





В статье авторы исследуют особенности проектирования системы высокой доступности и устойчивых к падениям.
Ключевые слова: отказоустойчивость, микросервисы, высокая доступность.
Микросервисная архитектура постепенно вытеснила монолитный подход в сфере высокодоступных сервисов. Ещё в 2009 году компания Netflix столкнулась с проблемой недостаточной надёжности традиционной архитектуры, что побудило её перейти на микросервисы [1]. По данным за 2024 год, около 80 % веб-приложений уже используют данный подход.
Монолитные приложения представляют собой единое программное обеспечение, в котором весь код объединён в один проект. Такие приложения разрабатываются и разворачиваются как целостная система, стараясь минимизировать зависимость от внешних сервисов. Однако любое изменение в коде требует полной перекомпиляции и полного развертывания системы. Это не только замедляет процесс обновления, но и снижает доступность сервиса, поскольку время компиляции даже на современных процессорах может превышать десять минут.
Монолитная архитектура обычно выбирается на ранних стадиях разработки проекта, поскольку её реализация проще и не требует от команды высокой квалификации. Это позволяет быстрее запустить продукт, но в дальнейшем может создать серьёзные ограничения по масштабируемости и отказоустойчивости. Микросервисная же архитектура рассматривает систему как совокупность независимых компонентов — сервисов, каждый из которых отвечает за определённую бизнес-логику и часто использует собственную базу данных. Каждый сервис разрабатывается, компилируется, тестируется и развёртывается автономно, не влияя на остальные. Несмотря на очевидные преимущества, микросервисы не снижают общую сложность системы, но делают её более гибкой и управляемой.
Такой подход позволяет внедрять техники непрерывной интеграции и развёртывания, а также формировать кросс-функциональные команды, работающие с инфраструктурой. Это способствует достижению высокой доступности, хотя данные аспекты будут рассмотрены в данной работе лишь поверхностно. Очевидно, что для обеспечения высокой доступности системы использование микросервисов является одним из ключевых факторов.
При этом микросервисы не являются универсальным решением всех проблем, а в некоторых ситуациях могут даже создать дополнительные сложности. Необходимо находить компромиссы, но каждый из них будет подкреплён следующими преимуществами [2]:
- Гибкость: Подход хорошо сочетается с итеративными методологиями разработки, такими как Agile.
- Масштабируемость: При достижении сервисом пиковых нагрузок возможно автоматическое развертывание дополнительных экземпляров, для распределения нагрузки.
- Поддержка и тестируемость: Легче экспериментировать и вносить изменения в отдельные сервисы без риска для всей системы.
- Независимые развёртывания: Возможность поддерживать несколько версий приложения одновременно.
- Технологическая независимость: Сервисы могут быть переписаны на другом языке программирования в сжатые сроки.
- Высокая надёжность: Размножение экземпляров сервисов повышает доступность системы, так как выход из строя одного сервиса не критичен для всей системы.
Микросервисная архитектура, несмотря на свои преимущества, также обладает рядом недостатков. Внедрение микросервисов может усложнить проект из-за трудностей при разделении функций и возможного увеличения связности между компонентами. Основные сложности микросервисного подхода включают:
- Сложность разработки: По мере роста проекта количество сервисов и связей между ними увеличивается экспоненциально, усложняя управление системой.
- Затраты на инфраструктуру: Каждый новый сервис требует собственной инфраструктуры, что увеличивает расходы на обслуживание.
- Организационные издержки: С ростом количества сервисов возрастает количество команд, что усложняет коммуникацию и координацию между ними.
- Сложности отладки: Локальные журналы с временными метками в каждом сервисе могут вызывать коллизии и затруднять анализ проблем.
Таким образом, хотя микросервисы и являются эффективным решением при создании отказоустойчивых систем, необходимо тщательно подходить к выбору этой архитектуры, чтобы избежать излишней сложности и дополнительных рисков.
Развитие компьютерных сетей и появление облачных вычислений способствовали популяризации сервисов. Сегодня они используются повсеместно, и для поддержания высокого уровня обслуживания заключаются соглашения о минимальной доступности. Это требует применения методов предотвращения и восстановления после сбоев.
С ростом облачных технологий актуальными стали такие понятия, как высокая доступность и масштабируемость. Под облаком понимается совокупность вычислительных ресурсов, доступных через Интернет, что позволяет различным пользователям получать доступ к сервисам онлайн [3]. Услуги облачных провайдеров обычно предоставляются по моделям:
- IaaS (Infrastructure as a Service) — инфраструктура как услуга, предоставляет виртуальные машины, сети и хранилища.
- PaaS (Platform as a Service) — платформа как услуга, позволяет разрабатывать и развертывать приложения на готовой инфраструктуре.
- SaaS (Software as a Service) — программное обеспечение как услуга, предоставляет готовые приложения через Интернет.
Независимо от выбранной модели, клиенты ожидают доступности сервисов в любое удобное для них время. Здесь ключевыми факторами становятся высокая доступность и масштабируемость.
Высокая доступность направлена на минимизацию времени простоя системы. Она измеряется как процент времени, в течение которого сервис способен отвечать на запросы в течение года. Чем выше этот показатель, тем меньше вероятность сбоев и недоступности услуг для пользователей.
![Перевод доступности в количество возможного времени простоя [4]](https://moluch.ru/blmcbn/123207/img_123207_1.webp)
Рис. 1. Перевод доступности в количество возможного времени простоя [4]
Системы классом больше шести девяток очень сложны и дороги в реализации и рассматриваются в отдельных случаях.
Чтобы рассчитать класс системы можно использовать формулу (1).

где InoperativeTime — время простоя,
ElapsedTime определяется формулой (2).

Хотя может показаться, что увеличение количества «девяток» в показателе доступности системы всегда является улучшением, каждая дополнительная «девятка» влечёт за собой усложнение архитектуры и увеличение финансовых затрат [5, c. 220]. Поэтому оптимальный уровень доступности стоит выбирать, исходя из соглашений с клиентами и их требований.
Для высокодоступных систем особенно важны следующие метрики:
Процент доступности: Например, доступность 99.99 % означает, что система может быть недоступна не более 52 минут в год.
Время безотказной работы (MTBF): Среднее время между отказами системы. Чем выше этот показатель, тем реже происходят сбои.
Время восстановления (MTTR): Среднее время, необходимое для восстановления работоспособности после сбоя. Чем меньше MTTR, тем выше общая доступность.
Задержка времени ответа: Важно, чтобы 99-й перцентиль (P99) времени ответа не превышал 100 миллисекунд. Это гарантирует, что большинство запросов обрабатывается быстро, даже при высокой нагрузке.
Доступность системы обычно достигается за счёт использования реплицируемых компонентов, которые работают вместе как единое целое (концепция «чёрного ящика»). Эти компоненты образуют так называемые кластеры высокой доступности.
Кластеры распределяют ресурсы между своими узлами, такими как базы данных и конфигурации. В случае сбоя или при плановом обслуживании система синхронизирует данные между копиями, позволяя им быстро возобновлять обслуживание пользователей (см. рисунок 2).
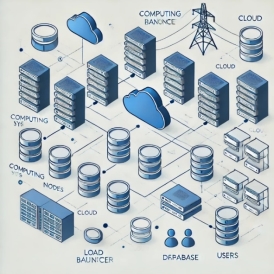
Рис. 2. Упрощённая архитектура высокой доступности
Иногда резервные копии служб могут находиться в режиме ожидания и активироваться только при недоступности основных систем. В таком случае время простоя системы определяется промежутком между возникновением сбоя и началом работы резервной копии.
Для достижения высокой доступности веб-сервисов необходимо применять различные подходы, направленные на минимизацию простоев, повышение устойчивости к сбоям и обеспечение бесперебойной работы при высоких нагрузках. Одна из ключевых задач высокой доступности — обеспечение отказоустойчивости, то есть гарантия того, что система продолжит работать, несмотря на различные сбои, такие как выход из строя оборудования, программные ошибки или проблемы с сетью.
Разработка отказоустойчивых систем требует учёта архитектурных, инфраструктурных и операционных особенностей, которые способствуют быстрому восстановлению после сбоев и их предотвращению. Основные принципы построения таких систем включают [5]:
- Устранение единичных точек отказа: Единичные точки отказа — это компоненты, отказ которых может остановить всю систему. Для повышения доступности необходимо выявлять такие уязвимости и устранять их, создавая избыточность и повышая отказоустойчивость на каждом уровне архитектуры.
- Репликация данных и сервисов: Дублирование критически важных компонентов и данных помогает системе продолжать функционировать даже при отказе одного из элементов. Множественные экземпляры сервисов и баз данных обеспечивают стабильность работы.
- Балансировка нагрузки и управление трафиком: Эффективное распределение входящих запросов между доступными ресурсами предотвращает их перегрузку, что положительно сказывается на производительности и доступности системы.
- Автоматизация восстановления: Внедрение автоматических механизмов аварийного переключения и восстановления позволяет быстро реагировать на сбои и переключаться на резервные ресурсы без участия человека. Это минимизирует время простоя и ускоряет восстановление системы.
- Активный мониторинг и оповещение: Системы мониторинга позволяют своевременно обнаруживать сбои и проблемы в работе сервисов. Оперативные уведомления помогают быстро реагировать на инциденты, снижая их влияние на пользователей.
- Планирование и тестирование сценариев отказов: Регулярное тестирование различных сценариев сбоев помогает убедиться, что система способна справляться с критическими ситуациями. В этом помогут такие методы, как тестирование производительности, хаос-инжиниринг и проверка отказоустойчивости.
Таким образом, создание высокодоступных веб-сервисов требует комплексного подхода и постоянного совершенствования системы. Компании, которые стремятся к высоким показателям доступности, должны учитывать не только технические аспекты, но и финансовую целесообразность.
Применение описанных методик и соблюдение рассмотренных принципов позволяют создавать системы, способные обеспечивать стабильную и бесперебойную работу даже в условиях высокой нагрузки и неожиданных сбоев.
Литература:
- Джош Эванс / Руководство Netflix для микросервисов. — Текст: электронный // Хабр: [сайт]. — URL: https://habr.com/ru/companies/ua-hosting/articles/507526/ (дата обращения: 03.03.2025).
- Микросервисы. Как правильно делать и когда применять? — Текст: электронный // Хабр: [сайт]. — URL: https://habr.com/ru/companies/dataart/articles/280083/ (дата обращения 03.03.2024).
- Таненбаум, А. С. Распределённые системы / А. С. Таненбаум, С. М. Ван. — 3-е изд. — Москва: Питер, 2016. — 584 c. — Текст: непосредственный.
- М. Тамер Ёсу., Принципы организации распределённых баз данных. Пер. с англ. -М: ДМК Пресс, 2021–672 с.
- The Art of Scalability: Scalable Web Architecture, Processes, and Organizations for the Modern Enterprise. / Кохлинг 4, К. Бертон, В. Вудсон, С. Васселл. — 1-е изд. — Sebastopol O'Reilly Media, 2010. — 465 c. — Текст: непосредственный.
