





В основе создания учебно-информационных материалов, который предполагает поиск и обработку больших объемов информации связано с ростом развития и усовершенствования современных информационных методов обучения. Важным и необходимым условием внедрения данных методов является подготовка и создание инновационных проектов и обучающих информационно-поисковых программ. Обширное развитие обучающих методов данного научного течения подводит к изучению инновационных процессов и созданию новых автоматизированных информационно-поисковых систем. Для получения действующего решения и получения впечатляющих результатов данных исследований новые компьютерные технологии дают возможность применять обычные информационно-поисковые системы (ИПС) для поименнованного поиска научно-технической информации.
Любую предметную область учебно-информационной деятельности, можно описать иерархическим словарем понятий этой области — тезаурусом. Более того, для большинства предметных областей такие тезаурусы давно составлены.
Тезаурус представляет собой дерево понятий для данной предметной области, начиная с верхних, самых общих, и кончая нижними, самыми конкретными, узкими понятиями. Слова (термины) в тезаурусе обычно связаны отношениями "общее-частное", "целое-часть" и т.п.
В более расширенном смысле Тезаурус интерпретируют как описание системы знаний о действительности, которыми располагает индивидуальный носитель информации или группа носителей. Этот носитель может выполнять функции приёмника дополнительной информации, вследствие чего изменяется и его Тезаурус, а исходный Тезаурус определяет при этом возможности приёмника при получении им семантической информации.
Тезаурус – термин, широко используемый в информатике как составная часть информационно-поисковых систем.
Информационно-поисковый тезаурус – это составленный по определенным правилам словарь терминов и словосочетаний, для определенной предметной области, создаваемый для улучшения качества информационного поиска в данной предметной области.
В сфере применения информационно-поисковых тезаурусов различают два основных направления это индексирование документов с использованием определенных правил использующие смысловое значение текста и использование иерархических, ассоциативных и синонимичных связей при обработке поисковых запросов пользователя. Кроме этого, семантические связи между дескрипторами могут быть использованы для классификации и рубрикации документов, составлении списка связанных с запросом слов и некоторых других задачах информационного поиска. На следующем рисунке изображен пример использования тезауруса в информационно-поисковой системе:
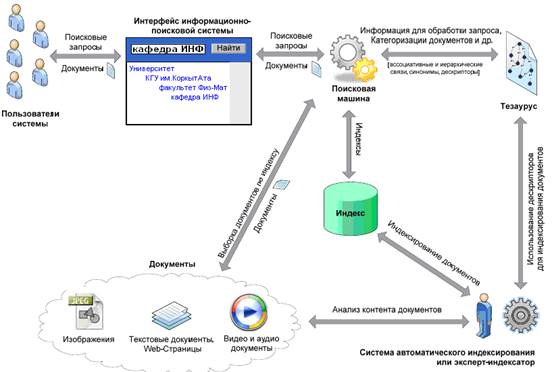
Рис. 1. Пример использования тезауруса в информационно-поисковой системе
Тезаурус состоит из концептов, которые обычно содержат один или несколько дескрипторов связанных отношением синонимии. Дескрипторы представляют собой слова и словосочетания, отражающие основные понятия предметной области. При этом, концепты могут быть связаны ассоциативными, иерархическими и некоторыми другими типами отношений.
Рассмотрим процесс автоматизации выделения терминов предметной области из текста при наличии тезауруса.
Допустим нам дается общий тезаурус предметной области. Тогда все термины, определяющие понятия этого тезауруса, изображаны ввиде множества Хo, Y — множество терминов, находящиеся в тексте Z. Перед нами поставлена задача нахождения
F=Хo ∩Y
При этом допускаем, что исходный тезаурус полон, т.е. множество его терминов должно включать все терминологические словосочетания, используемые в тексте. Для практического выполнения данного метода достаточно наличие большинства терминов в тезаурусе. Точное значение параметра коэффициента присутствия терминов текста в тезаурусе по отношению к общему количеству терминов в тексте не удастся определить, так как на сегодняшний день отнесение или не отнесение термина к предметной области является экспертным решением.
Проблемы выделения терминологии в текстах на естественном языке как одно из ограничений, накладываемых на возможность использования метода.
Наибольшая сложность на этапе выделения терминологии предметной области из текста не в определении пересечения множеств, а в определении самих множеств Хo и Y.
И если все термины тезауруса, являясь терминологической составляющей тезауруса, изначально при построении тезауруса должны быть выделены в отдельную базу данных, то выделение множества терминов в самом тексте Z представляется более проблематичным в силу ряда особенностей естественно-языкового описания предметной области. Естественно-языковому описанию любой предметной области характерны некоторые конструкции, которые используются для свертки текста, такие как однородные члены, анафористические и эллиптические свертки. Дополнительную проблему создает омонимия. Часть проблем, связанных с однородными членами, анафористическими и эллиптическими свертками могут достаточно эффективно быть решены путем ввода в исходный тезаурус широкой базы синонимов, проблемы с разрешением вопросов омонимии могут быть эффективно решены только с помощью статистического анализа текста ближайшего окружения термина, подозрительного на омонимию. К тому или другому синонимическому узлу тезаурусного графа термин может быть отнесен исходя из наибольшего количества терминов, найденных в этом окружении, совпадающих с ближайшими терминами подозрительного на омонимию из тезауруса. В качестве ближайших терминов тезауруса, то есть близости, радиуса 1, выбираются термины, связанные с подозрительным любыми типами связей. Если этого недостаточно, можно расширять как отрезок текста, подвергаемый анализу, на котором встречается термин, подозрительный на омонимию, так и радиус окружения термина из тезауруса.
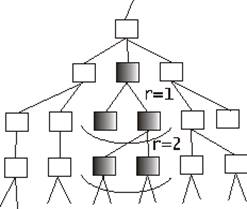
Рис. 2. Тезаурусный радиус для термина
Рисунок 2 иллюстрирует правила выделения в общем тезаурусе терминов для проведения анализа, целью которого является снятие омонимии.
Метод успешно применялся в системах машинного перевода с той разницей, что для всех возможных значений омонимов составлялся отдельный список возможных слов окружения. И эффективность метода доходила до 98%. В случае использования семантического тезауруса такая база для любого термина может генерироваться на основании самого тезауруса описанным выше методом. Однако, статистическими методами полностью преодолеть трудности выделения терминологии, связанные с естественно-языковыми свертками и омонимией не удается. В этой особенности проявляется одно из ограничений использования предлагаемых методик по автоматизации проектирования гипертекста на основе текста с использованием семантического тезауруса. Для решения таких проблем обычно пользуются методами контент-анализа, что эффективно, но дорого и долго.
Литература:
1. Черный А. И., Общая методика построения тезаурусов, «Научно-техническая информация. Сер. 2», 1968, №5; Варга Д., Методика подготовки информационных тезаурусов, пер. [с венг.], М., 1970; Шрейдер Ю. А., Тезаурусы в информатике и теоретической семантике, «Научно-техническая информация. Сер. 2», 1971, № З.
2. Холодова С.А. Некоторые принципы и методики автоматизации проектирования электронных изданий на основе печатных текстов по предметной области. — В «Интеллектуальные технологии и системы. Вып.3. — М., МГУП, 2001.
