





В данной работе рассмотрен вариант использования промежуточного программного обеспечения GridGainдля создания сети распределённой обработки данных и реализации на ней реальной математической задачи обнаружения аномалий во временном ряду.
Ключевые слова:GridGain, MapReduce, In-Memory Data Grid, распределённые вычисления, обнаружение выбросов, контекстные аномалии.
Введение
Распределённые вычисления — способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров, чаще всего объединённых в параллельную вычислительную систему [1]. Распределённые вычисления применимы также в распределённых системах управления.
Последовательные вычисления в распределённых системах выполняются с учётом одновременного решения многих задач. Особенностью распределённых многопроцессорных вычислительных систем, в отличие от локальных суперкомпьютеров, является возможность неограниченного наращивания производительности за счёт масштабирования. Слабосвязанные, гетерогенные вычислительные системы с высокой степенью распределения выделяют в отдельный класс распределённых систем — грид.
Современный уровень развития вычислительной техники и средств удалённого доступа к ней предоставляет значительные возможности при организации распределённой обработки данных, когда для осуществления трудоёмких вычислений привлекаются ресурсы нескольких обособленных высокопроизводительных компьютерных (или суперкомпьютерных) систем. Такой способ решения сложных в вычислительном плане задач имеет целый ряд преимуществ, основными среди которых являются наиболее эффективное использование включённых в распределённую вычислительную систему обобщённых вычислительных ресурсов и постоянный доступ к ним участников консорциума. Научное применение распределённых вычислений очень широко: математика (поиск простых чисел, чисел Фибоначчи), криптография (экспериментальные переборы шифров), биология/биохимия/медицина (поиск лекарств, синтез и анализ белков, исследования генома человека), естественные науки (проверка научных гипотез, моделирование климата и Земли, расчёты и поиск элементарных частиц, обработка сигналов телескопов) [2].
GridGain
GridGain это основанное на Java промежуточное программное обеспечение для обработки внутри памяти больших данных в распределённой среде. Основано на высокопроизводительных платформах данных внутри памяти, в которую интегрирована самая быстрая в мире реализации MapReduce с технологией In-Memory Data Grid, обладающей простотой в использовании и простотой в масштабировании. Используя GridGain можно обработать террабайты данных на тысячи узлов за одну секунду [3]. GridGain является бесплатной реализации MapReduce с открытым исходным кодом на языке Java.
Работа MapReduce состоит из двух шагов: Map и Reduce. На Map-шаге происходит предварительная обработка входных данных. Для этого один из компьютеров (называемый главным узлом — master node) получает входные данные задачи, разделяет их на части и передает другим компьютерам (рабочим узлам — worker node) для предварительной обработки. На Reduce-шаге происходит свёртка предварительно обработанных данных. Главный узел получает ответы от рабочих узлов и на их основе формирует результат — решение задачи, которая изначально формулировалась [4].
Задача In-Memory Data Grid — обеспечить сверхвысокую доступность данных посредством хранения их в оперативной памяти в распределённом состоянии. Современные In-Memory Data Grid способны удовлетворить большинство требований к обработке больших массивов данных [5].
Философия системы GridGain такова, что специалисту необходимо развернуть узлы на некоторых компьютерах, подключённых в сеть, и они автоматически должны найти друг друга и создать топологию. Так же специалист может сам указать на одном узле адрес другого узла в этой сети. Все что необходимо после этого, это создать задачи для этих узлов. Задачи создаются с помощью программ, написанных на JAVA или Scalar (надстройка над Scala). Цель работы данных программ заключается в указании данных и участка кода, который будет их обрабатывать на каждом узле.
Развёртывание и настройка узла
Для развёртывания GridGain в первую очередь необходимо скачать дистрибутив с официального сайта (http://www.gridgain.com/), разархивировать его в любое место на компьютере, задать переменные окружения GRIDGAIN_HOME и JAVA_HOME (пути к папке инсталляции GridGain и виртуальной машины JAVA соответственно). Далее, для проверки, нужно лишь запустить файл \bin\ggstart.bat (в случае, если используется ОС Windows). В данном случае запустится узел GridGain с настройками по умолчанию [6].
Запустив два узла на локальном компьютере или в локальной сети, они обнаружат друг друга и создадут топологию (см. рисунок 1).
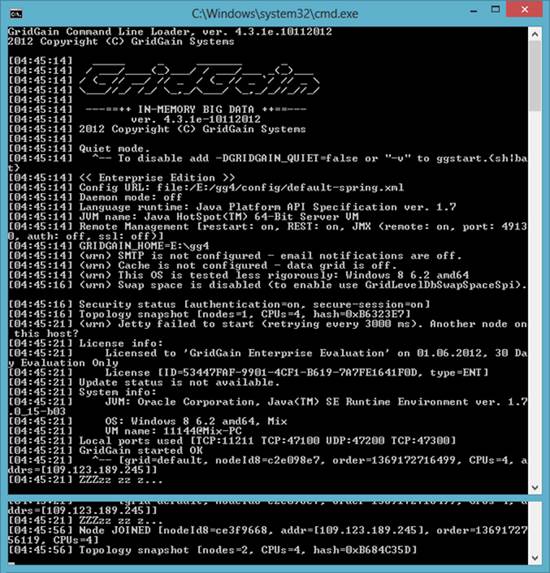
Рис. 1. Результат запуска двух узлов с настройками по умолчанию
Когда запускается GridGain со стандартной конфигурацией, запускается стандартная реализация Service provider interface (IP-multicast обнаружение и основанная на TCP/IP связь). Название сети по умолчанию, «default». Путь к GridGain определяется переменной среды GRIDGAIN_HOME. Многие другие настройки также задаются по умолчанию.
Настройка GridGain осуществляется с помощью интерфейса GridConfiguration. Эта конфигурация применима к методу GridFactory.start(GridConfiguration). Так же возможна настройка с помощью конфигурационных файлов Spring Framework, в частности, если запуск производится с помощью пакетного bat-файла. Стандартный файл настроек расположен по адресу \config\default-spring.xml.
Задача
В качестве задачи для распараллеливания была выбрана задача обнаружения выбросов и аномалий во временном ряду. Таким образом, на вход программе должны подаваться данные каких-либо измерений с течением времени. В результате своей работы, программа должна вывести список единиц входных данных, которые были признаны аномальными.
Аномалии в подобных данных относятся к контекстным аномалиям. Все нормальные экземпляры в контексте будут, в то время как аномалии будут отличаться от других экземпляров в контексте. Общий подход для данной проблемы заключается в идентификации контекста вокруг экземпляра и определении являются ли данный экземпляр аномальным, учитывая контекст. Задачу можно свести к задаче определения точечных аномалий, разбив входные данные на сегменты (по контексту) и применив к ним традиционные критерии определения аномалий [7].
Критерии определения выбросов условно можно разделить на две группы: когда гипотеза о нормальном распределении совокупности верна и когда она неверна. Для задачи поиска контекстных аномалий больше всего подходит второй вариант. В результате анализа MAD-теста и теста Граббса [8, c. 73–77] было установлено, что в общем случае аномальными признаются минимальные/максимальные значения из выборки. Таким образом, был разработан собственный алгоритм нахождения аномалий.
Суть разработанного алгоритма заключается в разделении входных данных на определённые сегменты фиксированной длины. Причём, начало каждого следующего сегмента является следующим к началу предыдущего. Таким образом, сегменты должны пересекаться.
В каждом сегменте выполняется поиск минимального и максимального значения данных. У каждых таких значений в каждом сегменте повышается вес на единицу. Далее, из всех значений аномалиями признаются те, вес которых превышает 75 % от размера сегмента.
Представленный алгоритм хорошо поддаётся распараллеливанию. Так, обработка каждого сегмента может быть распределена. Это позволит повысить скорость обработки.
Программное обеспечение
Согласно выбранной задаче и алгоритму её решения, была разработана программа на языке JAVA. Использовались библиотеки GridGain версии 4.3. Работа программы осуществляется в консольном режиме, так как задача разработки удобного и наглядного пользовательского интерфейса не стояла.
В качестве входных данных был выбран температурные показатели по городу Томску за 2012 год. Архив фактической погоды был взят из открытого источника — сайта «Расписание погоды» (http://rp5.ru/).
Разработанная программа была протестирована как на локальном компьютере, так и на сети компьютеров с запущенными узлами GridGain. Результат работы программного обеспечения приведён на рисунке 2.
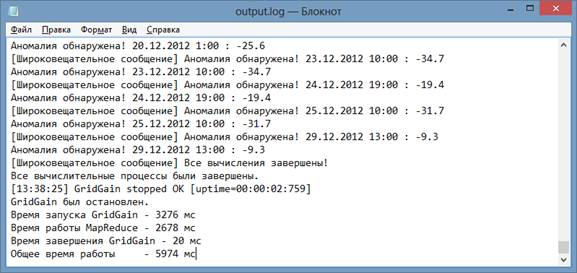
Рис. 2. Результат работы программного обеспечения
Для проведения сравнения также была разработана линейная (без распараллеливания) реализация алгоритма. Разработка велась на языке высокого уровня VB.NET в среде Visual Studio. В качестве входных использовались те же данные, что и в предыдущем примере. Результат работы программы представлен на рисунке 3.
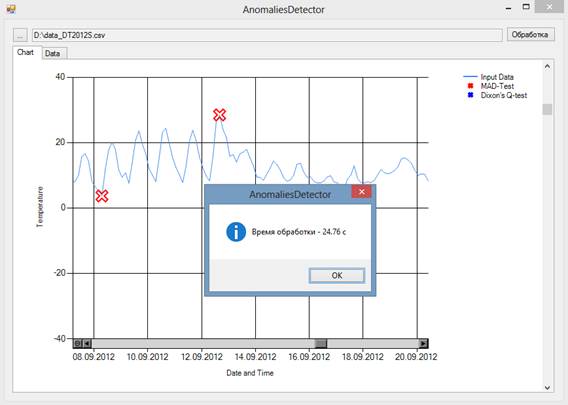
Рис. 3. Результат работы линейной реализации алгоритма
Таким образом, результаты работы двух программ наглядно демонстрируют, что алгоритм работает быстрее, когда обработка данных распределена между узлами.
Заключение
В результате проведённого исследования был проведён обзор системы GridGain и технологии MapReduce, который включает в себя рекомендации и описание установки, развёртывания и тестирования программного продукта. Так же приведена реализация распараллеливания задачи обнаружения аномалий во временном ряду погодных данных при помощи системы GridGain. Работа данной реализации была сравнена с линейной реализацией алгоритма.
Литература:
1. Распределённые вычисления [Электронный ресурс]: Википедия. — США: wikipedia.org, 2013. — Режим доступа: http://ru.wikipedia.org/wiki/Распределённые_вычисления, свободный. — Дата обращения 25.08.2013.
2. В. П. Демкин, А. В. Старченко. Распределённые вычисления: принципы и технологии // Телематика'2009. Труды XVI Всероссийской научно-методической конференции. Том 1. 2009. C. 452
3. GridGain [Электронный ресурс]: Официальный сайт GridGain. — США: gridgain.com, 2013. — Режим доступа: http://www.gridgain.com/, свободный. — Дата обращения 17.05.2013.
4. MapReduce [Электронный ресурс]: Википедия. — США: wikipedia.org, 2013. — Режим доступа: http://ru.wikipedia.org/wiki/MapReduce, свободный. — Дата обращения 25.08.2013.
5. Что такое In-Memory Data Grid [Электронный ресурс]: Хабрахабр. — Россия: habrahabr.ru, 2012. — Режим доступа: http://habrahabr.ru/post/160517/, свободный. — Дата обращения 25.08.2013.
6. Использование Scala и GridGain для разработки распределенных систем с высокой производительностью [Видеозапись, Электронный ресурс]: Интернет архив видеороликов. — Россия: video.yandex.ru, 2011. — Режим доступа: http://video.yandex.ru/users/xpinjection/view/40/, свободный. — Дата обращения 25.08.2013.
7. Data Mining for Anomaly Detection [Видеозапись, Электронный ресурс]: Интернет-ресурс видеолекций. — Россия: videolectures.net, 2008. — Режим доступа: http://videolectures.net/ecmlpkdd08_lazarevic_dmfa/, свободный. — Дата обращения 25.08.2013.
8. В. И. Дворкин «Метрология и обеспечение качества количества химического анализа». — М.: Химия, 2001. — 263 с.
