





В статье разобрано математическое содержание метода Вагнера — Фишера.
Ключевые слова:нечеткий поиск, математическая логика.
Логика — это фундаментальная основа информатики как науки. Элементы и основы математической логики заложены в логические элементы и логические устройства ЭВМ, в основы алгоритмизации и языки программирования, в процедуры поиска информации в базах данных и в сети Интернет, а также в системах логического программирования, базах знаний и экспертных системах на ЭВМ.
Математическая логика, возникшая почти 100 лет назад в связи с внутренними потребностями математики, нашла применение в теоретическом (и практическом) программировании. Математическая логика занимается построением формальных языков, предназначенных для представления таких фундаментальных понятий, как функция, отношение, аксиома, доказательство, и изучением основанных на этих языках логических и логико-математических исчислений. Именно в недрах математической логики были найдены математически точные понятия алгоритма и вычислимой функции, развита семантика формальных языков и теорий, построены системы логического вывода — и все это, заметим, было сделано в 30–40-х годах, т. е. еще в «докомпьютерную эру». Программирование также имеет дело с формальными языками — языками программирования, являющимися средствами общения человека и компьютера. В своем стремлении сделать эти средства удобными и естественными для человека вычислительная наука не могла пройти мимо тех языков описания, которые были созданы в рамках математической логики с учетом многовекового математического опыта. С другой стороны, языки высокого уровня нуждаются в детально проработанной семантике, которая выходит на первый план при написании трансляторов. И здесь идеи и аппарат математической логики, уже занимавшейся проблемами семантики, оказались весьма кстати. Поначалу для формализации смысла программ использовалось известное логикам еще с 30-х годов бестиповое лямбда-исчисление А. Чёрча, а затем абстрактным базисом денотационной семантики стала мощная и элегантная теория областей, развитая Д. Скоттом. Важное значение приобретает теория логического вывода, причем не только в задачах искусственного интеллекта, но и как средство рассуждения о программах и доказательства их свойств (скажем, правильности относительно спецификации) или, наоборот, как метод построения правильных программ (например, путем их извлечения из конструктивных доказательств) [1].
Наиболее часто встречающимся в программировании действием является поиск. Методы поиска могут быть классифицированы различными способами. В большинстве случаев под поиском понимают задачу выборки, в которой требуется найти элемент, удовлетворяющий некоторым условиям [2]. Однако возникают ситуации, когда поиск представляет собой нахождение объектов, похожих, в определенном смысле, на заданный объект. В таких случаях принято говорить об использовании алгоритмов нечеткого поиска [3]. Алгоритмы нечеткого поиска являются основой систем проверки орфографии полноценных поисковых систем вроде Google или Yandex.
Существуют различные подходы к реализации нечеткого поиска в реляционных базах данных. Одним из подходов является использование нечеткого текстового поиска: искомый объект и запись таблицы базы данных преобразуются в строки путем слияния атрибутов, затем с помощью алгоритмов нечеткого поиска строк вычисляется степень их схожести [3]. Алгоритмы нечеткого поиска характеризуются метрикой — функцией расстояния между двумя словами, позволяющей оценить степень их сходства в данном контексте. В данном подходе под поиском по сходству подразумевается отыскание всех слов, для которых метрика до поискового шаблона не превышает заданную величину.
ОПР.1 [4]. Пусть Х произвольное непустое множество. Говорят, что на Х задана метрика (расстояние), если для каждой пары элементов x,y∈X поставлено в соответствие единственное неотрицательное число ρ(х,у), удовлетворяющее следующим трем условиям:
1. ρ(х,у)=0 тогда и только тогда, когда х=у (аксиома тождества);
2. ρ(х,у)= ρ(у,х) для ∀х,у∈X (аксиома симметрии);
3. ρ(х,у)+ ρ(у,z)≥ ρ(х,z) ∀х,у,z∈X (аксиома треугольника).
Строгое математическое определение метрики включает в себя необходимость соответствия условию неравенства треугольника. Между тем, в программировании под метрикой подразумевается более общее понятие, не требующее выполнения такого условия.
Таким образом, задачу нечеткого поиска можно сформулировать так: «По заданному слову найти в тексте или словаре размера n все слова, совпадающие с этим словом (или начинающиеся с этого слова) с учетом k возможных различий».
Нечеткий поиск является крайне полезной функцией любой поисковой системы. Вместе с тем, его эффективная реализация намного сложнее, чем реализация простого поиска по точному совпадению [5].
В числе наиболее известных метрик — расстояния Хемминга, Левенштейна и Дамерау-Левенштейна.
ОПР.2. Расстояние Хэмминга — число позиций, в которых соответствующие символы двух слов одинаковой длины различны [6].
В более общем случае расстояние Хэмминга применяется для строк одинаковой длины любых q-ичных алфавитов и служит метрикой различия объектов одинаковой размерности. Т. е., расстояние Хемминга является метрикой только на множестве слов одинаковой длины, что сильно ограничивает область его применения.
Наиболее популярная из существующих метрик — это функция Левенштейна–Дамерау.
ОПР.3. Расстояние Левенштейна равно минимальному числу элементарных операций редактирования, необходимых для преобразования одной строки в другую, в том числе операции замены, вставки и удаления одного символа [7]. В модификации расстояния редактирования, предложенной Дамерау, в множество элементарных операций включены транспозиции символов.
На базе метрики Левенштейна — Дамерау построено большое число поисковых алгоритмов, в т. ч.: сигнатурные алгоритмы, алгоритмы n-граммной индексации, строковые trie-деревья, алгоритмы расширения выборки и последовательного перебора [8].
Введем следующие обозначения.
Строка x длины |x| = m записывается как x1x2... xm, где xi представляет i-й символ x.
Подстрока xixi+1... xj строки x, где i ≤ j ≤ m, будет обозначаться x(i,j).
Цену преобразования символа a в символ b обозначим через w(a,b). Таким образом, w(a,b) — это цена замены одного символа на другой, когда a ≠ b, w(a,ε) — цена удаления a, а w(ε, b) — цена вставки b.
Используя введенные обозначения, можно переформулировать определение расстояния Левенштейна:
ОПР. 4. Расстояние d является расстоянием Левенштейна, когда выполнены следующие условия:
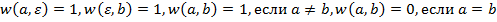
Рассмотрим наиболее популярный алгоритм расчет — метод Вагнера — Фишера.
В методе динамического программирования последовательно, по предыдущим значениям, вычисляются расстояния между все более и более длинными префиксами (начало строки) двух строк до получения окончательного результата (т. е. используются рекуррентные соотношения). Опишем этот процесс более подробно.
Пусть di,j есть расстояние между префиксами строк x и y, длины которых равны, соответственно, i и j, то есть
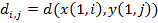
Теорема 1. Расстояние между префиксами строк x и y, длины которых равны, соответственно, i и j вычисляются с помощью следующего рекуррентного соотношения:
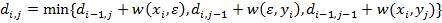
Доказательство: Предположим, что известна цена преобразования x(1, i-1) в y(1, j), тогда цену преобразования x(1, i) в y(1,j) получим, добавив к ней цену удаления xi. Аналогично, цену преобразования x(1, i) в y(1, j) можно получить, прибавив цену вставки yj к цене преобразования x(1, i) в y(1, j-1). Наконец, зная цену преобразования x(1, i-1) в y(1, j-1), цену преобразования x(1, i) в y(1, j) получим, прибавив к ней цену замены xi на yj. Из определения di,j среди трех получившихся значений выбираем минимальное.
Процесс вычислений значений di,j удобно записывать с помощью матрицы размерности (m+1) × (n+1). Перед тем, как начать вычислять di,j, надо установить граничные значения т и п. Что касается первого столбца матрицы, то значение di,0 равно сумме цен удаления первых i символов x. Аналогично, значения d0,j первой строки задаются суммой цен вставки первых j символов y. Итак, имеем формулы (1):
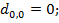
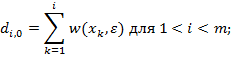
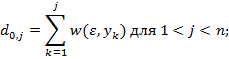
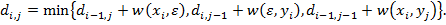
Для расстояния Левенштейна формулы (1) примут вид (2)
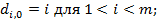
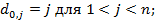
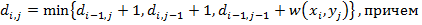
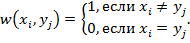
Замечание. Процесс вычислений удобно выполнять в таблице, в которой к искомой матрице добавляем две строки (номер i, само слово) и, аналогично два столбца.
Последовательность операций редактирования для преобразования x в y можно получить с помощью теории графов. След из x в y можно описать как соединение символов строки x с символами помещенной под ней строки y ребрами, причем каждый из символов соприкасается не больше чем с одним ребром, и никакие два ребра не пересекаются. Представляя ребро из xi в yj как упорядоченной парой целых чисел (i, j), след из x в y можно формально определить как множество упорядоченных пар, удовлетворяющих следующим условиям: 1 < i < m, 1 < j < n; для разных ребер (i1, j1), (i2, j2) i1 ≠ i2 и j1 ≠ j2, i1 < i2<=> j1 < j2.
Последовательность операций редактирования можно получить из следа следующим образом. Все не касающиеся ребер символы x надо удалить, а аналогичные символы y вставить. Для каждого ребра (i, j) в следе, xi заменить на yj, если xi ≠ yj, если же xi = yj, то редактирование не требуется.
Пример. Вычислить расстояние Левенштейна между строками «логика» и «ложка». Записать последовательность операций редактирования.
Решение.
|
j |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
|
|
i |
л |
о |
г |
и |
к |
а |
||
|
0 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
|
|
1 |
л |
1 |
0 |
1 |
2 |
3 |
4 |
5 |
|
2 |
о |
2 |
1 |
0 |
1 |
2 |
3 |
4 |
|
3 |
ж |
3 |
2 |
1 |
1 |
2 |
3 |
4 |
|
4 |
к |
4 |
3 |
2 |
2 |
2 |
2 |
3 |
|
5 |
а |
5 |
4 |
3 |
3 |
3 |
3 |
2 |
1. Заполняем первую строку и первый столбец.
2. Найдем элемент матрицы 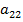 . В этом случае
. В этом случае 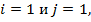
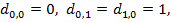
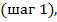
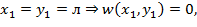 получаем
получаем
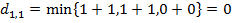 .
.
3. Найдем элемент матрицы 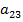 . В этом случае
. В этом случае 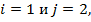
4. 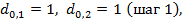
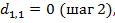
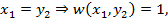 получаем
получаем
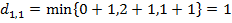 .
.
5. Аналогично вычисляем все оставшиеся элементы матрицы.
6. Получаем, что расстояние Левенштейна есть 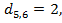 т. е. минимальное число элементарных операций редактирования, необходимых для преобразования строки «логика» в строку «ложка» равно двум.
т. е. минимальное число элементарных операций редактирования, необходимых для преобразования строки «логика» в строку «ложка» равно двум.
Запишем последовательность операций редактирования.
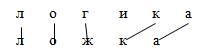
Из матрицы и графа видно, что символы 1-«л», 2-«о», 5-«к», 6-«а» — остаются; символ 3-«г» меняется на «ж» (первая операция); символ 4-«и» удаляется (вторая операция).
В статье излагается метод вычисления редакционного расстояния при использовании небольшого объема памяти, без существенной потери скорости. Данный подход может быть применен для больших строк (порядка 105 символов, т. е. фактически для текстов) при получении не только оценки «схожести», но и последовательности изменений для перевода одной строки в другую. Возможно, использование математического аппарата позволит улучшить данный метод и расширить область его применения.
Литература:
1. Математическая логика в программировании: Сб. статей 1980–1988 гг.: Пер. с англ.—М.: Мир, 1991.—408 с.
2. Макконнелл Дж. Основы современных алгоритмов. — М.: Техносфера, 2004.
3. Сонькин М. А., Лещик Ю. В. Применение алгоритмов нечеткого поиска в системах мониторинга лесопожарной обстановки // Известия Томского политехнического университета. — 2012. — № 5, Т. 321. — С. 98–101.
4. Колмогоров, А. Н. Элементы теории функций и функционального анализа/ А. Н. Колмогоров, С. В. Фомин. — М.: Наука, 1981.
5. http://habrahabr.ru/post/114997/ (дата обращения: 18.04.2014).
6. M. Minsky and S. Papert. Perceptrons. MIT Press, Cambridge, MA, 1969.
7. В. И. Левенштейн. Двоичные коды с исправлением выпадений, вставок и замещений символов // Доклады Академий Наук СССР. — 1965. — C. 845–848.
8. Бойцов Л. М. Классификация и экспериментальное исследование современных алгоритмов нечеткого словарного поиска [текст] // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: RCDL2004: тр. 6-й Всеросс. науч. конф. URL: http://www.rcdl.ru/papers/2004/paper27. pdf (дата обращения: 24.04.2014).
