





В данной статье на основе набора данных об донорах приводится пример применения классификации объектов методом «наивного Байеса». При помощи данного метода по признакам объекта, определяется к какой из двух групп он относится (к донорам или не донорам).
Ключевые слова: наивный байес, классификация, python.
Предположим, что есть определенный тестовый объект. У этого объекта есть некоторые признаки, обозначенные как X. Поставлена задача, в которой нужно выяснить, какова вероятность принадлежности этого объекта к определенному классу, который в обучающей выборке обозначен буквой C. Для решения можно воспользоваться методом «наивного Байса», в основе которого лежит теорема Байеса, позволяющая вычислить эту вероятность по простой формуле (1):
![]() (1)
(1)
− P(c/x) — апостериорная условная вероятность класса C при условии наличия атрибутов X.
− P(x) — априорная вероятность появления свойства X.
− P(c) — априорная вероятность класса C.
− P(x/c) — правдоподобие, вероятность свойства X при классе C.
Теорема Байеса верна при наличии двух предположений относительно переменных:
− все переменные являются одинаково важными;
− все переменные являются статистически независимыми, т. е. значение одной переменной ничего не говорит о значении другой.
Также стоит отметить преимущества и недостатки метода «наивного Байса».
Преимущества данного метода заключается в быстроте проведении классификации и в небольшом объеме входных данных для обучения. Отлично работает с категорийными признаками, лучше, чем с непрерывными.
Не обошлось и без недостатков. В случае, когда в обучающих данных не присутствовали категорийные признаки, то если они будут содержаться в тестовом наборе, то модель будет присваивать этим значениям нулевую вероятность и осуществление прогноза будет невозможно. Такого рода проблема решаема путем сглаживания. Один из простых вариантов сглаживание по Лапласу.
Также стоит помнить, что данный метод классификации хороший, но не всегда спрогнозированные вероятности будут достаточно точными.
Рассмотрим пример применения метода «наивного Байса». Имеется набор данных о донорах, которые представлены следующим образом рис.1:
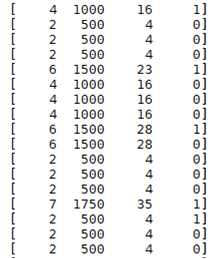
Рис. 1. Набор исходных данных
Каждый из столбцов показывает следующую информацию:
− 1 столбик — месяцы с момента последнего пожертвования;
− 2 столбик — общее количество пожертвования;
− 3 столбик — месяцы с первого пожертвования;
− 4 столбик — был ли донором в прошлом месяце (0 — не донор, 1 — донор).
Последний столбец является классами для обучения, убрав его из основной выборки, данные, содержащие только признаки. По ним и производить обучение и построение модели.
Построим модель, используя пакет sklearn.naive_bayes. Получаем выборку классов и сравниваем ее с исходной (см. рис.2):

Рис. 2. Полученная выборка классов
Произведем оценку качества модели прогнозирования, результат показан на рис. 3:
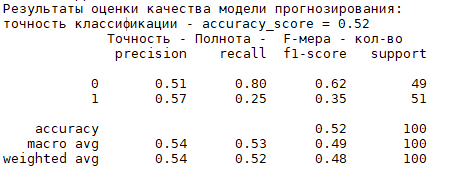
Рис. 3. Результат оценки качества модели прогнозирования
Отсюда можно заметить, что точность классификации равна 0.52, к числу доноров было отнесено 51 объект, к не донором — 49.
Для наглядного представления построим график (см. рис.4):
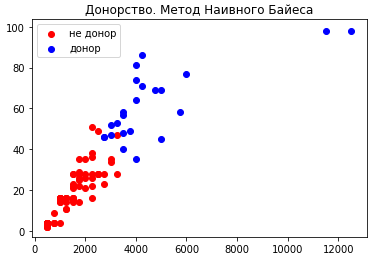
Рис. 4. Графическое представление результата классификации
Таким образом, была осуществлена классификация объектов и определена группа, к которой они относятся (донор, не донор).
Литература:
- Луис Педро Коэльо, Вилли Ричарт. Построение систем машинного обучения на языке Python. 2-е издание / пер. с англ. Слинкин А. А. — М.:ДМК Пресс, 2016. — 302 с.:ил.
