





Данная статья описывает структуру хранения используемой памяти, простые способы диагностики её утечек и временные исправления их.
Ключевые слова: JVM, JDK, JIT, stack, стек, heap, threads, потоки, Class Loader, загрузчик классов, Stack Overflow, frame, фрейм, компилятор.
В JVM есть механизм ограничения памяти. Многие разработчики, выставив необходимые параметры при запуске приложения, ожидают принудительное ограничение оперативной памяти; но приложение начинает потреблять больше, вмешивается операционная система и «убивает» приложение из-за ошибки Out Of Memory. На популярном интернет-ресурсе разработчиков StackOverflow очень много подобных вопросов [1–3].
Стандартными способами в Unix-подобных операционных системах потребление ОЗУ можно посмотреть с помощью команды:
$ htop -p%MEM
C её помощью можно увидеть 2 вида памяти:
1) Virtual — общее количество используемой задачей виртуальной памяти, включает все коды, данные, совместные библиотеки, плюс страницы, которые были перенесены в раздел подкачки, и страницы, которые были размечены, но не используются. Обычно можно не смотреть на значения данной памяти, если только операционная система не является 32-битной;
2) Resource — фактический объем памяти, не помещённого в раздел подкачки, которую в текущий момент использует процесс.
Само по себе число малоинформативно. Но есть способ посмотреть подробности, что входит в данный объем памяти. В Unix-подобных операционных системах имеется некая «карта памяти», и анализ того или иного процесса можно с помощью команды:
$ pmap -x <PROCESS_ID>
Эта команда показывает участок памяти (адрес) процесса, занимаемый объем, динамические библиотеки, а также анонимные регионы. Если размер един, например, 4 гигабайта, то это, скорее всего, Java Heap. Однако, и сама JVM может рассказать об потреблении памяти внутри.
В научной статье «Исследование процессов внутри виртуальной машины Java» [4] были подробны описаны процессы внутри JVM, и ни для кого не секрет, что на данные операции тоже требуются вычислительные ресурсы. Начиная с Java 7, появился параметр запуска Native Memory Tracking, который позволяет вывести статистику по внутреннему потреблению памяти. Но нужно иметь ввиду, что данный анализ также добавляет потребление ресурсов (в официальной документации указано, что затраты по производительности могут достигать 5–10 процентов и вдобавок ко всей выделяемой памяти добавляется по 2 машинных слова на каждую локацию). Есть системная команда, позволяющая отобразить только ту память, про которую знает сама JVM. Посмотреть можно с помощью команды:
$ jcmd <PROCESS_ID> MV.native_memory
По результату будет отображено сколько всего JVM зарезервировало памяти, сколько физической памяти из зарезервированной, и все это разбито на подсистемы виртуальной машины. Под каждую подсистему дополнительно указано как он был выделен: либо напрямую операционной системой (вызовом mmap) или через стандартный системный аллокатор malloc.
Рассмотрим более подробно каждую подсистему.
JavaHeap
Под данную область есть 2 версии в листинге памяти:
1) То, что непосредственно относится к Heap;
2) То, что относится к Garbage Collector’у.
Размер Heap будет ровно стольким, сколько было указано в параметре
—Xmx. Сборщик мусора также обрабатывает Heap, и для этого ему требуется память на его структуры; за это отвечает область Mark Bitmap (область, где хранятся достижимые объекты), и Mark Stacks (для маркировки графа). Самым ресурсозатратным процессом сборщика мусора является Remembered Sets (актуально для всех алгоритмов сборки мусора по поколениям, либо по подсистеме). Все эти структуры хранят ссылки, ряд информации о том, из каких подсистем есть в данную подсистему для поддержки инкрементальной сборки, либо сборки по поколениям. Объем данных структур может быть велик.
Стоит обратить внимание, что параметр -Xms задает начальный размер Heap, а не минимальный. Это не гарантирует, что Heap не может стать меньше данного значения; по умолчанию за это отвечает алгоритм динамического подбора размера в Hot Spot JVM и Heap может уменьшиться.
ClassLoading
JVM также тратит память и на загрузку классов. Под данную операцию собирается и хранится информация, после чего может предоставляться разработчику по требованию (а начиная с JDK 10 эта секция стала более понятна: теперь отображается статистика по метаданным, классам).
Metaspace — это отдельная подсистема, не относящаяся к Heap. Метаданные, возникшие в процессе загрузки классов. До JDK 7 область называлась Permgen Space, и новый метод пришел на смену, чтобы избавиться от проблемы Out Of Memory Error.
В JDK имеется стандартный оптимизатор (Compressed Tools), применимый так же и для метаданных классов; чтобы уметь адресовать ссылки на классы на 64-битных системах все 4 байтами (экономя на этом ресурсы) классы были выделены в отдельную область под названием Compressed Class Space и размер данной области не может превышать более 3 гигабайта памяти (это ограничение сделано для поддержи работы с 32-битными ОС). По умолчанию выделено 1 гигабайт. Но есть недочеты: если вдруг приложение начинает беспорядочно генерировать классы, все равно может возникнуть ошибка «Out Of Memory Error: Compressed class space».
Проверить это можно стандартными утилитами JVM машины:
до JDK 8 включительно:
$ jmap -clstats
начиная с JDK 9:
$ jcmd
Есть возможность просмотра статистика по каждому классу конкретно:
$ jcmd
Смысл в том, что по каждому классу показана сколько его байт-кода занимает в памяти, сколько аннотаций, и так далее.
Еще один из случаев, когда важно следить за размерами Metaspace; данная секция может расти неуправляемо, благо это можно отследить с помощью параметров:
$ -XX:+printGCDetails | -Xlog:gc+heap
Как устроен Metaspace? Он резервируется операционной системой большими блоками памяти, а уже размещение в страницах физической памяти происходит блоками поменьше (их называют Chunk Memory). В каждом chunk’e могут быть данные лишь одного загрузчика классов, но при этом одному загрузчику может соответствовать несколько chunk’ов. Метаданные классов выделяются блоками внутри каждого chunk’a. Загрузчик классов может «умирать» и освобождаться целиком. Значение capacity в отчете — это и будет объем всех занятых chunk’ов на данный момент времени; свободные могут использоваться повторно.
JustinTime (JIT) компиляция
Помимо Heap и загрузки классов еще тратятся ресурсы на JIT-компиляцию. Главным потребителем памяти является область Code Cache — сюда складывается весь скомпилированный код. Даже если отключить компилятор, то все равно будет генерироваться виртуальный машинный код именно в данную область. Например, интерпретатор тоже генерируется в runtime и кладется в тот же самый Code Cache.
Для работы алгоритмов JDK компиляторов тоже нужна память; она выделяется на каждый поток, куда попадает граф промежуточного представления, структуры, необходимые для алгоритмов, оптимизаторы и т. д. Надо учесть, что в современных JDK есть как минимум 2 компилятора, а это значит, что он компилирует в 2 раза больше объема. При этом есть такая эвристика, жестко зашитая в коде JDK: если у нас есть 2 компилятора, то размер Code Cache Size умножается на 5. Верно и обратное: если вдруг по какой-то причине захотим отключить один из компиляторов, то размер Code Cache Size уменьшиться и станет по умолчанию 48 мегабайт, чего может не хватить. Если размер Code Cache будет слишком маленький, то могут возникать просадки в производительности.
Threads
Известно, что на открытие потоков также происходит потребление ресурсов; в официальной документации сказано, что если не хватает памяти, то, возможно, слишком большой стек потока (Stack Thread) или нужно уменьшить их количество. Как правило, анализ Native Memory Tracking показывает, что около 500 потоков могут занимать примерно 0,5 гигабайта памяти.
Такой объем занимаемой памяти под потоки не страшен. Дефолтный 1 мегабайт на поток не выделяется в настоящий момент времени, а лишь по мере использования. Таким образом, стеки потоков будут занимать ровно столько, сколько нужно было максимально использованному стеку. К сожалению, неизвестно никакой стандартной утилиты, которая бы позволила сказать, сколько реально потребляет физической памяти стек потока.
JavaStack
Возьмем для примера небольшой код (листинг 1), который считает количество вызовов, прежде чем появится ошибка StackOverflowError (при стандартном размере стекa).
Листинг 1 — Код для проверки глубины вхождения Stack’a
1: package ru.tolgas.memory;
2:
3: public class DemoRecursion {
4: static int depth;
5:
6: public static void main(String [] args) {
7: try {
8: test();
9: } catch (StackOverflowError e) {
10: System.out.println(depth);
11: }
12: }
13:
14: static void test() {
15: depth++;
16: test();
17: }
18: }
Результат можно увидеть на рисунке 1.
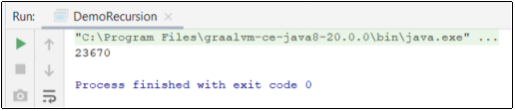
Рис. 1. Результат выполнения кода из Листинга 1 (без параметров)
На 64-битной системе с размером стека 1 Мб результат варьируется от 22 до 35 тыс. вызовов. Почему такая большая разница? Дело в JIT: методы компилируются в фоновом потоке компилятора параллельно с исполнением java-кода. После того, как метод test несколько раз вызывался, запускается компиляция этого метода, а в это время продолжается исполнение в интерпретаторе. Как только компилятор закончит свою работу, следующий вызов перейдет в скомпилированный код.
Как было сказано в разделе «JustinTime (JIT) компиляция», по умолчанию в одной JVM есть 2 компилятора — «легкий» С1 и «тяжелый» С2. Допускается ситуация, когда у нас на стеке окажутся фреймы трех типов: интерпретированный, скомпилированный C1 и скомпилированный C2. Размер фрейма может сильно отличаться. У интерпретатора самые громоздкие фреймы, потому что все хранится на стеке (все аргументы, локальные переменные, указатель текущего байт-кода и т. д.). В скомпилированном коде многое из этого не нужно и, чем оптимальнее будет компилятор, тем меньше надо хранить на стеке. C2, к примеру, вообще не будет заводить место на стеке под локальные переменные — все расставит по регистрам, а еще и перестроит на один уровень.
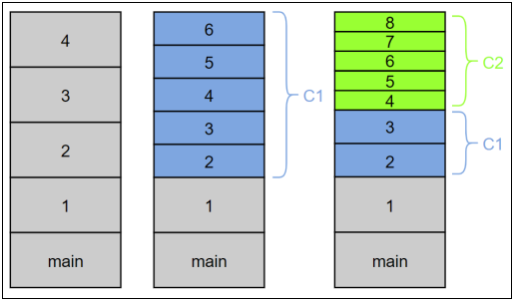
Рис. 2. Заполнения фреймов
Запустим тот же самый код исполнить в чисто интерпретируемом режиме с параметром -Xint(рис. 3).
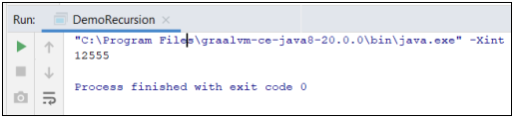
Рис. 3. Результат выполнения программы в интерпретируемом режиме
Результат — практически всегда 12500 (± несколько фреймов). Теперь то же самое, но после компилятора С1 (рис. 4).

Рис. 4. Результат выполнения программы с компилятором C1
В случае с компилятором С1 результат тоже довольно стабильный — порядка 25 тысяч.
Посмотрим на результат если все сразу компилировать в С2 (рис. 5).

Рис. 5. Результат выполнения программы с компилятором С2
Все это будет работать дольше, но результат — 94 тыс. фреймов. Если поделить стандартный размер стекa (1 Мб) на 94 тыс., получится, что на 1 фрейм уходит примерно 11 байт. Но размер фрейма на самом деле не 11 байт, а в 2 раза больше, но в 1 фрейме заложено сразу 2 уровня вложенности.
Это можно проверить про скомпилированному коду.
Значения стеков по умолчанию:
– Для х32 (х86): 320 Кб;
– Для х64: 1 Мб.
Интересный факт: если посмотреть размер ThreadStackSize c помощью параметра -XX:PrintFlagsFinal на Linux, то действительно выдаст размер в 1 Мб, а если посмотреть на Windows — значение по умолчанию будет 0. Откуда берется тогда 1 Мб? Оказывается, что начальный размер стека задается в *.exe файле (прописывается значение по умолчанию в атрибутах exe-формата для приложения).
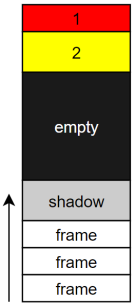
Рис. 6. Внутренняя структура стека
Минимальный размер стека на 64-битной системе — примерно 228 Кб (может меняться от версии к версии JDK). Как устроен стек и откуда складывается этот минимальный размер?
На стеке, помимо фреймов Java-методов, есть еще некоторое зарезервированное пространство. Эта как минимум всегда 1 красная зона (размером с 1 страницу — 4 Кб) в самой верхушке стека и несколько страниц желтой зоны. Красная и желтая зоны нужны для проверки Stack Overflow. В начале обе зоны защищены от записи. Каждый Java-метод, через попытку записи по адресу текущего стек-поинтера, проверяет достижение красной или желтой зоны (при попытке записи операционная система генерирует исключение, которое виртуальная машина перехватывает и обрабатывает). При достижении желтой зоны она разблокируется, чтобы хватило места запустить обработчик Stack Overflow, и управление передается на специальный метод, который создает экземпляр StackOverflowError и передает его дальше. При попадании в красную зону возникает Unrecoverable Error и виртуальная машина фатально завершается.
Есть еще так называемая shadow-зона. У нее довольно странный размер: на Windows — 6 страниц, на Linux, Solaris и прочих ОС — 20 страниц. Это пространство резервируется для нативных методов внутри JDK и нужд самой виртуальной машины.
Литература:
1 Estimating maximum safe JVM heap size in 64-bit Java // Stack Overflow [Электронный ресурс]. — URL: https://stackoverflow.com/questions/10219301/
2 Java consumes memory more than Xmx argument // Stack Overflow [Электронный ресурс]. — URL: https://stackoverflow.com/questions/48798024/
3 How do I keep memory used by JVM under control? // Stack Overflow [Электронный ресурс]. — URL: https://stackoverflow.com/questions/20920205/
4 Наливайко, А. С. Исследование процессов внутри виртуальной машины Java / А. С. Наливайко. — Текст: непосредственный // Молодой ученый. — 2020. — № 20 (310). — URL: https://moluch.ru/archive/310/69986/ (дата обращения: 20.05.2020).
5 Паньгин Андрей. Память Java процесса по полочкам. В кн.: Joker: Международная Java-конференция, Экспофорум, Санкт-Петербург, 19–20 октября 2018.
6 Все, что вы хотели знать о стек-трейсах и хип-дампах. Часть 2 — Блог компании JUG Ru Group / Habr [Электронный ресурс]. — Режим доступа: https://habr.com/ru/company/jugru/blog/325064/.
