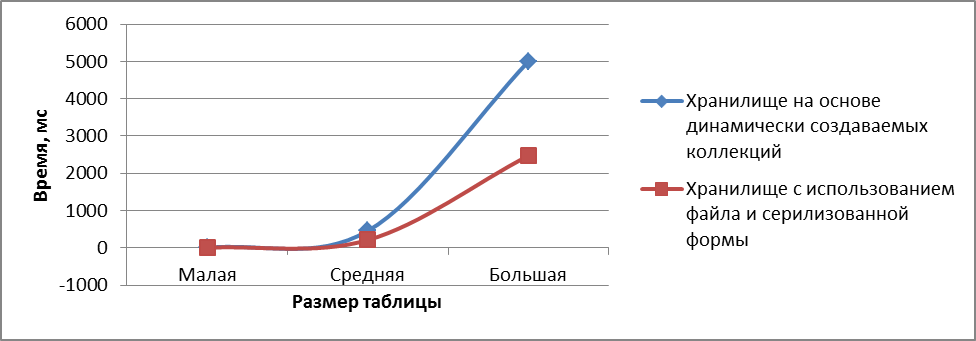
а)
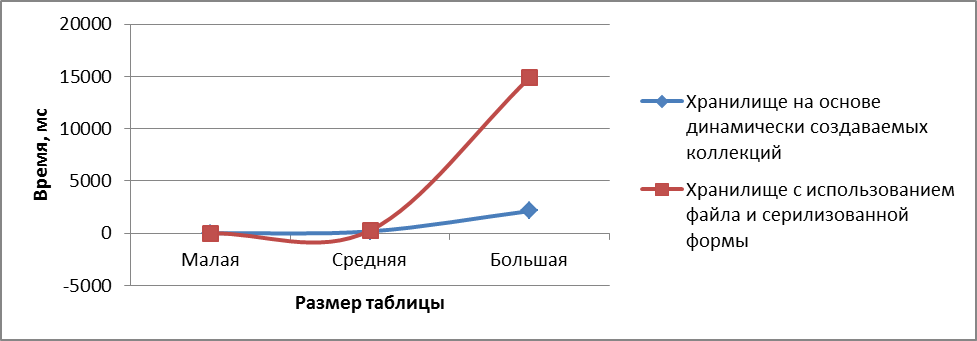
б)

в)
Рисунок 10 - Зависимость среднего времени операции от размера таблицы а) - импорт б) получение в) удаление
Заключение- В статье была предложена классификация способов хранения табличных данных. С опорой на эту классификацию были протестированы реализации наиболее ортогональных способов:
Хранилище с использование документно-ориентированных БД и динамически создаваемых коллекций;
Хранилище на основе реляционной СУБД и тройки сущностей;
Хранилище на основе файла и сериализованной формы.
- Вариант (2) оказался совершенно не пригоден для реального
использования и представляет скорее академический интерес, как
принципиальная возможность хранить слабоструктурированные данные в
реляционной СУБД. Два других варианта обеспечивают приемлемую
производительность на малых и средних исходных данных, но показывают
разную динамику роста от размера исходных данных. Хранилище (1)
обеспечивает меньшее время роста на операциях импорта и получения,
но большее на операции удаления. Из этого можно сделать вывод, что
способ (1) является наиболее пригодных для применения в системе
обработки экспериментальных данных.
- Литература:
Айвазян С.А. и др. Прикладная статистика: Основы моделирования и первичная обработка данных. Справочное изд. / С. А. Айвазян, И. С. Енюков, Л. Д. Мешалкин. – М.: Финансы и статистика, 1983. – 471 с.
Зедгинидзе И.Г. Планирование эксперимента для исследования многокомпонентных систем. М., «Наука», 1976, стр. 390.
MongoDB – Википедия [Электронный ресурс] : свободная общедоступная многоязычная универсальная энциклопедия. – Режим доступа: http://www.mongodb.org/. - Загл. с экрана.
MSDN | Microsoft Development, Subscriptions, Resources, and More – Википедия [Электронный ресурс] : свободная общедоступная многоязычная универсальная энциклопедия. – Режим доступа: http://msdn.microsoft.com/. - Загл. с экрана.
