





Ключевые слова: обнаружение лиц, компьютерное зрение
Задача обнаружения лица на изображении часто является первым шагом в процессе решения задачи более высокого уровня — распознавания лица, деталей лица или его мимики. Кроме того, информация о присутствии и количестве лиц на изображении может быть полезна в системах автоматического учета числа посетителей; системах пропускного контроля в учреждениях, аэропортах и метро; автоматических системах предотвращения несчастных случаев; интеллектуальных интерфейсах «человек-компьютер»; в фототехнике для автоматической фокусировки на лице человека, а также для стабилизации изображения лица с целью облегчения распознавания эмоций; для расширения зоны стереовидения при создании систем 3D отображения.
Существующие алгоритмы обнаружения лиц можно разбить на четыре категории:
- эмпирический метод;
- метод характерных инвариантных признаков;
- распознавание с помощью шаблонов, заданных разработчиком;
- метод обнаружения по внешним признакам, обучающиеся системы.
Эмпирический подход «базирующийся на знаниях сверху-вниз» (knowledge based top-down methods) предполагает создание алгоритма, реализующего набор правил, которым должен отвечать фрагмент изображения, для того чтобы быть признанным человеческим лицом. Этот набор правил является попыткой формализовать эмпирические знания о том, как именно выглядит лицо на изображениях и чем руководствуется человек при принятии решения: лицо он видит или нет. Самые простые правила:
- центральная часть лица имеет однородную яркость и цвет;
- разница в яркости между центральной частью и верхней частью лица значительна;
- лицо содержит в себе два симметрично расположенных глаза, нос и рот, резко отличающиеся по яркости относительно остальной части лица.
Метод сильного уменьшения изображения [1] для сглаживания помех, а также для уменьшения вычислительных операций предварительно подвергает изображение сильному уменьшению (Рис.1). На таком изображении проще выявить зону равномерного распределения яркости (предполагаемая зона нахождения лица), а затем проверить наличие резко отличающихся по яркости областей внутри: именно такие области можно с разной долей вероятности отнести к «лицу».

Рис. 1. Метод Yang & Huang
Метод построения гистограмм [2] для определения областей изображения с «лицом» строит вертикальную и горизонтальную гистограммы (Рис. 2). В областях-кандидатах происходит поиск черт лица (1).
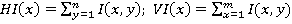 (1)
(1)
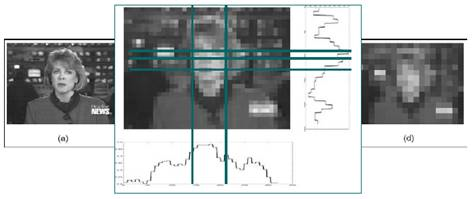
Рис. 2. Метод Kotropoulos & Pitas
Данный подход использовался на заре развития компьютерного зрения ввиду малых требований к вычислительной мощности процессора для обработки изображения. Рассмотренные выше методы имеют неплохие показатели по выявлению лица на изображении при однородном фоне, они легко реализуемы с помощью машинного кода. Впоследствии было разработано множество подобных алгоритмов. Но эти методы абсолютно непригодны для обработки изображений, содержащих большое количество лиц или сложный задний фон. Также они очень чувствительны к наклону и повороту головы.
Методы характерных инвариантных признаков, базирующиеся на знаниях снизу-вверх (Feature invariant approaches) образуют второе семейство способов детекирования лиц. Здесь виден подход к проблеме с другой стороны: нет попытки в явном виде формализовать процессы, происходящие в человеческом мозге. Сторонники подхода стараются выявить закономерности и свойства изображения лица неявно, найти инвариантные особенности лица, независимо от угла наклона и положения.
Основные этапы алгоритмов этой группы методов:
- детектирование на изображении явных признаков лица: глаз, носа, рта;
- обнаружение: границы лица, форма, яркость, текстура, цвет;
- объединение всех найденных инвариантных признаков и их верификация.
Метод обнаружения лиц в сложных сценах [3] предполагает поиск правильных геометрических расположений черт лица. Для этого применяется гауссовский производный фильтр с множеством различных масштабов и ориентаций. После этого производится поиск соответствия выявленных черт и их взаимного расположения случайным перебором (Рис.3а).
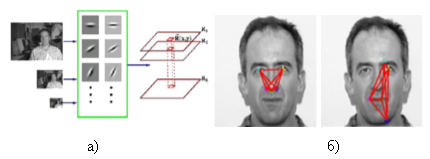
Рис. 3. а) Мультимасштабная разноориентированная фильтрация, б) Верные и случайные срабатывания
Суть метода группировки признаков [4] в применении второй производной гауссовского фильтра для поиска интересующих областей изображения (Рис. 4а). Далее группируются края вокруг каждой такой области при помощи порогового фильтра.
Рис. 4 а) Модель лица и его черт; б) Парные границы черт лица; в) Выделение области черты лица
А затем используется оценка при помощи байесовской сети для комбинирования найденных признаков, таким образом происходит выборка черт лица.
Методы этой группы в качестве достоинств имеют возможность распознавать лицо в различных положениях. Но даже при небольшом загромождении лица другими объектами, возникновении шумов или засветке процент достоверного распознавания сильно падает. Большое влияние также оказывает сложный задний фон изображения. Основа рассмотренных подходов — эмпирика, является одновременно их сильной и слабой стороной. Большая изменчивость объекта распознавания, зависимость вида лица на изображении от условий съемки и освещения позволяют без колебаний отнести обнаружение лица на изображении к задачам высокой сложности. Применение эмпирических правил позволяет построить некоторую модель изображения лица и свести задачу к выполнению некоторого количества относительно простых проверок. Однако, несмотря на безусловно разумную посылку — попытаться использовать и повторить уже успешно функционирующий инструмент распознавания — человеческое зрение, методы первой категории пока далеки по эффективности от своего прообраза, поскольку исследователи, решившие избрать этот путь, сталкиваются с рядом серьезных трудностей. Во-первых, процессы, происходящие в мозгу во время решения задачи распознавания изображений изучены далеко не полностью, и тот набор эмпирических знаний о человеческом лице, которые доступны исследователям на сознательном уровне, далеко не исчерпывает инструментарий, используемый мозгом подсознательно. Во-вторых, трудно эффективно перевести неформальный человеческий опыт и знания в набор формальных правил, поскольку чересчур жесткие рамки правил приведут к тому, что в ряде случаев лица не будут обнаружены, и, напротив, слишком общие правила приведут к большому количеству случаев ложного обнаружения.
Распознавание с помощью шаблонов, заданных разработчиком (Template Matching Methods)
Шаблоны задают некий стандартный образ изображения лица, например, путем описания свойств отдельных областей лица и их возможного взаимного расположения. Обнаружение лица с помощью шаблона заключается в проверке каждой из областей изображения на соответствие заданному шаблону.
Особенности подхода:
- два вида шаблонов:
а) недеформируемые
б) деформируемые
- шаблоны заранее запрограммированы, необучаемы
- используется корреляция для нахождения лица на изображении
Метод детектирования лица при помощи трехмерных форм [5] предполагает использование шаблона в виде пар отношений яркостей в двух областях. Для определения местоположения лица необходимо пройти всё изображение на сравнение с заданным шаблоном. Причём делать это необходимо с различным масштабом (Рис. 5).
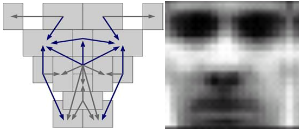
Рис. 5. Метод детектирования лица при помощи трехмерных форм
Модели распределения опорных точек [6] являются статистическими моделями, которые представляют объекты, форма которых может измениться. Их полезная особенность метода — способность выделить форму переменных объектов в пределах учебного набора с небольшим количеством параметров формы (Рис. 6). Эта компактная и точная параметризация может использоваться для разработки эффективных систем классификации.
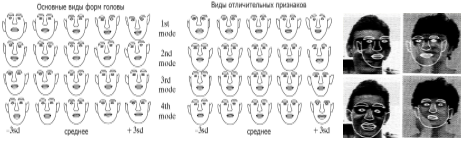
Рис.6 Модели распределения опорных точек
К достоинствам распознавания с помощью шаблонов можно отнести относительную простоту реализации и неплохие результаты на изображениях с не очень сложным задним фоном. А главным недостатком является необходимость калибровки шаблона вблизи с изображением лица. Большая трудоёмкость вычисления шаблонов для различных ракурсов и поворотов лица ставят под вопрос целесообразность их использования.
Методы обнаружения лица по внешним признакам (методы при которых необходимо провести этап обучения системы, путём обработки тестовых изображений)
Изображению (или его фрагменту) ставится в соответствие некоторым образом вычисленный вектор признаков, который используется для классификации изображений на два класса — лицо/не лицо. Обычно поиск лиц на изображениях с помощью методов, основанных на построении математической модели изображения лица, заключается в полном переборе всех прямоугольных фрагментов изображения всевозможных размеров и проведения проверки каждого из фрагментов на наличие лица. Поскольку схема полного перебора обладает такими безусловными недостатками, как избыточность и большая вычислительная сложность, авторами применяются различные методы сокращения количества рассматриваемых фрагментов. Основные принципы методов:
—Схоластика: каждый сканируется окном и представляется векторами ценности
—Блочная структура: Изображение разбивается на пересекающиеся или непересекающиеся участки (Рис. 7) различных масштабов и производится оценка с помощью алгоритмов оценки весов векторов.

Рис. 7. Примеры разбиения изображения на участки
Для обучения алгоритмов требуется библиотека вручную подготовленных изображений лиц и «не лиц», любых других изображений (Рис. 8).

Рис. 8. Пример библиотеки лиц и «не лиц»
Стоит отметить что важнейшей задачей является выделить сильные классификаторы. Именно они будут иметь наивысший приоритет для проверки найденных признаков в изображении. Количество же более слабых классификаторов стоит уменьшать за счёт похожести друг на друга, а также удалении классификаторов, возникших за счёт шумовых выбросов. Перечислим основные методики выполнения этих задач:
- Искусственные нейронные сети (Neural network: Multilayer Perceptrons);
- Метод главных компонент (Princiapl Component Analysis (PCA));
- Факторного анализа (Factor Analysis);
- Линейный дискриминантный анализ (Linear Discriminant Analysis);
- Метод опорных векторов (Support Vector Machines (SVM));
- Наивный байесовский классификатор (Naive Bayes classifier);
- Скрытые Марковские модели (Hidden Markov model);
- Метод распределения (Distribution-based method);
- Совмещение ФА и метода главных компонент (Mixture of PCA, Mixture of factor analyzers);
- Разреженная сеть окон (Sparse network of winnows (SNoW));
- Активные модели (Active Appearance Models);
- Адаптированное улучшение и основанный на нём Метод Виолы-Джонса [7,8] и др.
Рассмотрим особенности некоторых из них. На сегодняшний день метод искусственных нейронных сетей является наиболее распространенным способом решения задач распознавания лиц на изображении. Искусственная нейронная сеть (ИНС) — это математическая модель, представляющая собой систему соединённых и взаимодействующих между собой нейронов. Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Технически обучение заключается в нахождении коэффициентов связей (синапсов) между нейронами (Рис. 9).
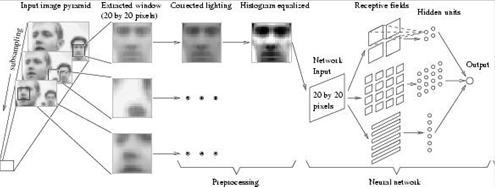
Рис. 9. Обучение системы с помощью нейронной сети
Метод опорных векторов (Support Vector Machines) применяется для снижения размерности пространства признаков, не приводя к существенной потере информативности тренировочного набора объектов. Применение метода главных компонент к набору векторов линейного пространства, позволяет перейти к такому базису пространства, что основная дисперсия набора будет направлена вдоль нескольких первых осей базиса, называемых главными осями. Натянутое на полученные таким образом главные оси подпространство является оптимальным среди всех пространств в том смысле, что наилучшим образом описывает тренировочный набор. Это набор алгоритмов схожих с алгоритмами вида «обучение с учителем», использующихся для задач классификации и регрессионного анализа. Этот метод принадлежит к семейству линейных классификаторов. Метод опорных векторов основан на том, что ищется линейное разделение классов.
Цель тренировки большинства классификаторов — минимизировать ошибку классификации на тренировочном наборе (называемую эмпирическим риском). В отличие от них, с помощью метода опорных векторов можно построить классификатор, минимизирующий верхнюю оценку ожидаемой ошибки классификации (в том числе и для неизвестных объектов, не входивших в тренировочный набор). Применение метода опорных векторов к задаче обнаружения лица заключается в поиске гиперплоскости в признаковом пространстве, отделяющий класс изображений лиц от изображений «не-лиц». Возможность линейного разделения столь сложных классов, как изображения лиц и «не-лиц» представляется маловероятной. Однако, классификация с помощью опорных векторов позволяет использовать аппарат ядерных функций для неявного проецирования векторов-признаков в пространство потенциально намного более высокий размерности (еще выше, чем пространство изображений), в котором классы могут оказаться линейно разделимы. Неявное проецирование с помощью ядерных функций не приводит к усложнению вычислений, что позволяет успешно использовать линейный классификатор для линейно неразделимых классов.
Самым перспективным на сегодняшний день в плане высокой производительности и низкой частоты ложных срабатываний и большим процентом верных обнаружений лиц выглядит метод Виолы-Джонса. Основные принципы, на которых основан метод, таковы:
- используются изображения в интегральном представлении, что позволяет вычислять быстро необходимые объекты;
- используются признаки Хаара, с помощью которых происходит поиск нужного объекта (в данном контексте, лица и его черт);
- используется бустинг (от англ. boost — улучшение, усиление) для выбора наиболее подходящих признаков для искомого объекта на данной части изображения;
- все признаки поступают на вход классификатора, который даёт результат «верно» либо «ложь»;
- используются каскады признаков для быстрого отбрасывания окон, где не найдено лицо.
Обучение классификаторов идет очень медленно, но результаты поиска лица очень быстры, именно поэтому мы заострим внимание на методе распознавания лиц на изображении. Алгоритм хорошо работает и распознает черты лица под небольшим углом, примерно до 30 градусов. При угле наклона больше 30 градусов процент обнаружений резко падает. И это не позволяет в стандартной реализации детектировать повернутое лицо человека под произвольным углом, что в значительной мере затрудняет или делает невозможным использование алгоритма в современных производственных системах с учетом их растущих потребностей.
В общем виде, задача обнаружения лица и черт лица человека на цифровом изображении выглядит так: имеется изображение, на котором есть искомые объекты. Оно представлено двумерной матрицей пикселей размером w*h, в которой каждый пиксель имеет значение:
- от 0 до 255, если это черно-белое изображение;
- от 0 до 255^3, если это цветное изображение (компоненты R, G, B).
В результате своей работы алгоритм должен определить лица и их черты и пометить их — поиск осуществляется в активной области изображения прямоугольными признаками, с помощью которых и описывается найденное лицо и его черты:
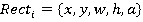 , (2)
, (2)
где x, y — координаты центра i-го прямоугольника, w — ширина, h — высота, a — угол наклона прямоугольника к вертикальной оси изображения. Иными словами, применительно к рисункам и фотографиям используется подход на основе сканирующего окна (scanning window): сканируется изображение окном поиска (так называемое, окно сканирования), а затем применяется классификатор к каждому положению. Система обучения и выбора наиболее значимых признаков полностью автоматизирована и не требует вмешательства человека, поэтому данный подход работает быстро.
Для того, чтобы производить какие-либо действия с данными, используется интегральное представление изображений в методе Виолы-Джонса. Интегральное представление позволяет быстро рассчитывать суммарную яркость произвольного прямоугольника на данном изображении, причем какой бы прямоугольник не был, время расчета неизменно.
Интегральное представление изображения — это матрица, совпадающая по размерам с исходным изображением. В каждом элементе ее хранится сумма интенсивностей всех пикселей, находящихся левее и выше данного элемента. Элементы матрицы рассчитываются по следующей формуле:
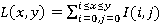 , (3)
, (3)
где I(i,j) — яркость пикселя исходного изображения. Каждый элемент матрицы L [x,y] представляет собой сумму пикселей в прямоугольнике от (0,0) до (x,y).
В стандартном методе Виолы — Джонса используются прямоугольные признаки (Рис. 10) они называются хаароподобными вейвлетами:

Рис. 10. Прямоугольные хаароподобные признаки
Вычисляемым значением такого признака будет F = X-Y, где X — сумма значений яркостей точек закрываемых светлой частью признака, а Y — сумма значений яркостей точек закрываемых темной частью признака. Для их вычисления используется понятие интегрального изображения, рассмотренное выше. Признаки Хаара дают точечное значение перепада яркости по оси X и Y соответственно.
Алгоритм сканирования окна с признаками выглядит так: есть исследуемое изображение, выбрано окно сканирования, выбраны используемые признаки. Далее окно сканирования начинает последовательно двигаться по изображению с шагом в 1 ячейку окна (допустим, размер самого окна есть 24*24 ячейки). Сканирование производится последовательно для различных масштабов, масштабируется не само изображение, а сканирующее окно (изменяется размер ячейки). Все найденные признаки попадают к классификатору, который «выносит вердикт».
В процессе поиска вычислять все признаки на маломощных настольных ПК просто нереально. Следовательно, классификатор должен реагировать только на определенное, нужное подмножество всех признаков. Совершенно логично, что надо обучить классификатор нахождению лиц по данному определенному подмножеству. Это можно сделать, обучая вычислительную машину автоматически.
В контексте алгоритма, имеется множество объектов (изображений), разделённых некоторым образом на классы. Задано конечное множество изображений, для которых известно, к какому классу они относятся (к примеру, это может быть класс «фронтальное положение носа»). Это множество называется обучающей выборкой. Классовая принадлежность остальных объектов не известна. Требуется построить алгоритм, способный классифицировать произвольный объект из исходного множества. Для решения проблемы данного, столь сложного обучения существует технология бустинга — комплекса методов, способствующих повышению точности аналитических моделей. Эффективная модель, допускающая мало ошибок классификации, называется «сильной». «Слабая» же, напротив, не позволяет надежно разделять классы или давать точные предсказания, делает в работе большое количество ошибок. Алгоритм бустинга для поиска лиц таков:
1. Определение слабых классификаторов по прямоугольным признакам;
2. Для каждого перемещения сканирующего окна вычисляется прямоугольный признак на каждом примере;
3. Выбирается наиболее подходящий порог для каждого признака;
4. Отбираются лучшие признаки и лучший подходящий порог;
5. Перевзвешивается выборка.
Каскадная модель сильных классификаторов — это по сути то же дерево принятия решений, где каждый узел дерева построен таким образом, чтобы детектировать почти все интересующие образы и отклонять регионы, не являющиеся образами. Помимо этого, узлы дерева размещены таким образом, что чем ближе узел находится к корню дерева, тем из меньшего количества примитивов он состоит и тем самым требует меньшего времени на принятие решения. Данный вид каскадной модели хорошо подходит для обработки изображений, на которых общее количество детектируемых образов мало. В этом случае метод может быстрее принять решение о том, что данный регион не содержит образ, и перейти к следующему.
Стоит отметить, что в том случае, если на вход системе обнаружения подаётся цветное изображение, то можно существенно увеличить скорость работы алгоритма, обрабатывая предварительно изображение при помощи цветового кодирования [9]. Кроме этого, цветовое кодирование помогает уменьшить число ложных срабатываний.
На сегодняшний день алгоритм Виолы-Джонса является самым востребованным ввиду своей высокой скорости работы и высокой точности срабатывания.
Литература:
1. G. Yang and Thomas S. Huang. «Human face detection in a complex background. Pattern Recognition», 27(1):53–63, 1994.
2. C. Kotropoulos, I. Pitas. «Acoustics, Speech, and Signal Processing», 1997. ICASSP-97, 1997 IEEE International Conference on p.2537–2540 v. 4
3. T. K. Leung, M. C. Burl, P. Perona. «Finding Faces in Cluttered Scenes Using Random Labeled Graph Matching»
4. K. C. Yow, R Cipolla, «Feature-based human face detection», Image and vision computing 15 (9),p. 713–735, 1997
5. Sinha, P. (1996). «Perceiving and Recognizing threedimensional forms» PhD thesis, Massachusetts Institue of Technology.
6. Lanitis, A.; Taylor, C.J.; Ahmed, T.; Cootes, T.F.; Wolfson «Image Anal. Classifying variable objects using a flexible shape model» Image Processing and its Applications, 1995., p.70–74
7. P. Viola and M. J. Jones, «Rapid Object Detection using a Boosted Cascade of Simple Features», proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2001), 2001, vol. 1, p-511 — p-518
8. P. Viola and M. J. Jones, «Robust real-time face detection», International Journal of Computer Vision, vol. 57, no. 2, 2004., pp.137–154
9. Buchatskiy A. N., Tatarenkov D. A., «Selection of the Optimal Color Space for Reducing False Positives Rate in the Viola-Jones Method», Актуальные проблемы инфотелекоммуникаций в науке и образовании, II Международная научно-техническая и научно-методическая конференция. Санкт–Петербург, 2013.
