





Актуальность и цели. В данной работе производится анализ логарифмических доходностей акций, входящих в состав российского IT сектора. Предполагается, что дневная логарифмическая доходность распределена по нормальному закону. Цель работы — проверить гипотезу о нормальном распределении дневных логарифмических доходностей на реальных данных. С экономической точки зрения задача исследования — определить таймфреймы и промежутки времени, на которых логарифмические доходности будут иметь нормальное распределения, а также те, на которых условия не выполняются. Помимо этого, необходимо выяснить, как повлияло изменение цен акций в 2022 года на сектор информационных технологий. В дальнейшем эту информацию можно использовать для прогнозирования цен акций исследуемых компаний. Для проверки используется критерий Шапиро — Уилка, являющийся одним из наиболее эффективных критериев. После этого проверяется гипотеза на реальных данных и вычисляется процент проверок, в которых гипотеза будет приниматься при уровне значимости в 5 % и 1 %.
Временной отрезок для рассмотрения: 01.01.2022–31.12.2022
Ключевые слова : логарифмическая доходность, уровень значимости, нормальное распределение, проверка гипотезы
Введение
Информационный сектор играет важную роль в экономике России и является одной из самых быстро развивающихся отраслей. Он включает в себя производство и распространение информационных товаров и услуг, таких как программное обеспечение, интернет-сервисы, мультимедиа-контент и многое другое. Информационные технологии также широко применяются в других отраслях, таких как финансы, производство, здравоохранение, транспорт и телекоммуникации.
Вклад информационного сектора в экономику России растет из года в год. Согласно отчету Аналитического центра при Правительстве Российской Федерации, в 2020 году доля информационных технологий в ВВП России составила 4,5 %, а объем рынка информационных технологий оценивался в 3,4 трлн рублей.
Этот сектор является ключевым для развития экономики России, поскольку способствует созданию новых рабочих мест, привлечению инвестиций, улучшению качества жизни и повышению конкурентоспособности страны в мировом рынке. Более того, информационные технологии могут существенно повысить эффективность работы государственных органов и бизнеса, что в свою очередь ведет к увеличению производительности и экономического роста.
С экономической точки зрения, оценивается изменение цен акций в 2022 году в сектор информационных технологий. Определение на каких промежутках логарифмические доходности имели нормальное распределение позволит спрогнозировать дальнейшее изменение в данном секторе.
Основная часть
Для проверки критерия были взяты акции компаний, которые входят в сектор информационных технологий, а именно:
YNDX — Яндекс
HHRU — HeadHunter
VKCO — Вконтакте
OZON — Озон
MTSS — МТС
POSI — Positive Technologies
SFTL — Softline
Для того чтобы использовать эти данные для проверки нормальности по критерию Шапиро — Уилка, необходимо провести их предварительный анализ. В первую очередь, посчитаем логарифмические доходности акций.
1 Теоретическая справка по проверке гипотез
1.1 Статистическая проверка гипотез
Статистическая гипотеза — это любое утверждение о виде или параметрах генерального распределения. Гипотезу называют основной и обозначают




Пусть










Использование статистического критерия может привести к ошибкам двух типов, которые приведены в таблице 1:
-
Ошибка первого рода заключается в том, что отвергается верная гипотеза
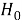
-
Ошибка второго рода заключается в том, что отвергается верная гипотеза
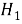


При этом, уровнем значимости критерия называется вероятность ошибки первого рода и обозначается



Таблица 1
Гипотезы
|
H 0 верна |
H 0 неверна |
|
|
H 0 отвергается |
Ошибка I рода |
+ |
|
H 0 не отвергается |
+ |
Ошибка II рода |
Для реализации








Предполагается, что Р-значение






Рассматривается отдельно случай






1.2 Критерий Шапиро — Уилка
В данной работе используется критерий Шапиро — Уилка. Он используется для проверки гипотезы H 0 : «случайная величина X распределена нормально».
Критерий Шапиро — Уилка основан на анализе линейной комбинации разностей порядковых статистик. Критерий применяется при объемах выборки от 3 ≤ n ≤ 50, так как табулированы константы, необходимые для вычисления статистики критерия и аппроксимации P-значения.
Пусть имеется выборка






Значение k в последней формуле определяется следующим образом:



Нормальная аппроксимаций используется для вычисления реально достигнутого уровня значимости:





Если

Ж. П. Ройстон предложил другой способ вычисления P-значения для n вплоть до 2000:













Таблица 2
Коэффициенты
|
Параметр |
n |
Коэффициенты |
||||||
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
||
|
|
7–20 |
0,118898 |
0,133414 |
0,327907 |
||||
|
21–2000 |
0,480358 |
0,318828 |
0 |
-0,02417 |
0,008797 |
0,00299 |
||
|
|
7–20 |
-0,37542 |
0,492145 |
-1,12433 |
-0,19942 |
|||
|
21–2000 |
-1,91487 |
-1,37888 |
-0,04183 |
0,1066339 |
-0,03514 |
-0,01506 |
||
|
|
7–20 |
-3,15805 |
0,729399 |
3,01855 |
1,558776 |
|||
|
21–2000 |
-3,73538 |
-1,01581 |
-0,33189 |
0,1773538 |
-0,01639 |
-0,03215 |
0,003853 |
|



2 Проверка гипотезы на реальных данных
В данном разделе анализируются данные логарифмической доходности и применяется к ним критерий Шапиро — Уилка. Далее выбираются данные, в которых гипотеза принимается при 5 % и 1 % уровнях значимости. Строиться ряд гистограмм и делаются выводы.
Для удобства использования уровни значимости будут отмечаться следующим образом: 5 % — 0.12 , 1 % — 0.02
2.1 Гипотеза о нормальности распределения логарифмической доходности для периода в 6 месяцев
Далее анализируются данные на промежутке в 6 месяцев. Результаты приведены в таблице 3.
Таблица 3
Проверка критерия на промежутке в 6 месяцев
|
01.01.2022–30.06.2022 |
01.07.2022- 31.12.2022 |
|
|
HHRU |
0.0 |
0.0 |
|
VKCO |
0.0 |
0.0 |
|
MTSS |
0.0 |
0.0 |
|
POSI |
0.0 |
0.000348 |
|
SFTL |
0.0 |
0.0 |
|
OZON |
0.0 |
0.0 |
|
YNDX |
0.0 |
0.000006 |
Из таблицы следует, что на временных промежутках в 6 месяцев p-значение выше 1 % не имела ни одна компания.
2.2 Гипотеза о нормальности распределения логарифмической доходности для периода в 3 месяца
Проверяются данные на промежутке в 3 месяца. Результаты приведены в таблице 4.
Таблица 4
Проверка критерия на промежутке в 3 месяца
|
1 квартал |
2 квартал |
3 квартал |
4 квартал |
|
|
HHRU |
0.000075 |
0.916383 |
0.006304 |
0.000123 |
|
VKCO |
0.0 |
0.041 |
0.000557 |
0.301379 |
|
MTSS |
0.0 |
0.0 |
0.0 |
0.185686 |
|
POSI |
0.000001 |
0.000001 |
0.006477 |
0.137620 |
|
SFTL |
0.0 |
0.001329 |
0.0 |
0.0 |
|
OZON |
0.006810 |
0.174743 |
0.000477 |
0.0038 |
|
YNDX |
0.0 |
0.996487 |
0.001316 |
0.597753 |
Из таблиц видно, что с уменьшением исследуемого периода, возрастает количество логарифмических доходностей, которые имеют нормальное распределение.
Таблица 5
Итоговые результаты
|
6 месяцев |
3 месяца |
|
|
5 % |
0 % |
25 % |
|
1 % |
0 % |
28,57 % |
Итоговые результаты показывают, что логарифмические доходности имели нормальное распределение лишь на промежутке в 3 месяца. Также следует отметить, что это было характерно только для 2 и 4 квартала.
Заключение
В данной работе проводился анализ логарифмических доходностей акций, входящих в состав сектора информационных технологий. В ходе работы были получены следующие результаты:
На промежутке в 1 год с таймфреймом 1 день не нашлось значений, которые имеют p-значение выше 5 %. На промежутке в 6 месяцев с таймфреймом 1 день количество значений, которые имеют нормальное распределение не увеличилось.
На промежутке в 3 месяца с таймфреймом 1 день, лишь 25 процентов акций имеют нормальное распределение. При этом, нормальное распределение акций встречалось только во втором и четвертом квартале.
Можно сделать вывод, что использование критерия Шапиро — Уилка для проверки нормальности распределения не позволяет выявить закономерности для предсказания будущих цен акций.
Литература:
1. Браилов А. В. Лекции по математической статистике. М.: Финакадемия, 2007
2. В. Е. Гмурман Теория вероятностей и математическая статистика, Юрайт, 2011
3. Фадеева Л. Н. Лебедев А. В. Теория вероятностей и математическая статистика, Эксмо, 2010
4. J. P. Royston, Extension of Shapiro and Wilk's W Test for Normality to Large Samples, p. 118
5. Shapiro S. S., Wilk M. B. An analysis of variance test for normality (complete samples) Biometrika, 52 No. 3/4. (Dec., 1965), pp. 591–611
