





Электронные архивы документов позволяют накапливать большие массивы документации: финансовой, конструкторской, уставной и др. Одной из важнейших функций архива является быстрый и удобный поиск необходимых документов. Методы поиска в архиве были описаны в статье [1]. Они включают в себя поиск по значениям атрибутов документа и полнотекстовый поиск по содержанию документа. Однако не всегда требуется найти только один документ определенного типа, зачастую требуется найти набор технической документации по конкретному объекту или набор финансовых документов с определенным контрагентом. Для группировки документов можно использовать механизм пакетов – логических групп документов.
В системе «ДокПрофи™» первоначальное разбиение на пакеты происходит при загрузке документов в архив. Во-первых, автоматически создаются пакеты текущей даты в формате «Год» => «Месяц» => «День». Во-вторых, мастер загрузки документов, описанный в статье [2], позволяет работать с пакетами: создавать, изменять, удалять, наполнять. Аналогичные операции также можно выполнять в Web-интерфейсе, описанном в статье [2]. Однако ручное разбиение документов на пакеты может быть трудоемкой работой. Рассмотрим пример (рис. 1)
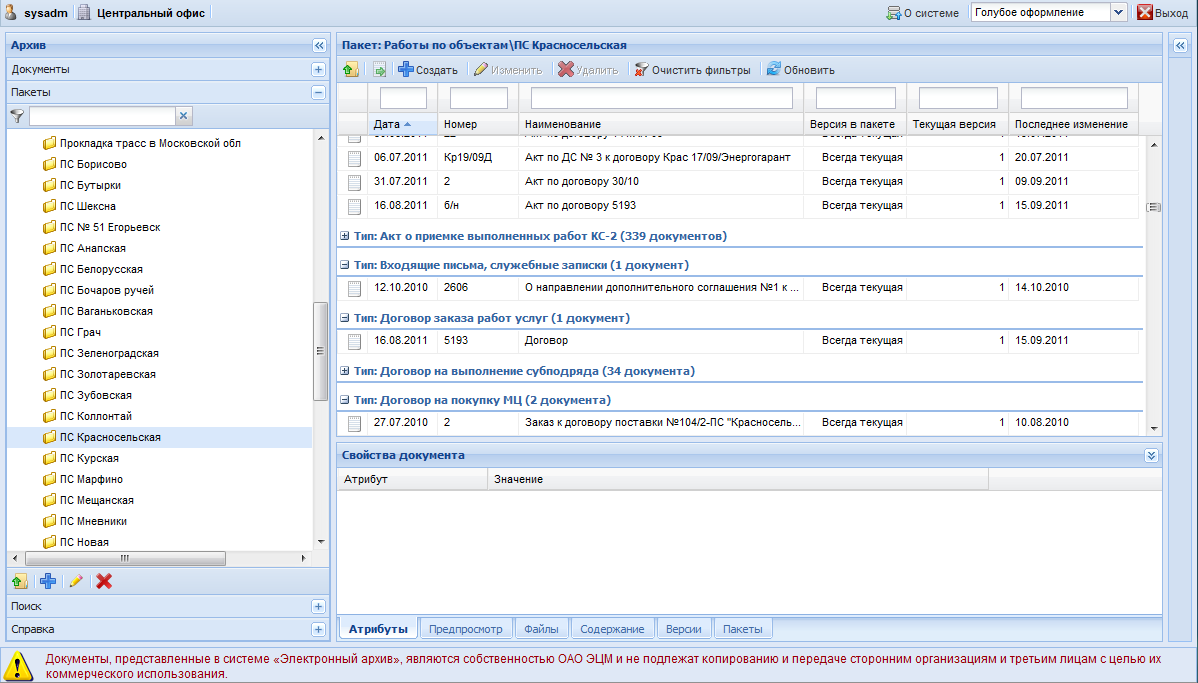
Рис. 1. Набор документации по объектам
Пусть документация по объектам первоначально сгруппирована по пакетам. В каждом пакете находится множество документов различных типов: договоры и соглашения, акты, счета, накладные, корреспонденция и другие. При этом работы на объекте могут выполняться различными подрядчиками, причем с одним и тем же подрядчиком может быть заключено несколько договоров на разные виды работ. Однако при подготовке отчетов, например, для налоговой службы, необходимо выбрать документы по определенному договору. Для этого выполним разбиение документов на подпакеты, используя методы кластеризации, описанные в статье [3].
Анализируя документы по объекту, наметим будущую структуру пакетов в виде следующей иерархии:
документ от внешнего контрагента или филиала организации;
наименование контрагента;
номер договора;
тип документа;
дата и номер документа. Это необходимо, например, для группировки актов о приемке выполненных работ КС-2 и справок о стоимости выполненных работ и затрат КС-3, которые должны иметь соответствие. При этом одной справке КС-3 могут соответствовать несколько актов КС-2.
Сформируем кластеры по алгоритму, описанному в статье [3]. Например, выберем документы типа «Счет-фактура», этот тип содержит атрибуты «Поставщик» и «Адрес поставщика». В статье [4] описан метод полного вероятностного справочника, заключающийся в последовательном переборе документов и подсчете вероятностей появления пар значений атрибутов. Применяя данный метод, получим справочник, то есть набор правил вида:
«Если
![]() ,
то
,
то
![]() с вероятностью
с вероятностью![]() »,
где
»,
где
![]() – атрибут «Поставщик»,
– атрибут «Поставщик»,
![]() – атрибут «Адрес поставщика». Например, можно
получить следующие правила:
– атрибут «Адрес поставщика». Например, можно
получить следующие правила:
если «Поставщик» = «Новомосковское управление филиал ОАО "Электроцентромонтаж"», то «Адрес поставщика» = «301603, Тульская обл, Новомосковский р-н, Новомосковск г,Транспортная 1-я ул, дом № 5а» с вероятностью 62%;
если «Поставщик» = «Новомосковское управление филиал ОАО "Электроцентромонтаж"», то «Адрес поставщика» = «301603, Тульская обл, Новомосковский р-н, Новомосковск г, Транспортная 1-я ул, дом № 5а, тел.: (48762) 7-15-82» с вероятностью 15%;
если «Поставщик» = «Новомосковское управление филиал ОАО "Электроцентромонтаж"», то «Адрес поставщика» = «301651 г Новомосковск Тульской обл , ул Транспортная, 5а» с вероятностью 23%.
Как видно, при одном и том же значения атрибута «Поставщик» существуют разные варианты написания атрибута «Адрес поставщика», хотя по сути это также одно значение. Поэтому все подобные значения следует объединить в один кластер. Для этого выполняются шаги кластеризации по следующему принципу:
выбираем все правила с одинаковым значением атрибута «Поставщик», например, «Новомосковское управление филиал ОАО "Электроцентромонтаж"».
составляем множество P соответствующих значений атрибута «Адрес поставщика».
ищем все правила, где значение атрибута «Адрес поставщика» равно одному из значений множества P.
все значения атрибута «Поставщик» из этих правил включим в множество C. Например, это могут быть значения «НМУ филиал ОАО "Электроцентромонтаж"», «Новомосковское управление» и другие.
далее шаги кластеризации повторяются для всех элементов множества C до тех пор, пока оно не перестанет изменяться.
Аналогичные кластеры создадим на основе пар атрибутов «Поставщик» - «ИНН поставщика» и «Продавец» - «ИНН продавца». Соответственно, получаем кластеры организаций. Для определения, внешняя это организация или внутренняя используем простое правило: «Если хотя бы одно наименование организации содержит в себе наименование основной организации ("Электроцентромонтаж"), то это внутренняя организация». Далее документы необходимо разбить по организациям. Однако надо учесть, что искомое наименование в разных типах может храниться в разных атрибутах. Например, в документах типа «Дополнительное соглашение» организация хранится в атрибуте «Контрагент», в документах типа «Акт о приемке выполненных работ КС-2» - в атрибуте «Подрядчик» и так далее.
Далее документы, содержащие информацию о номере договора, можно разделить по этому номеру. При этом необходимо учесть, что в самих договорах, наряд-заказах и дополнительных соглашениях номер хранится в поле «Номер», а в документах типа «Акт о приемке выполненных работ КС-2» и «Справка о стоимости выполненных работ и затрат КС-3» он хранится в поле «Договор подряда»
В результате всех операций получим дерево пакетов, приведенное на рис. 2
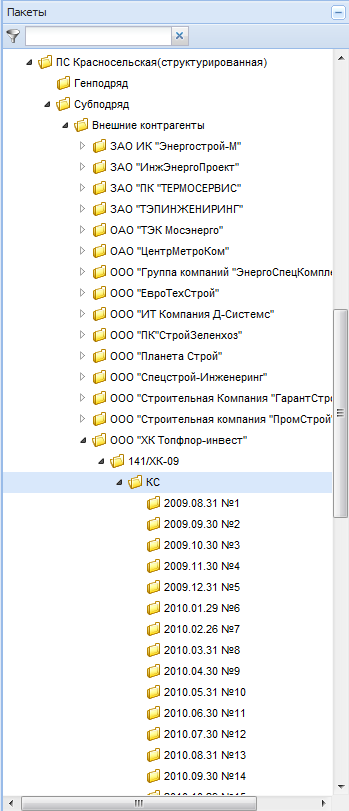
Рис. 2. Дерево пакетов после выполнения операций
Таким образом, с помощью методов кластеризации была проведена реорганизация структуры пакетов, что позволяет упростить поиск нужных документов. Также архив поддерживает пакетную печать документов, то есть позволяет напечатать сразу все документы одного пакета. Соответственно при введении структуры пакетов подготовка отчета по определенному объекту, договору или номеру акта КС-2 значительно упрощается.
Литература:
Кроль Т.Я. Методы поиска в электронном архиве / Т.Я.Кроль, М.А.Харин, Н.В.Никоноров, Д.В.Иванов // Информационные технологии моделирования и управления. – 2011. - № 6. - С. 702-709.
Кроль Т.Я. Опыт построения и реализации электронного архива на базе системы сканирования и распознавания Flexi Capture / Т.Я.Кроль, М.А.Харин // Программная инженерия. – 2012. -№6. – С. 35-42.
Кроль Т. Я. Методы решения задачи кластеризации и прогнозирования в электронном архиве [Текст] / Т. Я. Кроль, М. А. Харин // Молодой ученый. — 2011. — №6. Т.1. — С. 135-137.
Кроль Т.Я. Методы создания справочника на основе электронного архива / Т.Я. Кроль, М.А.Харин, П.В.Евдокимов // Известия КБНЦ РАН. – 2011. – №1.
Дюк В.А. Data Mining - интеллектуальный анализ данных. – Режим доступа: http://www.olap.ru/basic/dm2.asp, свободный.