





Цель данной статьи — сравнительный анализ методологий проектирования хранилищ данных. Формирование критериев сравнения. Описание архитектур, используемых в каждой методологии.
Ключевые слова: inmon, kimball, data vault, архитектура хранилищ данных, базы данных, витрины данных, модели данных.
Введение
Объемы данных растут во всем мире и в частности в различных компаниях. Все больше корпораций осознают, что необходимо эффективно использовать существующую информацию. Хранилище данных, благодаря своему уникальному представлению в качестве интегрированного корпоративного хранилища данных, играет в этой ситуации еще более важную роль. Сегодня для создания хранилища данных используются три известных архитектурных стиля: архитектуры Inmon, Kimball и Data Vault [1]. В этой статье делается попытка сравнить и сопоставить преимущества и недостатки каждого архитектурного подхода и выявить, какой подход следует использовать на основе определенных факторов.
Методология Inmon
Подход Inmon к созданию хранилища данных начинается с корпоративной модели данных. Эта модель идентифицирует ключевые предметные области и, что наиболее важно, ключевые объекты, с которыми работает бизнес, например, клиент, продукт, поставщик и т. д. Из этой модели для каждого основного объекта создается подробная логическая модель. Например, для объекта «клиент» будет построена логическая модель со всеми деталями, относящимися к нему. Под объектом «заказчик» может быть десять разных лиц. Все детали, включая бизнес-ключи, атрибуты, зависимости, участие и отношения, будут отражены в подробной логической модели [2]. Ключевым моментом здесь является то, что структура сущности построена в нормализованной форме. По возможности избегается избыточность данных. Это приводит к четкой идентификации бизнес-концепций и позволяет избежать аномалий обновления данных. Следующим шагом является построение физической модели. Физическая реализация хранилища данных также нормализована. Это то, что Inmon называет «хранилищем данных», и именно здесь осуществляется управление единой версией истины для предприятия. Эта нормализованная модель делает загрузку данных менее сложной, но использование этой структуры для запросов затруднительно, поскольку включает в себя множество таблиц и объединений [3]. Итак, Inmon предлагает создавать витрины данных, специфичные для отделов. Витрины данных разрабатываются специально для финансов, продаж и т. д., и витрины данных могут иметь ненормализованные данные, чтобы улучшить производительность при отчетности. Архитектура хранилища по данной методологии представлена на рисунке 1.
Для витрин используется схема организации таблиц «звезда» или «снежинка». Любые данные, поступающие в хранилище данных, интегрированы, и хранилище данных является единственным источником данных для различных витрин данных. Это гарантирует, что целостность и непротиворечивость данных сохраняются во всей организации.
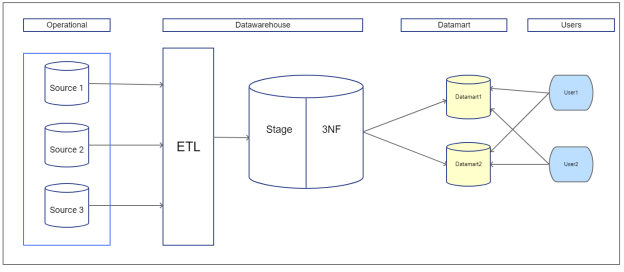
Рис. 1. Архитетура хранилища по Inmon
Ключевые преимущества подхода Inmon:
− Хранилище данных служит единственным источником истины для предприятия, поскольку оно является единственным источником витрин данных, и все данные в хранилище данных интегрированы.
− Аномалии обновления данных избегаются из-за очень низкой избыточности. Это делает процесс ETL более простым и менее подверженным ошибкам.
− Бизнес-процессы можно легко понять, так как логическая модель представляет подробные бизнес-объекты.
− Очень гибкий — поскольку меняются бизнес-требования или изменяются исходные данные, хранилище данных легко обновить, так как одна вещь находится только в одном месте.
− Может обрабатывать различные потребности отчетности по всему предприятию.
Недостатки метода Inmon:
− Модель и реализация могут со временем усложниться, так как она включает в себя больше таблиц и объединений.
− Нужны специалисты, которые являются экспертами в области моделирования данных и самого бизнеса. Этот тип ресурсов может быть трудно найти и чаще всего он дорогой.
− Первоначальная настройка и развертывание займет больше времени, и руководство должно знать об этом.
− Необходима дополнительная работа ETL, поскольку витрины данных строятся из хранилища данных.
− Для успешного управления хранилищем данных должна быть большая команда специалистов.
Методология Kimball
Подход Kimball к созданию хранилища данных начинается с определения ключевых бизнес-процессов и ключевых бизнес-вопросов, на которые необходимо ответить хранилищу данных. Ключевые источники (операционные системы) данных для хранилища данных анализируются и документируются. Программное обеспечение ETL используется для доставки данных из разных источников и загрузки в промежуточную область. Отсюда данные загружаются в размерную модель. В этом и заключается ключевое отличие: модель, предложенная Кимбаллом для хранилищ данных — размерная модель, данная модель не нормализована. Фундаментальная концепция размерного моделирования — схема звезды [4]. В схеме «звезда» обычно имеется таблица фактов, окруженная многими измерениями. Таблица фактов содержит все меры, относящиеся к предметной области, а также внешние ключи из разных измерений, которые окружают таблицу фактов. Таблицы измерений полностью денормализованы, так что пользователь может получить детализацию данных без дополнительных операция соединения. Несколько схем «звезда» строят для удовлетворения различных требований к отчетности. Для достижения интеграции в размерной модели Kimball предлагает концепцию «согласованных измерений». Ключевые измерения, такие как клиент и продукт, которые совместно используются различными фактами, будут построены один раз и будут использоваться всеми фактами. Это гарантирует, что одна вещь или концепция используется одинаково для фактов. Другим ключевым артефактом модели Kimball является «матрица корпоративных шин». Это документ, в котором различные факты перечислены вертикально, а соответствующие измерения перечислены горизонтально. Где бы измерения ни играли роль внешнего ключа в действительности, это отмечено в документе. Это служит якорным документом, показывающим, как строятся звездообразные схемы и что остается построить в хранилище данных. На рисунке 2 показана типичная архитектура хранилища данных Kimball.
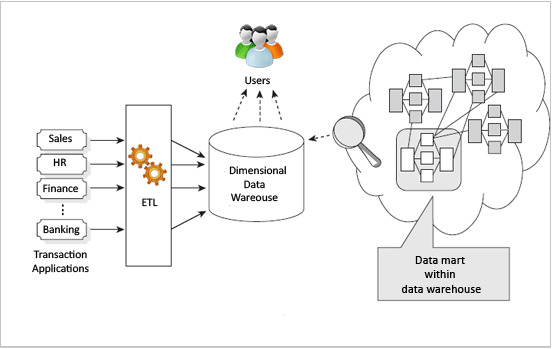
Рис. 2. Архитетура хранилища по Kimball
Преимуществ методологии Kimball:
− Быстрая настройка и сборка, и первая фаза проекта хранилища данных будет быстро развернута.
− Схема типа «звезда» легко понятна бизнес-пользователям и проста в использовании для составления отчетов. Большинство инструментов BI хорошо работают со звездообразной схемой.
− Размер среды хранилища данных невелик, она занимает меньше места в базе данных и значительно упрощает управление системой.
− Производительность модели «звезда» очень высокая. Ядро базы данных выполнит «звездное соединение», где будет создан декартово произведение, используя все значения измерений, и таблица фактов будет, наконец, запрошена для выборочных строк. Известно, что это очень эффективная операция с базой данных.
− Небольшой команды разработчиков и архитекторов достаточно для эффективной работы хранилища данных.
− Очень хорошо работает для метрик по отделам и отслеживания KPI, так как витрины данных ориентированы на отчетность по отделам или бизнес-процессам.
− Детализация, при которой инструмент BI перебирает несколько схем типа «звезда» для создания отчета, может быть успешно выполнен с использованием соответствующих измерений.
Недостатки метода Кимбалла:
− Суть «единого источника истины» утеряна, так как данные не полностью интегрированы до удовлетворения потребностей в отчетности.
− Избыточные данные могут вызвать аномалии обновления данных с течением времени.
− Добавление столбцов в таблицу фактов может вызвать проблемы с производительностью, т. к. таблицы фактов разработаны очень глубоко. Если будут добавлены новые столбцы, размер таблицы фактов станет намного больше и не будет работать должным образом. Это затрудняет изменение размерной модели при изменении бизнес-требований.
− Не может удовлетворить все потребности корпоративной отчетности, потому что модель ориентирована на бизнес-процессы, а не на предприятие в целом.
− Интеграция устаревших данных в хранилище данных может быть сложным процессом.
Методология Data Vault
Гибридный подход, объединивший достоинства схемы «звезда» и 3NF (третья нормальная форма), предназначен для обеспечения долгосрочного исторического хранения данных, поступающих из нескольких операционных систем. Это также метод просмотра исторических данных, в котором рассматриваются такие вопросы, как аудит, отслеживание данных, скорость загрузки и устойчивость к изменениям, а также подчеркивание необходимости отслеживать, откуда поступили все данные в базе данных. Это означает, что каждая строка в хранилище данных должна сопровождаться атрибутами источника записи и даты загрузки, что позволяет аудитору отслеживать значения обратно в источник [5]. Метод моделирования обеспечивает устойчивость к изменениям в бизнес-среде, откуда поступают хранимые данные, путем явного отделения структурной информации от описательных атрибутов. Хранилище данных разработано для максимально возможной параллельной загрузки так что очень большие реализации могут масштабироваться без необходимости значительного перепроектирования. Пример архитектуры Data Vault не приведен, т. к. схожа с Inmon за исключением структуры таблиц в хранилище в Inmon это 3NF, а в Data Vault — комбинация организации таблиц 3NF и схема звезды.
Преимущества методологии Data Vault:
− Гибкость и расширяемость. Data Vault как расширение структуры хранилища, так и добавление и сопоставление данных из новых источников требует минимальных доработок.
− Agile-подход из коробки. Проектирование хранилище по методологии Data Vault достаточно простая задача. Новые данные просто «подключаются» к существующей модели, не изменяя сформировавшуюся структуру базы данных. При это задачи на расширение источников данных будут реализовываться атомарно, что упрощает планирование и оценку управление проектом.
Недостатки методологии Data Vault:
− Множество соединений. За счет большого количества операций join теряется производительность запросов, в сравнении с традиционными хранилищами данных, где таблицы более денормализованы.
− Сложность. В описанной выше методологии есть много важных деталей, понять которые не получится быстро. Нехватка информации в интернете из-за того, что данная методология новая, по сравнению с остальными. Обязательное требование к наличию витрин данных — большой недостаток, так как сам по себе Data Vault плохо подходит для прямых запросов [6].
− Избыточность. Довольно спорный недостаток, но я часто вижу вопросы об избыточности, поэтому прокомментирую этот момент со своей точки зрения.
Сравнительный анализ методологий
Для сравнения подходов проектирования хранилищ данных, сформулированы следующие критерии:
1) Сложность ETL — количество ETL процессов для полной трансформации данных от стадии загрузки из источника до формирования витрин данных.
Оценки: количество ETL процессов 1 — низкая/ 2 — средняя/ 3 и более — высокая.
2) Масштабируемость и параллельность загрузки ETL — Возможность добавления новых источников данных и параллельной загрузки. Оценки: Есть/Нет
3) Аудит, прослеживаемость, согласованность данных — сложность отслеживания исторических данных. Оценки: низкая/средняя/высокая
4) Сложность проектирования — трудоемкость проектирования и реализации хранилища. Оценки: низкая/средняя/высокая
5) Гибкость хранилища — необходимость реализации отдельных витрин данных. Оценки: необходимо/нет необходимости
6) Производительность запросов — скорость выполнения прямых запросов для отчетов. Оценки: высокая/средняя/низкая
Ниже приведена таблица критериями по вертикали и методами по горизонтали с соответствующими оценками:
|
Походы Критерии |
Inmon |
Data Vault |
Kimball |
Преимущество |
|
1 |
Средняя |
Средняя |
Низкая |
Kimball |
|
2 |
Есть |
Есть |
Есть |
Kimball |
|
3 |
Средняя |
Ннзкая |
Средняя |
Data Vault |
|
4 |
низкая |
Высокая |
низкая |
Inmon |
|
5 |
необходимо |
необходимо |
нет необходимости |
Kimball |
|
6 |
высокая |
высокая |
низкая |
Kimball |
В большинстве случаев методология Kimball более гибкая, чем остальные, из-за простоты структуры, отсутствия лишних звеньев в архитектуре, что облегчает проектирование и реализацию структуры базы данных, так же способствует улучшению производительности хранилища данных, но при данным подходе большая часть нагрузки накладывается на ETL.
Заключение
В данный статье представлены методологии проектирования хранилищ данных. Описаны архитектурные особенности преимущества и недостатки каждой методологии. Представлены архитектуры хранилищ для методологий Inmon, Kimball. Проведен сравнительный анализ подходов по сформированным критериям, выявлена наиболее гибкая методология в соответствии оценками.
Литература:
- Kimball, R. and M. Ross. The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling (Second Edition) 2002, 109–116.
- John Wiley and Sons. Building the Data Warehouse (Third Edition) 2002, 243–247.
- Joshi, K. and M. Curtis. «Issues in building a successful data warehouse». Information strategy: the executive's journal, Winter 1999, 28–35.
- Jukic, N., Sharma, A., Nestorov, S. and Jukic, B. 2015. Augmenting Data Warehouses with Big Data. Information Systems Management 2015, 200–209.
- Dehdouh, K. Building OLAP Cubes from Columnar NoSQL Data Warehouses. In 6th International Conference Model and Data Engineering. Springer International Publishing 2016, 166–179.
- Введение в Data Vault. — Текст: электронный // habr.com: [сайт]. — URL: https://habr.com/ru/post/348188/ (дата обращения: 11.05.2020).
