





В настоящее время компьютерные технологии проникли практически во все сферы жизнедеятельности человека. Многие процессы и задачи, которые до недавнего времени возлагались на человека, сейчас полностью автоматизированы и практически не требуют вмешательства человека. Целью данной работы является исследование современных методов распознавания номерных знаков транспортных средств.
Ключевые слова: номерной знак, алгоритм распознавания, нормализация изображения, распознавание текста.
Предобработка. Изображение или видео с транспортным средством номерной знак которого необходимо распознать будет получено с камеры. Если было получено видео, то это видео должно быть разбито на кадры и самый удачный из них должен быть использован при распознавании номерного знака [1–2]. Это изображение или кадр затем необходимо преобразовать из RGB формата в оттенки серого. Медианный фильтр, примененный к полученному изображению в оттенках серого, поможет убрать различного типа шумы присутствующие на изображении. Так же медианный фильтр концентрируется на высокочастотных областях изображения (см. рис. 1), что дает лучшие результаты при обнаружении границ номера в более поздней части алгоритма.

Рис. 1. Изображение после применения медианного фильтра
Выделение области с номерным знаком. Далее нашей целью является локализация положения номерного знака на исходном изображении и выделение изображения, которое содержит только номерной знак автомобиля.
К изображению, полученному после применения медианного фильтра, необходимо применить усредненный фильтр с маской размером 20 на 20 пикселей [3–4], после чего будет получено размытое изображение. Сейчас размытое изображение необходимо вычесть из исходного изображения в оттенках серого, чтобы получить изображение разности интенсивности. Это связано с тем, что, когда изображение размыто с помощью усредненного фильтра высокочастотные пиксели в изображении стремятся выровнять свое значение с окружающими пикселями. Таким образом окружающие пиксели получают более высокое значение [5]. На рисунке 2 представлено изображение, полученное после вычитания.

Рис. 2. Изображение после вычитания.
Для создания бинаризованного изображения необходимо применить довольно низкий порог. В данном случае применим порог со значением 0.03. Таким образом все пиксели со значением больше порогового устанавливаются в единицу, остальные устанавливаются в ноль [6–7].
К бинаризованному изображению необходимо применить оператор Собеля, для того чтобы получить точные границы бинарных объектов. Далее необходимо отметить все непрерывные области на полученном изображении (см. рис 3).

Рис. 3. Изображение после оператора Собеля и выделения непрерывных областей
Далее необходимо найти отмеченную прямоугольную область, которая пропорционально соответствует размерам номерного знака [8]. Эту прямоугольную область необходимо извлечь из изображения, поскольку в ней содержится текст для распознавания. Далее с помощью операции умножения (логическое И) изображения в оттенках серого и найденной прямоугольной области убираются все компоненты изображения, которые не нужны при распознавании номера (см. рис. 4).

Рис. 4. Выделенная область с номерным знаком
Сегментация символов. Полученное изображение необходимо бинаризовать с помощью довольно низкого порога (около 0.01). Теперь все заполненные области можно считать символами, которые нужно распознать. Каждую такую область нужно пронумеровать отдельным индексом, а также с четырех сторон выделить границу символа. Для корректного выделения символов применяется «жадный» алгоритм ограничительной рамки для поиска прямоугольника максимального размера. Далее изображение приводится к какому-то фиксированному размеру, для более удобной работы в дальнейшем. Предположим, что фиксированный размер равен 175x730.
Все области размером менее 1000 пикселей и более 8000 пикселей удаляются. Такие области не являются символами, а могут быть различными элементами (винты крепления номерного знака, повреждения, следы ржавчины) в результате получаем изображение, представленное на рисунке 5. Далее каждый символ обрезаем по границам символа и получаем N различных изображений, где N — количество символов на номерном знаке (см. рис. 6).

Рис. 5. Изображение с границами символов
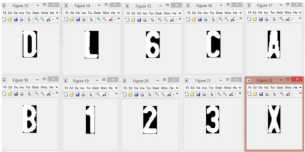
Рис. 6. Индивидуально выделенные символы
Распознавание символов. Каждый полученный символ сравнивается с шаблонным изображением в разных позициях. Базу с символами необходимо составлять с учетом разных размеров символов и шрифтов. Нейронная сеть может быть применена при вводе нового шрифта. Таким образом алгоритм становится умнее.
Поскольку номерной знак автомобиля содержит только цифры и буквы латинского алфавита, обучать нейронную сеть можно лишь для распознавания 36 символов (26 символов латинского алфавита и 10 цифр). Каждый входной символ можно представить в виде матрицы, содержащей нули и единицы, где 0 — черный пиксель, 1 — белый. На рисунке 6 представлен формализованный вид символа «А».
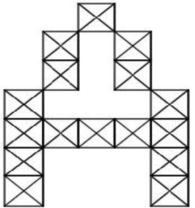
Рис. 7. Формализованный вид символа «А»
Для получения обучающей выборки воспользуемся библиотекой Neural Network Toolbox, которая содержит в себе обучающую выборку для распознавания латинских символов, а также цифр. В данной выборке каждый символ представлен в виде матрицы 7x5. Таким образом на вход нейронной сети подается вектор на 35 элементов (представляет собой распознаваемый символ) на выходе имеем вектор на 36 элементов, потому что у нас 36 распознаваемых символа. На рисунке 8 схематично изображена нейронная сеть. Изображенная нейронная сеть, по сути, состоит из трех слоев: входной, выходной и скрытый.
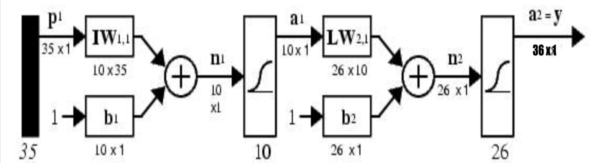
Рис. 8. Схема нейронной сети
Представленная нейронная сеть является ИНС вида FFNN (feedforward neural network). По сути, нейронная сеть такого вида представляет слоеную архитектуру, где нейроны одного слоя никак не взаимодействуют между собой, взаимодействие осуществляется лишь между слоями. В качестве функции активации выберем логарифмическую сигмоидную функцию, поскольку ее выходные значения находятся в диапазоне от 0 до 1, что очень легко перевести в булеву алгебру. Такая функция имеет вид, представленный в формуле 1 [9].
a1 = logsig(I1W1,1p1+b1)(1)
Данная функция активации представлена для скрытого слоя нейронной сети. Так же необходимо выбрать начальное количество нейронов в скрытом слое. Как видно на рисунке 8, таких нейронов будет 10, далее это значение может быть скорректировано.
Далее необходимо обучить нейронную сеть, для этого используется метод обратного распространения ошибки, то есть по нейронной сети проходим начиная с конца. При обучении для большей вероятности корректного распознавания символа необходимо включать в выборку зашумленные изображения.
Для обучения была использована база символов Extended MNIST. База включает в себя более 60 000 символов и цифр для обучения нейронной сети.
В итоге получена довольно высокая распознаваемость символа. На рисунке 9 представлен график соответствия входа и распознанного символа. Идеальный случай — когда красный прямоугольник находится на побочной диагонали (это значит, что символ, который подан на вход совпадает с выходным символом).
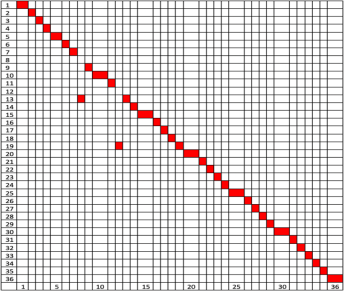
Рис. 9. Соответствие входного и распознанного символа
Сейчас необходимо выбрать правильное количество нейронов на скрытом слое нейронной сети. На рисунке 10 представлен график зависимости ошибки распознавания от количества нейронов в нейронной сети. снова возрастает. Из этого следует что оптимальное число нейронов равно 25 [10].
Высокий процент корректного распознавания как раз обусловлен разносторонней выборкой, в которую входят как «чистые» изображения, так и довольно зашумленные. В дальнейшем для более высокой точности распознавания можно увеличить входной вектор (символ представлен большей матрицей, например 10x14). Таким образом в конечном результате будет получена строка с номерным знаком автомобиля.
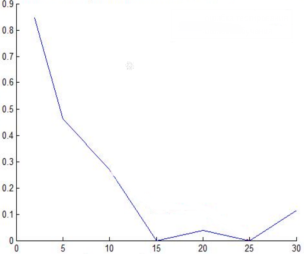
Рис. 10. Зависимость ошибки от количества нейронов на скрытом уровне
Литература:
- Мурыгин К. В. Нормализация изображения автомобильного номера и сегментация символов для последующего распознавания // Институт проблем искусственного интеллекта МОН Украины и НАН Украины, г. Донецк 2010 г. — 6с.
- Мурыгин К. В. Обнаружение автомобильных номеров на основе смешанного каскада классификаторов / К. В. Мурыгин // Искусственный интеллект. — 2010. — No 2. — С. 147–152.
- Гонсалес Р. Цифровая обработка изображений / Р. Гонсалес, Р. Вудс — М.: Техносфера, 2006. — 1072с.
- Анфилатов, B. C. Системный анализ в управлении / Анфилатов B. C., Емельянов A. A., Кукушкин A. A. М.: Финансы и статистика, 2003.
- Шередеко, Ю. Л. Способ корректного сведения задачи идентификации к задаче распознавания образов / Шередеко Ю. Л., Марусяк А. В. — УсиМ., 2002. — No5. — С.5- 12
- Волкова, В. Н. Теория систем и системный анализ / Волкова В. Н. — М.: Издательство Юрайт, 2010.
- Могилев, А. Технологии поиска и хранения информации. Технологии автоматизации управления / Могилев А., Листрова Л. СПб.: БХВ-Петербург, 2012.
- Speech Recognition HOWTO [Электронный ресурс]. — 2017. — Режим доступа: http://dsp-book.narod.ru/Speech-Recognition-HOWTO.pdf
- Qure.ai Blog [Электронный ресурс]. — Режим http://blog.qure.ai/notes/semantic-segmentation-deep-learning-review.
- Vision [Электронный ресурс]. — Режим https://lmb.informatik.uni- freiburg.de/people/ronneber/isbi2015/.
