





В условиях современной России программисту часто приходится работать в очень широком диапазоне задач, начиная от задач автоматизации бухгалтерского учета, заканчивая программным управлением технологическими процессами. В связи с таким спектром работ чрезвычайно важно уметь правильно идентифицировать класс задачи, которую требуется решить программисту, иначе внедрение любой новой сколько-нибудь сложной технической системы, превращается в головную боль, как для разработчика, так и для группы сопровождения, принимающей новую систему в эксплуатацию. Особенно ярко эта проблема проявляется при решении задачи взаимодействия систем уровня АСУ и уровня АСУТП. Обеспечение такого взаимодействия все чаще является центральным для технических и информационных систем в связи с необходимостью достижения максимального информирования руководящего персонала и достижения наибольшей оперативности в принятии управленческих решений. Однако этот процесс зачастую связан с серьезными ошибками в оценке надежности или быстродействия проектируемой системы. Кроме того, часто возникают скрытые затраты, обусловленные невозможностью замены некоторых аппаратных модулей на близкие по функциональности аналоги по причине жесткой специализации ПО на типе использованного оборудования. Подобные издержки являются досадной помехой на пути технического перевооружения промышленности, которое так необходимо нашей стране для достижения былой экономической мощи. Очевидно, что без четкого понимания фундаментальных принципов построения информационных систем сложно найти решение обозначенных проблем, каким бы мощным инструментом не обладал программист. Поэтому данная статья призвана обозначить суть тех идей, которые легли в основу двух самых мощных и распространенных языков программирования в сфере разработки промышленного ПО – языка C и языка C++.
Все мы прекрасно знаем из курса школьной информатики, что в программировании существуют три базовые конструкции – следование, альтернатива, цикл. Но одним из самых значимых открытий за полувековую историю программирования явилось осознание того факта, что базис этих трех операций является достаточным для построения алгоритма любого уровня сложности. Эта идея, сформулированная А. Тьюрингом, нашла свое продолжение в работах Э. Дейкстры, определившего основные положения методологии структурного программирования, и, тем самым, вызвала настоящий прорыв в цифровых технологиях. Еще одним из фундаментальных открытий в области информатики явилось осознание того, что методология структурного программирования не единственный способ организации алгоритма программы. И с начала 80-х годов XX века объектно-ориентированные принципы построения систем, основанные на наборе трех других базисных операций, охватывают все большие и большие области индустрии информационных технологий. К сегодняшнему дню сложно найти программиста, ни разу, не сталкивавшегося с объектно-ориентированным программированием. Более того, было доказано, что вообще любая методология основывается на базисе трех элементарных операций, называемых комбинаторами. Таковы законы чисел, открытые выдающимся ученым Джоном Фон Нейманом. Но вот откуда происходит этот базис, вопрос более сложный, приводящий нас от принципов построения сетей к кибернетике, от кибернетики к комбинаторике, а от комбинаторики к началам аристотелевской и восточной философии, отражающих природу взаимосвязей между предметами окружающего мира с помощью одной общей идеи.
Наука кибернетика – это более узкое направление, чем философские изыскания, но занимается она как раз изучением природы взаимоотношений элементов в системах. Причем системой может являться, как технический объект, так и отдельно взятый человек, так и человеческое общество, и государство [1]. Поэтому понимание того, что принципы организации алгоритма есть принципы кибернетики, и что они могут быть применены в задачах не только связанных с организацией взаимодействия узлов компьютерной сети, дало качественно новый скачок в развитии информационных систем и технологий, наблюдавшийся в 90-е годы XX века.
Итак, на сегодняшний день программисты владеют как минимум двумя мощнейшими методологиями – объектно-ориентированное и структурное программирование. У каждой из них существует некоторый базис трех элементарных операторов, берущих свое начало от одной фундаментальной идеи – своей для каждого из случаев – идеи взаимодействия компонентов системы или же более кратко – начала кибернетики.
Идея первого начала – принцип разделения времени. Идея второго начала – принцип разделения ресурсов. С каждым из них связан определенный контекст или иными словами – область определения идеи, причем первое начало можно рассматривать, как более частный случай второго, т.к. в общем случае время – тоже ресурс. Однако вследствие значительной разницы в технических средствах реализации этих двух идей, получаемая в итоге система может сильно отличаться по массе критериев, таких как эффективность, надежность и трудозатраты на реализацию, поэтому идеи, формирующие ее фундамент, следует различать.
Первая идея (принцип разделения времени) связана с некоторыми известными ограничениями на ресурсы при решении поставленной проблемы. Считается, что единственный неограниченный ресурс – это время, поэтому решение задачи будет выглядеть, как сумма ее частичных решений, т.е. циклическое потребление всех имеющихся ресурсов каждый дискрет времени до тех пор, пока не будет достигнуто желаемое свойство (цель управления) возбуждаемого объекта.
Вторая идея (принцип разделения ресурсов) предполагает наличие известного ограничение на время решения поставленной задачи. При этом предполагается, что существует бесконечное множество исполняющих устройств, каждое из которых выполняет некоторую часть одной элементарной операции с точки зрения смены устойчивого состояния системы.
Н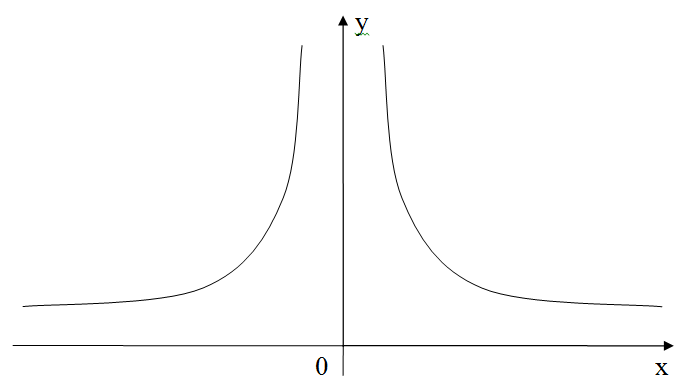 о
самым замечательным свойством всего вышесказанного является то, что
решение любой проблемы можно получить как в рамках первого, так и в
рамках второго начала. Соответственно первое начало положено в основу
методологии структурного программирования и языка C, а второе –
в основу объектно-ориентированного программирования и языка C++.
Однако между началами всегда существует тонкая грань
равноэффективности свойств искомого решения проблемы. Оставаясь на
этой грани, действительно не имеет значения, какой из подходов
выбрать, потому, как в любом случае решение будет содержать слишком
много внутренних противоречий и просто рухнет под их весом. Это можно
себе представить в виде условного графика функции асимптотически
приближающегося к вертикальной оси координат, как с отрицательного,
так и с положительного интервала горизонтальной оси, (рис. 1.). Иными
словами не все задачи могут быть решены на существующем техническом
уровне с необходимыми требованиями (да, такое тоже бывает).
о
самым замечательным свойством всего вышесказанного является то, что
решение любой проблемы можно получить как в рамках первого, так и в
рамках второго начала. Соответственно первое начало положено в основу
методологии структурного программирования и языка C, а второе –
в основу объектно-ориентированного программирования и языка C++.
Однако между началами всегда существует тонкая грань
равноэффективности свойств искомого решения проблемы. Оставаясь на
этой грани, действительно не имеет значения, какой из подходов
выбрать, потому, как в любом случае решение будет содержать слишком
много внутренних противоречий и просто рухнет под их весом. Это можно
себе представить в виде условного графика функции асимптотически
приближающегося к вертикальной оси координат, как с отрицательного,
так и с положительного интервала горизонтальной оси, (рис. 1.). Иными
словами не все задачи могут быть решены на существующем техническом
уровне с необходимыми требованиями (да, такое тоже бывает).
Рис. 1. Кривая сложности системы и «объектной ориентированности»
Где значения y – это мера сложности реализации системы, а x – некоторая обобщенная по совокупности требований оценка степени объектной ориентированности.
Д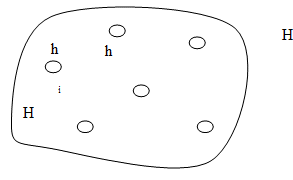
 ля
того, чтобы показать связь между принципом разделения времени и тремя
базисными комбинаторами методологии структурного программирования,
рассмотрим понятие системы. Пусть имеется множество элементарных
узлов hi ϵ H, (рис. 2).
Множество H будет называться системой тогда
и только тогда, когда все его элементы связаны между собой.
ля
того, чтобы показать связь между принципом разделения времени и тремя
базисными комбинаторами методологии структурного программирования,
рассмотрим понятие системы. Пусть имеется множество элементарных
узлов hi ϵ H, (рис. 2).
Множество H будет называться системой тогда
и только тогда, когда все его элементы связаны между собой.
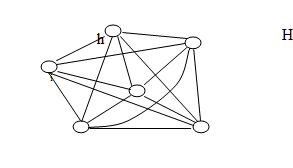
Рис. 2. Совокупность элементарных узлов Рис. 3. Система N к N
Таким образом, набор автономных узлов, без среды передачи информации между ними, системы не образует. Совокупность связей, обеспечивающих информационный обмен между элементами системы, называется сетью. Ее схематическое изображение называется топологией сети.
Теперь рассмотрим другой предельный случай – когда каждый отдельно взятый узел системы имеет независимую связь с каждым из остальных ее узлов (N к N), (рис. 3). Очевидно, что проект такой сети чрезвычайно дорог, как с точки зрения ресурсов необходимых для построения системы, так и с точки зрения ее сопровождения – расширения и поиска неисправности.
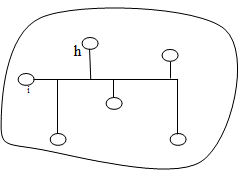
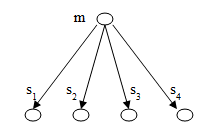
- Рис. 4. Система со
связью по общей шине Рис. 5. Иерархия элементов в системе
Поэтому на практике применяют шинную физическую топологию сети, когда среда информационной связи одна для всех узлов сразу. Такая физическая топология сети накладывает определенные фундаментальные ограничения. Например, при коммуникации двух узлов в данной системе, передающий узел для всей сети может быть только один, а узлы, входящие в сеть, но, которым сообщение не предназначалось, все равно будут его принимать. Т.е. возникает необходимость в фильтрации принимаемых узлом сообщений и в способе передачи, который позволит не нарушать единственность передатчика в момент передачи сообщения.
Последнее требование в первых сетях решалось довольно просто – один из узлов жестко назначался инициатором информационного обмена на шине (главным узлом), а прочие узлы всегда находились в режиме прослушивания. Т.е. никакой другой узел, кроме главного начинать передачу права не имел. Такой организации уже достаточно, чтобы осуществить однонаправленную передачу от инициирующего узла своим подчиненным. В сетевой терминологии узел, инициирующий передачу информации по шине, называют ведущим (master), а узел, который прослушивает среду, – ведомым (slave). Логическая топология данной системы будет иметь вид, представленный на рис. 5.
Для работоспособности обозначенной системы необходимо строгое последовательное и циклическое соблюдение порядка обращения к подчиненным узлам. Другими словами, коммуникационная среда (сеть) в один момент времени передает сообщение узлу s1, следующий момент времени – узлу s2, следующий момент времени – узлу s3, и т.д. пока не завершится обход всех подчиненных узлов системы. Данный алгоритм формирует одну итерацию цикла работы системы. Иными словами, время работы системы разделяется на непересекающиеся интервалы-обходы подчиненных элементов, а они в свою очередь – на интервалы последовательного доступа к среде для осуществления передачи сообщения между ведущим и ведомым узлами. Результатом такой декомпозиции является мера разделения времени или, выражаясь в терминах языка C, функция. Задача же фильтрации сообщения каждым из ведомых узлов решается путем сопоставления адресной части заголовка сообщения с собственным адресом узла. В результате такого сопоставления возможно лишь две альтернативы – сообщение предназначено другому узлу, поэтому должно быть проигнорировано, либо сообщение предназначено этому узлу и должно быть обработано.
Итак, теперь у нас имеются все три базисных комбинатора структурного программирования – следование, альтернатива, цикл.
Но, чтобы осуществить двунаправленную передачу данных, этого мало, поэтому был принят протокол (правило передачи сообщений), согласно которому на ведущий узел возлагается обязанность после передачи команды ведомому узлу ждать от него ответного сообщения. Т.е. ведомый узел может инициировать передачу в сеть только в ответ на запрос ведущего. Алгоритм ведомого узла несколько усложняется, но теперь в системе появились обратные связи, и стал возможен двунаправленный обмен сообщениями порядка 1 к 1 через ведущий узел. Поскольку теперь ведущий узел может играть роль концентратора данных, на его стороне возникает проблема хранения информации. Эта проблема разрешается в виде определения фиксированной структуры хранения данных. Структура представляет собой двумерный массив (таблицу), каждая из строк которого отражает итерацию цикла получения данных, а каждый элемент этой строки – сообщение, полученное от узла. Такой элемент обычно представляет собой блок данных регулярного размера, индивидуального для каждого из опрашиваемых узлов (структурный тип языка C). Поскольку по своей природе система подразумевает присутствие ограничения по объему доступных ресурсов (в данном случае памяти), то таблица данных, как правило, создается единожды на этапе проектирования системы с помощью оценки числа максимального числа хранимых узлом строк. Это число рассчитывается путем деления всего объема доступной памяти на объем памяти, необходимый для хранения одной строки. Объем же памяти для хранения строки рассчитывается, как сумма затрат памяти на хранение результата запроса к каждому из подчиненных узлов в рамках одной итерации опроса. Если система состоит из нескольких уровней, то некоторые ведущие узлы выступают в роли ведомых на уровне выше. Так формируется иерархия памяти – чем больше объем памяти узла в системе, тем он выше в иерархии и тем медленнее в нем происходят процессы извлечения и записи информации. Кроме того, в промышленных системах часто пространство памяти данных делают в виде циклического буфера. Т.е. при заполнении всех строк таблицы в памяти ведущего узла, система не останавливается, а начинает запись новой строки поверх наиболее старой сохраненной, вследствие чего ведущие узлы редко когда хранят все данные с момента первого включения системы. Например, объем сохраняемых данных на узлах самого низкого уровня может составлять 5 минут, выше – сутки, еще выше – месяц, еще более высокий уровень иерархии памяти способен сохранять годы результатов опроса всех узлов системы. Этого оказывается вполне достаточно, для принятия, как технологических управленческих решений, так и решений бизнес уровня, например, снабжения сырьем. После создания первых работоспособных систем, такой способ организации системы получил широкое распространение и в несколько модифицированном виде до сих пор актуален для множества промышленных систем, основанных на сетях RS-232, RS-485, PROFIBUS-DP (курс SIEMENS по сетям типа PROFIBUS). Более того, одно время даже считалось, что получить работающую систему, основанную на других принципах взаимодействия узлов, делящих общую шину, невозможно – такова уж природа человеческого сознания, склонная к догматическому мировоззрению.
Но прогресс не стоит на месте, и по мере развития информационных систем и сетей недостатки структурного подхода стали носить все более ярко выраженный характер. Одним из таких недостатков является проблема роста числа узлов в сети. Очевидно, что для подключения нового узла в систему необходимо перенастройка ведущего узла. Останов ведущего равносилен останову всей системы, так же как и ошибка в его настройке. Сама же настройка заключается не только в доработке алгоритма опроса, но и в проектировании заново двумерного массива памяти ведущего узла, что неизбежно влечет к изменению такой характеристики, как максимальный объем итераций опроса, хранимых узлом. Последняя операция может спровоцировать перенастройку всех вышестоящих ведущих узлов системы. Другой (и главный) недостаток кроется в самой идее, образующей архитектуру.
У информации есть такое важное свойство, которое плохо сочетается со структурным подходом – она способна устаревать. Таким образом, выдвигается требование на время получения данных с нижних уровней системы. Это время может быть легко превышено, потому что каждому подчиненному узлу нужно дождаться своей очереди запроса от ведущего. Более того, появление информации часто связано с некоторыми изменениями состояния системы, которые в общем случае могут происходить случайным образом. Поэтому часто опрос подчиненных узлов с точки зрения получения новой, неизвестной ранее информации становится избыточен. В рамках структурного подхода существует два возможных решения этой проблемы – экспоненциальное увеличение быстродействия сети и ведущего узла по мере роста числа подчиненных узлов, либо предсказание ведущим узлом, в каком из подчиненных должно возникнуть событие. Первое решение связано с нерациональным расходованием аппаратных ресурсов (NP-задачи), второе же – с одной из фундаментальных проблем науки в целом – предсказания будущего (НМТ). Очевидно, требуется совершенно иной принцип логической организации системы – принцип разделения ресурсов.
Пусть имеем, как и прежде, шинную физическую топологию сети информационной системы (рис. 4). Как и прежде, при коммуникации двух узлов в данной системе, передающий узел для всей сети может быть только один, а узлы, входящие в сеть, но, которым сообщение не предназначалось, все равно будут его принимать. По-прежнему возникает необходимость фильтрации принимаемых узлом сообщений и способ передачи, который позволит не нарушать единственность передатчика в момент передачи сообщения. Пусть инициатором обмена может быть любой из узлов сети. Очевидно, возникает проблема одновременной передачи сообщения в сеть более чем одним узлом. Но у этой проблемы существует решение – протокол CSMA/CD (IEEE-802.3). Идея нового протокола сводится к тому, что каждый узел начинает передачу, если ему есть что передавать, и если сеть (среда передачи) еще не занята передачей от другого узла, инициировавшего обмен ранее. Несмотря на такую предосторожность, все еще сохраняется вероятность начала одновременного вещания двух узлов в сеть. Такая ситуация обнаруживается при несоответствии сигнала на порту передачи и на порту приема и считается исключительной. Последнее означает, что вероятность ее возникновения мала, что она неизбежна, и что она обрабатывается алгоритмом особым образом. В сетевой терминологии ее называют коллизией и обрабатывают путем установки паузы в вещании на случайный интервал времени для каждого из узлов, ее спровоцировавших. Если рассматривать только одностороннюю передачу данных, то логическая организация сети будет выглядеть следующим образом (рис. 6).
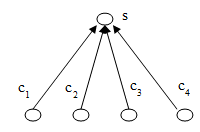
Рис. 6. Иерархия элементов в системе, работающей по протоколу CSMA/CD
Такая архитектура системы носит название клиент-серверной. Если в сети только один узел-сервер и несколько узлов-клиентов, причем узел-сервер занимается исключительно обработкой запросов клиентов (т.е. никогда не инициирует обмен), а узлы-клиенты – соответственно выполняют только инициацию обмена и никогда не выполняют роли сервера по отношению к другим узлам, то фильтрация сетевых сообщений, выполняемая каждым узлом, становится избыточной. Однако для работоспособности системы необходимо соблюдение трех существенных условий.
При загрузке сети порядка 30% от номинальной пропускной способности алгоритм обработки коллизии начинает завершаться новой коллизией, [2]. Т.е. события в системе между узлами возникают настолько плотным потоком, что все попытки передать сообщение серверу оканчиваются одновременным вещанием в сеть с более чем одного узла. В таком состоянии передача данных по сети происходить не будет. Именно поэтому для исключительных ситуаций подчеркивается, что частота их появления по сравнению с частотой возникновения событий в системе мала. Иными словами требуется малая плотность потока событий в рамках одной линии передачи. Процесс поиска набора характеристик (свойств) группы узлов, реализующего данное требование, называется инкапсуляцией, а результатом его является определение класса – меры разделения ресурсов системы. Тогда узел в соответствии с терминологией ООП называют экземпляром класса или объектом. Если в рамках одной системы существуют более одного класса узлов, то для каждого из классов должна быть выделена собственная линия связи (шина) к серверу. Такова расплата за актуальность получаемой информации.
Система также не будет работать, если одно из событий в узле-клиенте привело к продолжительному потоковому вещанию к узлу-серверу. Тогда ни один из клиентов, кроме вещающего, не сможет получить доступа к среде передачи, и актуальность информации будет утрачена. Такую ситуацию можно назвать по аналогии с моделью экономики свободного рынка монополизацией. Т.е. должен соблюдаться принцип равноправия доступа к сети. Иными словами время передачи сообщения от клиента к серверу должно быть ограничено. В рамках же всей системы каждый из клиентов обязан соблюсти это условие. Однако, чем большее число клиентских узлов имеет система, тем сложнее гарантировать, что ни один из них не захватит среду передачи на время большее, чем диктуют требования. Кроме того, часто при проектировании возникает ситуация, когда требования к ограничению по времени пересматривают. Поэтому необходимо средство, позволяющее с минимальными трудозатратами гарантировать соблюдение новых условий работы системы. Решение этой проблемы достигается применением механизма наследования, результатом действия которого является набор классов отличных друг от друга теми или иными свойствами, но каждый из которых подчиняется набору одних общих требований.
Таким образом, классы объединяются в иерархию наследования, изображаемую, как правило, направленным ациклическим графом (Directed Acyclic Graph – DAG).
Если количество классов
более одного, то необходимо подсоединить более одной линии связи к
узлу серверу. Однако если узел-сервер способен выполнять только один
процесс одновременно, то он не сможет обработать запросы от других
сегментов системы, поскольку будет тратить все свое время на ожидание
события на первом сегменте. Поэтому физически система с двумя
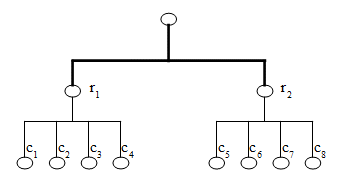
классами будет выглядеть следующим образом, (рис. 7). П![]() ри
этом сегмент r1, r2
– s должен иметь пропускную
способность на порядок выше, чем сегмент нижестоящего уровня,
например c1, .., c4 –
r1 , иначе суммарная плотность
потока опять будет приводить к состоянию постоянной коллизии, [2].
Хитрость в том, что при суммарном физическом расстоянии между узлами
r1, r2
– s меньшем, чем между c1,
.., c4 – r1
достичь большей пропускной способности гораздо проще. Узлы r1,
r2 в данной системе будут играть
роль повторителей (repeater).
ри
этом сегмент r1, r2
– s должен иметь пропускную
способность на порядок выше, чем сегмент нижестоящего уровня,
например c1, .., c4 –
r1 , иначе суммарная плотность
потока опять будет приводить к состоянию постоянной коллизии, [2].
Хитрость в том, что при суммарном физическом расстоянии между узлами
r1, r2
– s меньшем, чем между c1,
.., c4 – r1
достичь большей пропускной способности гораздо проще. Узлы r1,
r2 в данной системе будут играть
роль повторителей (repeater).
![]()
Рис. 7. Топология трехсегментной клиент-серверной сети
О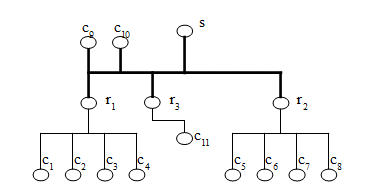 днако
к линии r1, r2
– s не обязательно должны быть
подключены только один сервер и произвольное количество репитеров
(повторителей). Вполне допустимо прямое подключение узлов к
высокоскоростной шине. Топология сети тогда примет вид (рис. 8).
днако
к линии r1, r2
– s не обязательно должны быть
подключены только один сервер и произвольное количество репитеров
(повторителей). Вполне допустимо прямое подключение узлов к
высокоскоростной шине. Топология сети тогда примет вид (рис. 8).
![]()
Рис.8. Топология четырехсегментной клиент-серверной сети
Иными словами, к какому бы сегменту сети не был подключен узел (c1 c5 c9, c11), событие, произошедшее в нем, всегда найдет путь к узлу-серверу и будет обработано, при этом самому узлу не требуется знать топологию сети. Это явление называется принципом прозрачности (transparency) и является важнейшей причиной масштабируемости объектно-ориентированных систем. Единственное требование, которое налагается на узел – способность вещать на шину с требуемой скоростью. Очевидно, что для построения такой системы достаточно только двух рассмотренных комбинаторов – инкапсуляции и наследования. Но в общем случае узлы-клиенты не произвольно генерируют события, а лишь отвечают таким способом на обнаруженные ими воздействия во внешней среде системы. При этом ничто не мешает узлам-клиентам обрабатывать такие воздействия локально, а информацию на сервер отправлять блоком при накоплении определенного числа воздействий. Естественно, что в таком случае получаемая сервером информация будет снова терять актуальность. Механизм полиморфизма реализует делегирование (ретрансляцию) обработки каждого внешнего для системы воздействия серверному узлу системы, обеспечивая гарантированную актуальность получаемой сервером информации. Т.е. каждый узел-клиент работает, как репитер rn, согласовывая различные виды физического представления информационного сигнала. В терминах языка C++ это достигается с помощью определения и переопределения виртуальных методов в иерархии классов и механизмом перегрузки.
Итак, имеем три базисных операции для построения объектно-ориентированной системы – инкапсуляцию, наследование и полиморфизм. Соответствующим им операциям при проектировании сети являются:
обособление одного или более узлов в независимый сегмент для снижения плотности потока событий на линии связи;
форсирование времени вещания для каждого из узлов-клиентов в канал;
форсирование единственной роли для узлов-клиентов в каждом из сегментов сети – ретрансляции внешнего воздействия в среду передачи, образующую сегмент.
Однако при реализации данной архитектуры возникает одна непростая проблема – согласование данных на стороне узла-сервера. Это, на самом деле, трудная задача, так как порядок обращения клиентов к серверу недетерминирован (случаен), и потому уже невозможно обойтись просто последовательной записью принимаемых сообщений в двумерный массив регулярной структуры.
Рассмотрим случай концентрации информации в узле-сервере на базе двумерного массива регулярной структуры. Очевидно, элемент строки массива должен иметь размер равный самому длинному из возможных сообщений. В таком случае затраты памяти будут неприемлемы, складываясь из затрат на незаполненные элементы строки таблицы и затрат на неполное использование памяти под элемент.
Если же данные записывать последовательно вместе с адресами их приславших узлов, то при выборке информации накладные расходы на поиск будут расти пропорционально квадрату длины всего объема хранимых данных (линейный поиск). Очевидно, что для уменьшения времени поиска следует данные определенным образом упорядочить. Нахождение решения именно этой проблемы и стало одной из главных задач реляционной теории построения баз данных. Возможно, поэтому в литературе иногда упоминается о том, что развитие реляционной теории послужило толчком к становлению ООП. Наиболее распространенный прием поддержания упорядоченной структуры данных в памяти заключается в ее динамическом разделении на списки, соответствующие тому или иному узлу. Таким образом, линейный поиск можно вести на гораздо меньшем объеме данных.
С первого взгляда может казаться, что в решении задачи нет ничего сложного – достаточно разделить всю память на блоки, по одному на каждый тип событий, а внутри них распределять память по мере поступления данных (формировать стек). Но на самом деле, поскольку события на стороне клиентов недетерминированы, то очень скоро начнет образовываться перекос в объеме заполнения блоков данными. Для его устранения необходимо будет переупорядочить блоки и их начальные адреса (сжать память). Такая операция опять же будет достаточно затратной, плюс появятся проблемы со ссылками на перемещенные блоки, которые надо будет отследить и откорректировать.
К счастью, стандартная библиотека C++ (ISO/IEC 14882-1998) берет решение задачи динамического управления памятью на себя, предоставляя программисту совокупность базовых классов-контейнеров с соответствующими оценками эффективности манипуляций над ними. Строго говоря, международный стандарт языка C ISO/IEC 9899-1990 уже более 20 лет определяет элементарный набор функций динамического распределения памяти – calloc(), malloc(), realloc(), free(), предоставляющих программисту согласованный и не зависящий ни от операционной системы, ни от типа процессора функциональный интерфейс. Однако решение в языке C++ поднимает программирование на ступеньку выше, чем просто разделение памяти. Оно позволяет сразу же перейти к решению задачи предметной области, не отвлекаясь на технические аспекты ее решения в ООП методологии, а затем, по мере уточнения требований к эффективности программы, заменять одни классы-контейнеры другими и «доводить» слабые места алгоритма путем использования более специализированных для выбранной динамической структуры методов, ([3]). Однако, как показывает практика, до сих пор в современных семействах операционных системах, таких как Windows XP-7, *NIX даже реализация набора функций C, увы, оставляет желать лучшего. Поэтому одной из первых задач, с которой приходится столкнуться при решении объектно-ориентированных задач – создание собственного менеджера памяти. К счастью, библиотека C++ является настолько гибкой, что позволяет интегрировать пользовательский менеджер памяти в стандартные классы-контейнеры, ([3]). Усилиями А. Александреску, реализовавшим такой менеджер в своей библиотеке Loki (основанной на стандарте C++ ISO/IEC 14882-1998), эта проблема была практически снята, ([4]). Тем не менее, рассмотрим, как комбинаторы ООП образуют фундамент динамического разделения памяти.
Представим менеджер памяти в виде клиент-серверной сети с переменной структурой. Используя комбинатор инкапсуляция, определим множество сегментов сети, соответствующих каждый некоторому регулярному размеру распределяемой памяти. В программе потребуется определить множество классов-аллокаторов. Используя комбинатор наследование, форсируем для всех аллокаторов максимально допустимое время на распределение блока. В программе необходимо будет создать базовый для всех аллокаторов класс и запрограммировать для него генерацию исключений в случаях, когда накладные расходы превышают допустимый предел. Используя комбинатор полиморфизм, форсируем ретрансляцию обработки запроса на распределение от конкретного класса-аллокатора к базовому классу-аллокатору через все промежуточные узлы DAG. В программе необходимо будет определить и реализовать метод распределения памяти в качестве виртуального. Вторая проблема, которая возникнет в результате применения полиморфизма, – проблема виртуального конструирования конкретного класса-аллокатора в зависимости от того, в какой сегмент нашей воображаемой сети попадает размер блока памяти, который нас просит выделить клиент. Реализация виртуального конструктора наиболее подробно описана в фундаментальной работе «банды четырех» Э.Гамма и соавторов [5].
Наконец, рассмотрим случай, когда клиент-серверная система превращается в одноранговую. В одноранговой системе роль узла-сервера и роль узла-клиента более жестко не разделена. Каждый узел может играть как роль сервера, так и роль клиента, поэтому данные могут передаваться по сети к любому из узлов. Соответственно, поскольку все узлы находятся в едином широковещательном диапазоне, необходимо вновь производить фильтрацию пакетов по типу свой-чужой. Таким образом, 3 комбинатора ООП дополняются 3 комбинаторами структурного программирования. В данном случае – вводится комбинатор альтернатива. Поскольку узлы-ретрансляторы теперь должны передавать трафик не только от менее скоростного сегмента к более скоростному, но и обратно, то возможна ситуация, когда с высокоскоростной линии поступает больше запросов, чем способна передать в этот момент времени низкоскоростная сеть. В конечном итоге, это ведет к отбрасыванию «лишних» пакетов, поэтому узел-отправитель должен циклически повторять передачу до ее успешного приема на другом конце сегмента. Об успешном приеме узлу сообщается с помощью пакета-квитанции с принимающей стороны, поэтому этот режим передачи еще иногда называют передача с квитированием. И, наконец, чтобы снизить накладные расходы, вызываемые повторными передачами сообщений в сегменте, на узле-ретрансляторе используется внутренняя память для построения последовательности сообщений (очереди), передаваемых на другой сетевой интерфейс узла, – так повторно вводится комбинатор следование.
В заключение следует отметить, что язык C++ сохраняет обратную совместимость с языком C (с некоторыми оговорками). И это решение совсем не случайно, потому как первая реализация C++ основывалась на C, а, в конечном итоге, даже система, которая была изначально построена на объектно-ориентированных началах, выявляет потребность в трех комбинаторах структурного уровня. Очевидно, что незачем изобретать новый язык, чтобы реализовать в нем уже ранее известные принципы. Однако C не всегда был таким, каким его определяет стандарт ISO/IEC 9899-1990. Развитие понимания объектно-ориентированных принципов построения систем и их взаимосвязи со структурными принципами в конечном итоге сделали C гораздо выразительнее и согласованнее, тем самым определив этот язык как самый совершенный инструмент проектирования ПО в структурной методологии.
Благодарим наших «Родителей, трепетных Муз и творческое окружение» за то, что даруете нам силы и решимость восходить даже, когда мы вынуждены, шагать в темноту.
Литература:
Большая советская энциклопедия. Глушков В.М. «Кибернетика». — http://goo.gl/lWvi0
Олифер В.Г., Олифер Н.А. Компьютерные сети. Принципы, технологии, протоколы. Издание 4-ое. — СПб.:Питер, 2010. — 943 с.
Страуструп Б. Язык программирования C++. — М.: Бином-Пресс, 2007. — 1104 с.
Александреску А. Современное проектирование на C++. — М.:Вильямс, 2002. —326 с.
Гамма Э., Хелм Р., Джонсон Р., Влиссидес Дж. Приемы объектно-ориентированного проектирования. Паттерны проектирования. – СПб.: Питер, 2001. – 368 с.