





Введение. Впрактических задачах часто возникает необходимость решения систем линейных алгебраических уравнений (СЛАУ) с симметричной, положительно определенной матрицей. Такие матрицы возникают, например, при дискретизации эллиптических уравнений математической физики и порождают линейные системы большой или очень большой размерности. В связи с этим при реализации алгоритмов решения СЛАУ на однопроцессорном компьютере могут возникнуть трудности из-за нехватки памяти, либо решение займет много времени. В этом случае необходимо использовать нестандартные подходы к написанию алгоритмов, основанные на использовании технологии параллельного программирования. Одним из методов решения СЛАУ является сведение исходной задачи к задаче безусловной минимизации квадратичной функции.
Целью данной работы является разработка параллельного алгоритма метода сопряженных градиентов для решения минимизации квадратичной функции. Для реализации поставленной цели была выбрана технология NVIDIA CUDA, как наиболее эффективное вычислительное средство, имеющая ряд преимуществ: доступность, легкость в изучении, поддержка практически любой современной видеокартой NVIDIA, наибольшая производительность.
Постановка задачи. Рассмотрим систему линейных уравнений (1) с симметричной, положительно определенной матрицей 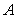 размера
размера 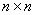 :
:
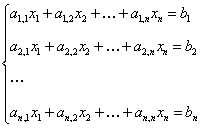 (1)
(1)
Основой метода сопряженных градиентов является следующее свойство [1]: решение системы линейных уравнений (1) с симметричной положительно определенной матрицей эквивалентно решению задачи минимизации функции:
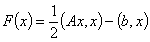 (2)
(2)
в пространстве 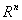 . В самом деле, функция
. В самом деле, функция 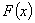 достигает своего минимального значения тогда и только тогда, когда ее градиент равен нулю:
достигает своего минимального значения тогда и только тогда, когда ее градиент равен нулю:
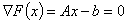 .
.
Таким образом, решение системы (1) можно искать как решение задачи безусловной минимизации функции (2).
Описание алгоритма метода сопряженных градиентов. Метод сопряженных градиентов для решения минимизации квадратичной функции (2) заключается в следующем [1]. На предварительном шаге задается начальное приближение 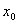 , вычисляются начальный вектор невязки
, вычисляются начальный вектор невязки 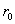 и вектор направления
и вектор направления  :
:
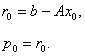
Дальнейшие приближения  определяются следующими формулами:
определяются следующими формулами:
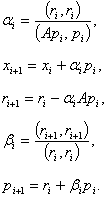
Здесь 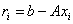 — невязка
— невязка 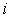 -го приближения, коэффициент
-го приближения, коэффициент 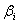 соответствует выполнению условия сопряженности
соответствует выполнению условия сопряженности 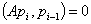 направлений
направлений 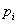 и
и 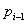 .
.
С этой точки зрения коэффициент 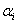 является решением задачи минимизации функции
является решением задачи минимизации функции 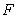 по направлению :
по направлению :
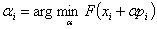 .
.
Для нахождения точного решения системы линейных уравнений с положительно определенной симметричной матрицей необходимо выполнить не более 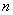 итераций. Однако, учитывая ошибки округления, данный процесс обычно рассматривают как итерационный. Вычисления завершаются при выполнении условия остановки:
итераций. Однако, учитывая ошибки округления, данный процесс обычно рассматривают как итерационный. Вычисления завершаются при выполнении условия остановки:
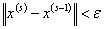 ,
,
где 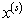 — приближение, полученное на итерации с номером
— приближение, полученное на итерации с номером 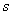 ,
, 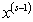 — приближение, полученное на предыдущей итерации. Параметр точности метода
— приближение, полученное на предыдущей итерации. Параметр точности метода 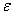 задает исследователь. Также используется остановка при выполнении условия малости относительной нормы невязки:
задает исследователь. Также используется остановка при выполнении условия малости относительной нормы невязки:
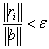 . (3)
. (3)
Метод сопряженных градиентов с применением технологии CUDA. В методе сопряженных градиентов наиболее целесообразный подход для распараллеливания состоит в распараллеливании вычислений, реализуемых в ходе выполнения итераций.
Проведя анализ последовательного алгоритма метода сопряженных градиентов (рис. 1), можно заключить, что основные вычислительные затраты приходятся на умножение матрицы 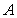 на вектора
на вектора 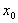 и
и 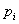 (MultMatVec — 96,33 %). Поэтому для повышения эффективности работы метода достаточно распараллелить данную операцию. При реализации параллельных вычислений был использован параллельный алгоритм умножения матрицы на вектор, предложенный в учебном пособии [2, с. 78–81].
(MultMatVec — 96,33 %). Поэтому для повышения эффективности работы метода достаточно распараллелить данную операцию. При реализации параллельных вычислений был использован параллельный алгоритм умножения матрицы на вектор, предложенный в учебном пособии [2, с. 78–81].
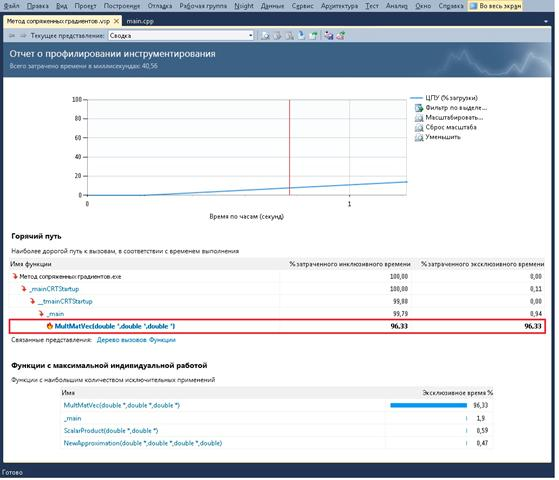
Рис. 1. Анализ производительности алгоритма метода сопряженных градиентов
Также в алгоритме присутствуютразличные операции над векторами, такие как: скалярное произведение, сложение и вычитание, умножение вектора на число. В распараллеливании данных вычислений нет необходимости, поскольку время, приходящее на обработку векторов незначительно, что следует из анализа (см. рис. 1).
Тестирование и анализ эффективности алгоритма. Для сравнения последовательной и параллельной реализаций алгоритма метода сопряженных градиентов была проведена серия экспериментов. Тестирование параллельного алгоритма проводилось на вычислительном кластере с центральным процессором Intel Xeon, 48Гб ОЗУ, с 3 графическими сопроцессорами NVIDIA TESLA C2075, а так же графическим процессором NVIDIA Quadro 2000.
Для проверки корректности реализованных алгоритмов использованы СЛАУ с известными точными решениями. Матрица генерировалась следующим образом:
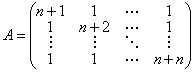 ,
,
где — размерность матрицы. В качестве вектора свободных членов 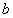 был взят вектор, полученный в результате перемножения матрицы на вектор
был взят вектор, полученный в результате перемножения матрицы на вектор 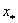 , где — точное решение СЛАУ (1). Вектор решения заполняется случайными числами от
, где — точное решение СЛАУ (1). Вектор решения заполняется случайными числами от 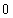 до . В качестве критерия останова взято условие завершения (3), точность метода
до . В качестве критерия останова взято условие завершения (3), точность метода 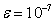 .
.
Эффективность параллельных вычислений оценивается с помощью ускорения:
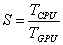 ,
,
где 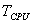 — время решения задачи на однопроцессорном компьютере,
— время решения задачи на однопроцессорном компьютере, 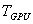 — аналогичное время при решении с использованием параллельного программирования. Подчеркнем, что под ускорением
— аналогичное время при решении с использованием параллельного программирования. Подчеркнем, что под ускорением 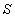 в данном случае понимается повышение производительности вычислений при использовании графического процессора относительно производительности вычислений, производимых на однопроцессорном компьютере.
в данном случае понимается повышение производительности вычислений при использовании графического процессора относительно производительности вычислений, производимых на однопроцессорном компьютере.
В таблице 1 приведено время работы алгоритмов и полученное ускорение в зависимости от размера матриц. Следует отметить, что время работы алгоритма на графическом процессоре включает время, затрачиваемое на выделение памяти и копирование данных.
Таблица 1
Сравнительный анализ параллельного и последовательного алгоритмов
|
Размерность, |
|
|
Ускорение, |
|
200 |
0,044 |
0,193 |
0,23 |
|
500 |
0,415 |
0,484 |
0,86 |
|
1000 |
1,206 |
0,671 |
1,80 |
|
1500 |
3,236 |
0,953 |
3,40 |
|
2000 |
6,384 |
1,117 |
5,72 |
|
3000 |
20,993 |
3,125 |
6,72 |
|
4000 |
55,56 |
6,231 |
8,92 |
|
5000 |
107,923 |
10,962 |
9,85 |
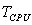 , сек.
, сек.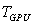 ,сек.
,сек.Для иллюстрации приведенных данных в таблице 1 на рисунке 2 приведен график зависимости времени работы алгоритма на однопроцессорном компьютере и с применением технологии CUDA от размерности , на рисунке 3 представлен график ускорения алгоритма от размерности .
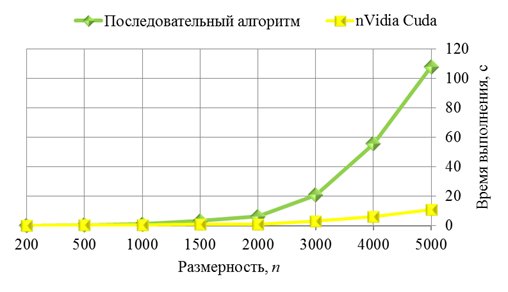
Рис. 2. Время работы последовательного и параллельного алгоритмов метода сопряженных градиентов
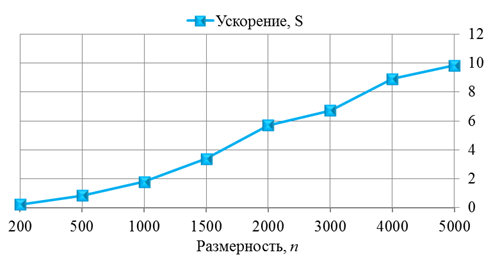
Рис. 3. Ускорение алгоритма метода сопряженных градиентов
На графике, изображенном на рис. 3, видно, что при небольшой размерности (до 500) ускорение меньше единицы, то есть параллельный алгоритм работает медленнее, чем последовательный. Это связано с затратами времени на выделение памяти на графическом процессоре и последующим копированием в нее исходных данных.
На больших же размерах матрицы алгоритм эффективен, так как ускорение больше единицы. Из графика (рис. 3) видно, что ускорение увеличивается с ростом числа .
Сравнительный анализ времени параллельного и последовательного алгоритмов метода сопряженных градиентов, показал, что применение технологии CUDA сокращает время решения задачи (до 10 раз). Однако следует отметить, что не имеет смысла использовать CUDA для работы с небольшими объемами данных. Для малых объемов входных данных ускорения практически не наблюдалось.
Литература:
1. Баркалов К. А. Методы параллельных вычислений. Н. Новгород: Изд-во Нижегородского госуниверситета им. Н. И. Лобачевского, 2011–124 с.
2. Варыгина М. П. Основы программирования в CUDA. Учебное пособие. Красноярск: Краснояр. гос. пед. ун-т им. В. П. Астафьева, 2012–138 с.
3. Сандерс Д., Кэндрот Э. Технология CUDA в примерах: введение в программирование графических процессоров. / под ред. ДМК Пресс. Пер. с англ., 2011. — 232 с.
