





Биометрическое распознавание человека является очень актуальной темой в современном мире. Существует множество уникальных характеристик человека, по которым можно проводить распознавание. Такими характеристиками, например, являются лицо, радужная оболочка глаза, отпечатки пальцев, походка, голос, и т. д. Одной из задач, которые необходимо решать при построении биометрической системы, является задача обновления биометрического шаблона. Такой алгоритм позволяет улучшить точность распознавания за счёт точной адаптивной подстройки под особенности пользователя. В данной работе предлагается алгоритм обновления биометрического шаблона, который осуществляет поиск центроида кластера, соответствующего пользователю в пространстве признаков с помощью свёрточной нейронной сети. Данный алгоритм был протестирован на системе распознавания по лицу.
Ключевые слова: биометрия, распознавание образов, глубокое обучение, компьютерное зрение, распознавание по лицу.
Технологии биометрического распознавания личности активно внедряются в современную жизнь. Существует множество уникальных характеристик человека, по которым можно проводить распознавание, называемые биометрическими модальностями. Такими характеристиками, например, являются лицо, радужная оболочка глаза, отпечатки пальцев, походка, голос, и т. д. Биометрическим шаблоном обычно называют совокупность векторов признаков, которые система использует для идентификации того или иного человека. Изначально, биометрический шаблон создаётся на основании данных, полученных в ходе регистрации пользователя. Однако, не всегда данных, полученных в ходе регистрации, достаточно для того, чтобы стабильно узнавать человека в разных условиях съёмки (в случае распознавания по лицу, например, могут варьироваться освещение, поза и т. п.). Одной из задач, которые необходимо решать при построении биометрической системы является задача обновления биометрического шаблона. Такой алгоритм позволяет системе лучше подстроиться под особенности пользователя при съёмке в различных условиях, а также отслеживать возможные изменения в характеристиках пользователя. В конечном итоге такой алгоритм позволяет улучшить точность распознавания.
Существует множество различных алгоритмов обновления биометрического шаблона. Самый простейший вариант — добавлять в шаблон все вектора признаков, принятые системой. Поскольку размер шаблона обычно ограничен в силу ограничений по объёму используемой памяти, добавление нового элемента шаблона происходит с помощью замены старого. Выбор заменяемого элемента шаблона может происходить по разным алгоритмам, некоторые из которых описаны в [1]: Random, Naïve, FIFO, LFU. Эти алгоритмы обладают значимым недостатком: они неустойчивы к так называемому «отравлению шаблона» [3] — процедуре с помощью которой злоумышленник может испортить шаблон таким образом, чтобы система принимала его вместо настоящего пользователя. Конечно, данная процедура воспроизводима только в случае, если у злоумышленника есть неограниченный доступ к системе, а также информация о её внутреннем устройстве, однако поскольку биометрия в наше время используется для защиты чувствительных данных (паролей, платёжной информации), даже такая угроза компрометации обычно считается недопустимой.
Существуют также методы, которые выбирают для добавления наиболее подходящие признаки по какому-либо критерию, и по этому же критерию выбирают заменяемый элемент шаблона.
Примером такого алгоритма является MDIST. Изначально MDIST был описан как алгоритм для отбора шаблона [2], то есть для выбора подмножества векторов, полученных на регистрации, которое составляет шаблон. Данный алгоритм выбирает элементы шаблона таким образом чтобы минимизировать среднее взаимное расстояние между ними (1).

Если изначальный набор векторов параметров обладает большой вариабельностью, выбранное подмножество будет находиться в окрестности центроида кластера, соответствующего Пользователю. В работе [1] было предложено использовать MDIST не как алгоритм отбора шаблона, а как алгоритм обновления шаблона. Данная модификация так же минимизирует среднее взаимное расстояние (1), заменяя элементы шаблона по одному, если это приводит к уменьшению метрики (1). Данный алгоритм основан на предположении что в длительной перспективе (при большом количестве полученных системой изображений), алгоритм сводит шаблон к плотному скоплению векторов параметров, которые находятся в окрестности центра кластера, соответствующего пользователю. Однако если параметры, полученные при начальной регистрации, недостаточно вариабельны и находятся в удалении от центроида, количество добавленных элементов необходимых для того, чтобы шаблон сошёлся в окрестности центроида кластера, может оказаться значительным, или же шаблон может сойтись в удалении от центроида, что приведёт к понижению точности распознавания.
Другим алгоритмом, выбирающим элементы шаблона, является DEND [2, 1]. Данный алгоритм проводит кластеризацию всех имеющихся векторов признаков, и внутри каждого кластера выбирает центроид с помощью алгоритма MDIST. К сожалению, данный метод так же подвержен опасности «отравления шаблона».
Существуют также методы, использующие графовые алгоритмы для отбора векторов, попадающих в шаблон. Например, в работе [4] предлагается построить по шаблону взвешенный граф, в котором вес ребра соответствует расстоянию между векторами. Для выбора элементов, которые будут добавлены в шаблон, производится разделение графа на две части с помощью алгоритма минимального разреза.
В данной работе предлагается алгоритм, который по аналогии с MDIST сводит шаблон к окрестности центроида, однако вместо оптимизации среднего взаимного расстояния используется метрика расстояния до центра кластера, которая вычисляется с помощью обученной нейронной сети. Данный алгоритм описан и протестирован в применении к распознаванию по лицу.
2. Постановка задачи.
Будем описывать алгоритм применительно к аутентификации по лицу. Допустим, у системы имеется один Пользователь. Задача системы на каждом изображении проверять, действительно ли на нём изображён Пользователь, или же другой человек.
Имеется фиксированный алгоритм извлечения признаков (FE — feature extraction), который переводит изображение в вектор признаков таким образом, что расстояние

При регистрации Пользователю ставится в соответствие шаблон


Расстоянием от вектора признаков до шаблона называется расcтояние от вектора до ближайшего элемента шаблона:

При верификации входное изображение


Решение о том, Пользователь на изображении или другой человек выносится на основании расстояния от



Точность распознавания системы обычно оценивается варьированием порога

-
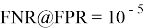
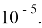
-
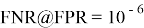
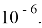
-
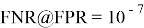
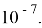
-
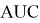







Задача алгоритма обновления шаблона состоит в том, чтобы на стадии верификации изменять шаблон (добавлением нового вектора признаков), если это необходимо:

Таким образом чтобы максимизировать значения метрик 1–4.
- Предлагаемый метод
3.1 Основная идея алгоритма
Как было сказано ранее, алгоритм MDIST сходится к плотному множеству точек, однако это множество не всегда находится в окрестности центроида.
В данной работе предлагается обучить нейронную сеть, которая будет предсказывать расстояние от вектора признаков, соответствующего изображению до центра кластера

В основе данного метода лежит предположение, что алгоритмы FE основанные на глубоком обучении переводят в центроид кластера изображения, которые лучше всего поддаются распознаванию — центрированные изображения с хорошим освещением. По краям же кластера располагаются «низкокачественные» изображения — в экстремальных позах, со сложным освещением, или ошибки сегментации.
3.2 Архитектура нейронной сети
В качестве архитектуры сети использовалась модификация классической LeNet [7]. Архитектура сети описана в табл. 1. Результат последнего полносвязного слоя после Sigmoid активации — предсказание искомого параметра

Таблица 1
Архитектура нейронной сети
|
Слой |
Размер выхода
|
|
Input |
|
|
Conv
|
|
|
ReLu |
|
|
Conv
|
|
|
ReLu |
|
|
Conv
|
|
|
ReLu |
|
|
Conv
|
|
|
ReLu |
|
|
Conv
|
|
|
ReLu |
|
|
DropOut (rate=0.7) |
|
|
FullyConnected |
|
|
ReLu |
|
|
DropOut (rate=0.7) |
|
|
FullyConnected |
|
|
Sigmoid |
|























Для обучения и тестирования алгоритма использовалась база изображений MegaFace [6], а также база изображений, собранная вручную.
3.3 Подготовка данных для обучения нейронной сети
Для подготовки данных необходим набор изображений


Для начала, по всему набору изображений


Далее, признаки группируюся по идентификаторам пользователей на соответствующих изображениях:

Для каждого пользователя затем можно посчитать центроид кластера:

Далее, с использованием центроида, можно посчитать искомое



3.4 Алгоритм обновления шаблона
Применяя вышеописанную нейросеть к каждому полученному системой изображению, предлагается для каждого элемента шаблона хранить соответствующее ему расстояние



То есть, на каждом шаге верификации, новое изображение заменяет существующее в шаблоне


где

- Результаты
В качестве алгоритма FE для оценки предлагаемого алгоритма использовался алгоритм описанный в [8]. В качестве набора данных выступал набор MegaFace [6], а также набор, собранный вручную, содержащий изображения 100 человек, с большой вариабельностью поз и освещений.
4.1 Обучение нейронной сети
Обучающий и валидационный набор данных содержали соответственно 1200000 и 150000 изображений. Разделение производилось по пользователям, то есть обучающий и валидационный набор не пересекались по пользователям, чтобы исключить возможность переобучения на конкретные лица. Обучение проводилось с помощью алгоритма градиентного спуска Adam [9] в течение 30 эпох на Nvidia Quadro RTX 6000 и заняло 6 часов.
Основные метрики на валидационном наборе по результатам обучения приведены на табл. 2
Таблица 2
Результаты обучения нейронной сети
|
Метрика |
Значение |
|
МАЕ (mean average error) |
|
|
% изображений на которых
|
81 % |
|
% изображений на которых
|
98 % |
|
% изображений на которых
|
99.95 % |




4.2 Алгоритм обновления шаблона.
В табл. 3 приведены результаты применения алгоритма обновления шаблона к распознаванию по лицу на основе алгоритма [8]. Алгоритм тестировался на MegaFace и наборе данных, собранном вручную. В тестировании алгоритма обновления шаблона не использовались данные из обучающего набора нейронной сети.
Таблица 3
Ошибка алгоритма распознавания по лицу с использованием различных алгоритмов обновления шаблона
|
Метрика |
Без обновления |
MDIST [2] |
Предлагаемый |
|
|
0.0897 |
0.0828 |
0.0744 |
|
|
0.1518 |
0.1401 |
0.1228 |
|
|
0.2253 |
0.1954 |
0.1771 |
|
|
0.9990 |
0.9991 |
0.9993 |




- Заключение
Предложен алгоритм обновления биометрического шаблона, который развивает идею алгоритма MDIST, однако для поиска центроида кластера, соответствующего пользователю в пространстве признаков, использует метрику «расстояние до центроида кластера», которая вычисляется с помощью нейронной сети. Нейронная сеть показала высокое качество на валидационном множестве, а применение данного алгоритма к системе распознавания по лицу показало значительный прирост качества распознавания.
Литература:
1. Freni B., Marcialis G. L., Roli F. Replacement algorithms for fingerprint template update //International Conference Image Analysis and Recognition. — Springer, Berlin, Heidelberg, 2008. — С. 884–893.
2. Uludag U., Ross A., Jain A. Biometric template selection and update: a case study in fingerprints //Pattern recognition. — 2004. — Т. 37. — №. 7. — С. 1533–1542.
3. Lovisotto G., Eberz S., Martinovic I. Biometric backdoors: A poisoning attack against unsupervised template updating //2020 IEEE European Symposium on Security and Privacy (EuroS&P). — IEEE, 2020. — С. 184–197.
4. Rattani A., Marcialis G. L., Roli F. Biometric template update using the graph mincut algorithm: A case study in face verification //2008 Biometrics Symposium. — IEEE, 2008. — С. 23–28.
5. Bradley A. P. The use of the area under the ROC curve in the evaluation of machine learning algorithms //Pattern recognition. — 1997. — Т. 30. — №. 7. — С. 1145–1159.
6. Kemelmacher-Shlizerman I. et al. The megaface benchmark: 1 million faces for recognition at scale //Proceedings of the IEEE conference on computer vision and pattern recognition. — 2016. — С. 4873–4882.
7. LeCun Y. et al. Handwritten digit recognition with a back-propagation network //Advances in neural information processing systems. — 1989. — Т. 2.
8. Chen S. et al. Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices //Chinese Conference on Biometric Recognition. — Springer, Cham, 2018. — С. 428–438.
9. Kingma D. P., Ba J. Adam: A method for stochastic optimization //arXiv preprint arXiv:1412.6980. — 2014.
[1] Работа выполнена при финансовой поддержке РФФИ (грант № 19–31–90171).
