





В современной IT отрасли стандартом разработки подавляющего большинства промышленных проектов прикладного уровня стало использование модели объектно-ориентированного проектирования (ООП). Однако на практике по целому ряду причин, которые мы рассмотрим в дальнейшем, в сознании большинства программистов (в том числе студентов IT специальностей) ООП исчерпывается применением синтаксиса объектно-ориентированных языков программирования (ООЯП) с использованием концепций структурного уровня программирования (в лучшем случае). С другой стороны имеется большая группа специалистов осознано использующих методологию ООП, но не способных достаточно полно ответить на ряд фундаментальных вопросов, касающихся отношений между компонентами системы и тех существенных ограничений, которые накладываются на систему в результате установления подобных отношений.
Неадекватность применения объектно-ориентированного синтаксиса рассмотрим на примере простого выражения языка С++: A=B, оставив за рамками внимания вопрос приведения типов. В концепции структурного уровня это выражение обозначает копирование всех битов переменной В в переменную А. В концепции ООП данное выражение означает - объекту А присвоить значения объекта В. В результате чего произойдет неявное выделениям памяти объектом А согласно реализации его оператора присваивания. Данная операция может привести к сбою, в случае, отказа функции распределения памяти и соответственно генерированию исключения с последующим радикальным изменением хода выполнения программы.
Неадекватность понимания базиса ООП выразилась в развитии ООЯП. Существующие языки и лежащие в их основе модели разработки развивались неотрывно от представлений, что такое программа. Ниже представлен краткий обзор эволюции методологии программирования:
Двоичные коды (машинные коды) - программа есть упорядоченный набор состояний конечного автомата - процессора (используется исключительно комбинатор следования);
Языки ассемблера - программа есть упорядоченный набор мнемоник ЦПУ(используются комбинаторы следования и альтернатива);
Языки высокого уровня (алгоритмические языки) - программа есть упорядоченный набор операторов языка (предоставляют в дополнение предыдущим двум реализацию комбинатора цикла);
Языки структурного уровня - программа есть упорядоченный набор методов - функциональных абстракций (реализации комбинаторов те же, однако элемент комбинирования, не оператор языка, а функциональная абстракция);
ООЯП - программа есть взаимодействующая совокупность компонентов, определяющая множество реакций в ответ на возникновение соответствующих событий во внешней операционной среде, такой как, множество клиентов корпоративной сети, ОС, BIOS, EFI (Комбинаторы инкапсуляция, наследование, полиморфизм).
Исторически сложилось так, что ООЯП создавались в качестве надмножества языков структурного уровня, что можно наблюдать на примере развития языка С++ из С или языка Delphi из Pascal. Позднее (в середине 90-х годов) были предприняты попытки разработать объектно-ориентированный язык, не привязанный к наследию структурного уровня. Это достигалось путем превращения интерфейсов классов в категорический императив программирования. Последнее характерно для ООЯП JAVA, C#. Однако в связи с отсутствием строгого и общепризнанного определения ООП и его ключевых структур существующие языки все еще имеют ограниченную поддержку концепций данной методологии проектирования. Даже в языке С++, наиболее мощном средстве разработки на сегодняшний день, приходится конструировать механизмы, реализующие отношения между понятиями той или иной предметной области. Т.е. невозможно написать универсальную библиотеку, которая позволит решать задачи любой предметной области с наибольшей эффективностью. Однако, какую бы мы предметную область не взяли, методология ее анализа всегда остается одной и той же. Задача же программиста сводится к интеграции существующей библиотеки и описания предметной области, разрабатываемого самим программистом. Как показывает практика, решить такую задачу без фундаментальных знаний в области построения ООП систем и не вызвать потом на себя праведный гнев системных администраторов не представляется возможным.
Поскольку результатом вышеупомянутой интеграции является система обработки событий, ключевой особенностью работы ООП-приложений является способность асинхронно реагировать на события. Это качественно отличает объектно-ориентированные приложения от приложений написанных в структурной методологии, для которой один из ключевых комбинаторов - следование, по определению не допускает подобного поведения. Иными словами, система, реализованная с помощью структурной методологии программирования, является синхронной, т.е инертной к изменению ключевых констант непосредственно во время выполнения программы.
Для примера рассмотрим процесс анализа структуры сети по алгоритму Spanning Tree. Как известно, алгоритм состоит из трех основных шагов:
Выбор корневого моста.
Выбор корневого порта.
Выбор назначенного порта.
В результате работы алгоритма каждый мост определяет, какие сегменты, подключенные к его портам, замыкаются сами на себя (образуют петли) и переводит соответствующие порты в режим только прослушивания. Однако после изменения топологии сети (отказе канала или добавления нового моста) весь алгоритм приходится выполнять заново, чтобы перестроить граф активных каналов в соответствии с новыми исходными данными. В связи с тем, что топология каждый раз строится «с нуля», путем безусловного последовательного выполнения всех шагов алгоритма, вся сеть простаивает достаточно долго. А если отказ канала будет перемежающимся, то за счет инертности алгоритма велик риск возникновения ситуации, когда сеть вообще не выйдет в рабочий режим, а будет заниматься исключительно изучением собственной топологии.
Идея объектно-ориентированного подхода заключается в том, чтобы при изменении конфигурации топологии, максимально локализовать изменения в конфигурации сетевого оборудования, приостанавливая работу только части сети, непосредственно контактирующей с эпицентром события. Иными словами каждый коммутатор в системе должен знать не всю топологию сети, а лишь ее часть, непосредственно прилегающую к нему. Эти идеи в итоге приведут нас к современной реализации алгоритмов балансировки нагрузки, но уже на 3-м, а не на 2-м уровне OSI.
Другим недостатком структурной методологии в системе из нескольких программ является необходимость модифицировать и компилировать координирующую программу заново для ее актуализации после добавления в координируемые компоненты хотя бы одного нового события. Например, представим рассмотренный ранее процесс анализа структуры сети в виде конвейера этапов. В результате работы такого конвейера принимается решение, какие порты моста необходимо заблокировать для исключения петель в топологии сети.
GetPortList | SetFailedPorts | SetRootPort | SetDesignatedPorts | SetBlockedPorts
Проблема заключается в том, что каждая программа в конвейере полагается на присутствие необходимой для ее работы информации в потоке ввода. Это означает, что существует некоторый протокол, определяющий в каком смещении потока, находится тот или иной параметр, используемый данной программой. Представим поток вывода для каждой из утилит-этапов конвейера в случае моста с 4 портами ethernet:
|
1. GetPortList: eth0, 10mbit, FD, Up eth1, 100mbit, HD, Up eth2, 100mbit, FD, Up eth3, 10mbit, FD, Down |
2. SetFailedPorts: eth0, 10mbit, FD, Up, Active eth1, 100mbit, HD, Up, Active eth2, 100mbit, FD, Up, Failed eth3, 10mbit, FD, Down, Failed |
|
3. SetRootPort: eth0, 10mbit, FD, Up, Active, Root eth1, 100mbit, HD, Up, Active, NR eth2, 100mbit, FD, Up, Failed, NR eth3, 10mbit, FD, Down, Failed, NR |
4. SetDesignatedPorts: eth0, 10mbit, FD, Up, Active, Root, ND eth1, 100mbit, HD, Up, Active, NR, D eth2, 100mbit, FD, Up, Failed, NR, ND eth3, 10mbit, FD, Down, Failed, NR, ND |
|
|
Допустим, что теперь программа GetPortList будет возвращать информацию также и о протоколе, сконфигурированном для данного порта. При конвейерной обработке велика вероятность совпадения значений полей, разделяемых запятыми, в одной строке (то есть не гарантируется уникальность идентификатора), однако интерпретация этих значений может значительно отличаться. В результате, если программы конвейера полагались на уникальность идентификатора, то их результат работы будет ошибочен. Если же они полагались на порядок следования полей, то и в этом случае их результат работы будет ошибочен, вследствие добавления новых значений. Рассмотрение этих проблем в рамках методологии ООП привела к появлению формата XML, который сейчас используется практически повсеместно, начиная от задач оперативного обмена сообщениями между пользователями (протокол XMPP), заканчивая маршалингом информации, необходимой для удаленного вызова процедур в .NET и организацией обмена между клиентским приложением и СУБД.
За короткую историю компьютерных технологий специалистам не раз приходилось сталкиваться с проблемой построения масштабируемых систем. Как нам известно, решением данной проблемы в сфере построения сетей передачи данных стало рассмотрение любой сети с позиций модели взаимодействия открытых систем (OSI).
Проведя аналогию между ООП системой, состоящей из некоторой совокупности взаимодействующих элементов (объектов), и абстрактной сетью описываемой моделью OSI (Рис. 1), мы можем прийти к пониманию сущности и роли трех основных комбинаторов ООП: инкапсуляции, наследования и полиморфизма.
Рассматривая модель OSI в приложении к протоколу TCP/IP, мы можем наблюдать, что каждый новый уровень модели образуется совокупностью однородных взаимодействующих элементов нижестоящего уровня. Иными словами каждый вышестоящий уровень включает в себя элементы нижестоящего уровня. Таким образом определяется понятие включения в модели OSI, которое является частным случаем понятия инкапсуляция. Понятие инкапсуляции является более общим и подразумевает не только включение элементов, но также и сокрытие типов данных, используемых внутри подсистемы, при рассмотрении этой же подсистемы с более высокого уровня.
Отношения между абстрактными и специализированными сущностями называется наследование и существует в контексте выбранного уровня рассмотрения системы.
Механизм представления какой-либо специализированной сущности в виде ее абстракции называется полиморфизмом. Это отношение можно наблюдать на примере третьего уровня OSI для сети и подсети и совокупности реальных протоколов (в данном случае IP, IP6, IPX).
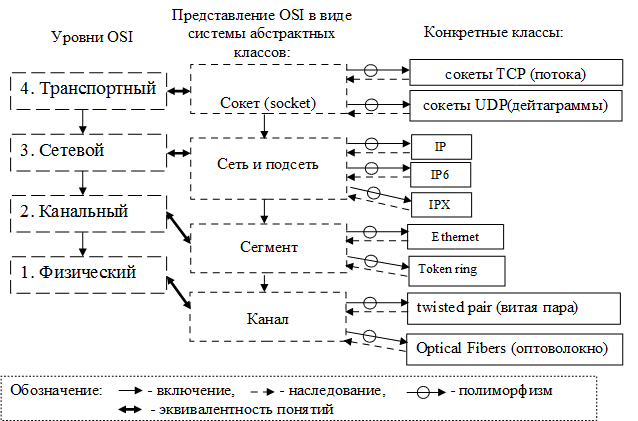
Рисунок 1 - Объектно-ориентированная модель OSI
Применение данного подхода позволяет нам строить гетерогенные сети произвольной топологии, то есть сети, работающие на различных протоколах передачи данных. Причем для данной системы не будет иметь значения, какой протокол задействован, так как, несмотря на различия, протоколы решают одну и ту же задачу в контексте одного и того же уровня модели. В этом и заключается основной эффект применения ООП - методологии.
Ответ же на вопрос, как строится подобная система, почему в стержне архитектуры лежат именно понятия "Канал", "Сегмент", "Сеть" и т.д. следует искать в понятии элементарного объекта, т.е. такого понятия предметной области, которое мы не можем расчленить на субпонятия в контексте заданной предметной области.
Итак, представленная архитектура на всех уровнях своей реализации решает концептуально одну и ту же задачу - передачу сообщения между парой или большим числом узлов системы. Если рассматривать функцию передачи сообщения как функцию, изменяющую состояние атомарного (элементарного) объекта архитектуры, например, канала связи, представленного кабелем, то логично будет рассмотреть данный объект в виде конечного автомата, имеющего соответствующие состояния (Рис.2).

Рисунок 2 – модель конечного автомата двух состояний «Канал»
Модель конечного автомата двух состояний достаточно просто преобразуется к классу ООЯП, описывающему элемент выбранного уровня рассмотрения системы. Для автомата двух состояний имеем 4 существенных события и 2 метода-триггера этих событий. На рис.3 изображена импульсная интерпретация рассматриваемой модели, где t1 соответствует поведению клиентской стороны (генератора событий), t2 – поведению моделируемого объекта (обработчика событий), t3 – поведению взаимосвязанного объекта, причем при вариации продолжительностей и амплитуд импульсов всех трех объектов, характер взаимоотношений между ними будет оставаться неизменным.
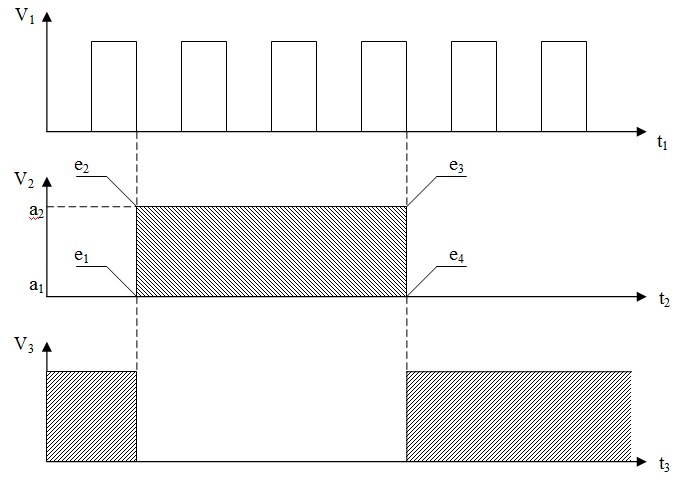
Рисунок 3 – импульсная интерпретация модели объекта «Канал»
В контексте языка C++ та же самая модель будет иметь следующий вид:
class CLink{
public:
class IAdviceSink{
public:
virtual void BeforeOpenSignalFront( CLink * pSource ) = 0;
virtual void AfterOpenSignalFront( CLink * pSource ) = 0;
virtual void BeforeCloseSignalFront( CLink * pSource ) = 0;
virtual void AfterCloseSignalFront( CLink * pSource ) = 0;
};
CLink( CLink::IAdviceSink * pAdviceSink = NULL );
virtual ~CLink();
void SetAdviceSink( CLink::IAdviceSink * pAdviceSink );
bool OpenSignalFront();
bool CloseSignalFront();
. . .
};
Наибольший интерес в классе представляет абстрактный класс (интерфейс) IAdviceSink, который позволяет вызывать методы клиентского объекта со стороны реализуемого класса в ответ на всякое изменение существенного состояния моделируемого объекта.
Здесь мы сделаем небольшое практическое отступление, касающееся реализации модели событий в C++. Что же такое событие с точки зрения языка программирования? В языке С (без плюсов) существует понятие указателя на функцию, в общем виде имеющее приблизительно следующее представление: typedef void (*) ( ) PCALLBACK;
Суть применения указателя на функцию - возможность во время
выполнения программы связать так некоторые участки программы, чтобы
функция по указанному адресу вызывалась в ответ на некоторое
событие в
нашем компьютерном мире. Так например реализовывались
когда-то векторы прерываний в DOS.
В языке С++ понятие функции обратного вызова имеет свою специфику, потому как и представление о программе в нем отличается от того же представления в C. Итак, допустим, перед нами стоит задача вызова функции-обработчика по указателю в ответ на некоторое событие, зафиксированное (обнаруженное) нашим объектом. Сложность здесь в том, что каждому методу некоторого класса в С++ неявно передается указатель (this) на экземпляр этого класса. То есть, если мы определим тип указателя на функцию PCALLBACK: typedef void (*) ( ) PCALLBACK; то этот тип не будет соответствовать сигнатуре вызова: "pSomeObject->SomeMethod();" .
В C++ существует понятие указатели на методы объекта, но большинство программистов предпочитают с ними не связываться (уж очень они неуклюжи). Поэтому поступают так:
class CSomeObject {
public:
class INotificationSink {
public:
virtual void OnSomeEvent( CSomeClass & cSender ) = 0;
};
// ...
// Далее идет определение класса.
};
Внутренний класс INotificationSink позволяет нам добиться такого поведения, чтобы другой объект получал уведомления от объектов класса CSomeObject. Для этого нам лишь надо выполнить следующее:
-
class CAnotherObject : public CSomeObject::INotificationSink {
public: virtual void OnSomeEvent( const SomeClass & cSender ) {- /* реализация обработчика здесь */
- }
// прочие составляющие класса.
};
- /* реализация обработчика здесь */
Теперь используем принцип полиморфизма. Суть полиморфизма заключается в трактовке объекта через его интерфейс, но при этом, поскольку метод является виртуальным, то при вызове интерфейсного метода вызываться будет метод фактического класса, экземпляром которого и является трактуемый объект. Таким образом, доопределяя первый класс, получим:
- class CSomeObject
{
public:
class INotificationSink {
public:
virtual void OnSomeEvent( const SomeClass & cSender ) = 0;
};
private:
INotificationSink * m_pAdvicedObj;
public:
explicit CSomeObject( INotificationSink * pAdvicedObj = NULL ) {- m_pAdvicedObj = pAdvicedObj;
- }
void SomeMethod( ) { - m_pAdvicedObj = pAdvicedObj;
- /* Допустим, тут мы обнаруживаем некоторое событие и хотим
- * уведомить наш приёмник событий. */
if ( m_pAdvicedObj != NULL ) m_pAdvicedObj->OnSomeEvent( *this ); - * уведомить наш приёмник событий. */
}
};
Конечно,
возможны и другие способы реализации событийно-ориентированного
взаимодействия в С++, к тому же у нас может быть более одного
приёмника событий (уведомляемого объекта), но нам ничто не мешает
реализовать одну из вариаций объекта мультиплексора-броадкастера,
который будет принимать сначала уведомление от исходного объекта, а
затем поочередно передавать каждому зарегистрированному в
броадкастере приемнику. Этот аспект вопроса лучше всего освящен в
фундаментальной работе GoF во главе с Эрихом Гаммой - «Шаблоны
объектно-ориентированного проектирования» (Gamma et all, 1995),
паттерн цепочка ответственности (Responsibility Chain).
Впрочем, можно трактовать m_pAdvicedObj как vector или даже deque, но, как истинный идеалист, я предпочитаю не сваливать на один класс все возможные роли. Именно из-за подобной перегрузки ролями такие библиотеки как VCL или .NET страдают от переизбытка числа методов на один класс, и часто представление программиста о том или ином классе остается лишь частичным. В этом нет большой беды, если вы лишь используете библиотеку, но если перед вами будет поставлена задача, решение которой приведет не просто к расширению, а даже к частичной реорганизации класса, то вы рискуете потеряться в деталях.
Но вернемся к стеку протоколов и нашему первому наброску класса. Именно наброску, так как представленная часть образует лишь прототип функционала, доступный для эксплуатации клиентской стороной. Однако это уже большой шаг в сторону формализации. Вопрос реализации методов в C++ достоин написания отдельной статьи. Здесь же мы рассмотрим лишь еще один аспект - как формируется объект класса вышестоящего уровня с помощью включения множества однородных объектов класса нижестоящего уровня. Мы опустим модель конечного автомата двух состояний для понятия сегмента, так как рамки статьи, увы, ограничены, но для вас не должно составить большого труда восстановить эту модель для рассматриваемого класса самостоятельно по аналогии с предыдущим уровнем. Ниже приведен листинг интерфейсной части класса.
class CSegment{
public:
class IAdviceSink{
public:
virtual void BeforeOpenMedia( CSegment * pSource ) = 0;
virtual void AfterOpenMedia( CSegment * pSource ) = 0;
virtual void BeforeCloseMedia( CSegment * pSource ) = 0;
virtual void AfterCloseMedia( CSegment * pSource ) = 0;
};
CSegment( CSegment::IAdviceSink * pAdviceSink = NULL );
virtual ~CSegment();
void SetAdviceSink( CSegment::IAdviceSink * pAdviceSink );
bool OpenMedia();
bool CloseMedia();
. . .
private:
typedef std::list< CLink > TList;
TList Items;
};
Обратите внимание на выделенную жирным курсивом часть объявления. Буквально она означает, что понятие Сегмент включает в себя множество разнородных (полиморфных) понятий Канал, однако трактуемых единообразно. Описав же в реализации класса Сегмент процесс взаимодействия между экземплярами класса Канал, мы получим на нижестоящем уровне систему каналов, изменение состояния одного из членов которой ведет к согласованной реакции соседних членов и так далее, пока общее состояние системы не станет устойчивым. Эта модель хорошо отражает физические процессы передачи энергии и/или информации в реальном мире, поэтому является чрезвычайно гибкой. В то же самое время, выделение нового уровня абстракции, достигаемого с помощью анализа часть-целое, позволяет согласованно управлять множеством аспектов работы элементов из общего центра, облегчая с ростом уровня реализацию задачи передачи сообщения (в данном случае) до тех пор, пока для ее решения не окажется достаточным вызвать единственный метод. И как только мы начинаем рассматривать программирование с клиентской точки зрения, мы покидаем мир объектно-ориентированного проектирования и вновь возвращаемся к процессам, или, иными словами, к структурному программированию. И каким бы объектным не являлось ваше приложение, все равно для него должна присутствовать та часть, которая будет изменять его состояния. Поэтому даже на C++ программа все так же традиционно начинается с функции main.
-
- Литература:
Себеста Р.В., Основные концепции языков программирования. - М.: «Вильямс», 2001. - с. 672.
Cisco Systems Руководство Cisco по междоменной многоадресатной маршрутизации = Interdomain Multicast Solutions Guide. — М.: «Вильямс», 2004. — с. 320.
