





В статье рассматриваются методы анализа тональности текста (сентимент анализа), необходимые для автоматического определения отношения автора к упомянутой теме. Сентимент анализ — область компьютерной лингвистики, является одной из проблем обработки естественного языка. Рассмотрены методы сентимент анализа. Программно реализованы способы — метод, основанный на словарях и метод с использованием библиотеки сентимент анализа Стэнфорда и APIсервиса переводов Яндекса. Методы протестированы на базе, состоящей из 169 комментариев о банках. Проанализированы результаты, даны методы улучшения результатов.
Ключевые слова: анализ тональности текста, сентимент анализ, обработка естественного языка, компьютерная лингвистика, анализ текстов.
Сентимент-анализ (англ. sentiment analysis) — выявление тональности комментария при помощи методов NLP (обработка естественного языка), статистики, машинного обучения. Иногда упоминается как opinion mining, хотя в этом случае делается акцент на извлечение нужного отрывка текста [1]. Технология может использоваться для автоматической оценки новостных событий, продуктов, персоналий, организаций, стран и т. д. [2] Другими задачами сентимент анализа являются поиск спама в отзывах, анализ полезности отзывов, поиск сравнений, извлечение аспектов [3].
На протяжении многих лет ответ на вопрос «Что думают люди?» мог быть получен с помощью социальных вопросников, которые были стандартным способом изучения больших групп. Широкий доступ в Интернет и соцмедиа представили новый способ изучения мнения социальных групп [4]. Анализ этой информации и её использование дает преимущество при маркетинговых исследованиях, отслеживании реакции на новости, политических исследованиях. Обработка информации в условиях динамично растущего Интернета не может быть выполнена без автоматизированных информационных систем.
Подходы для автоматического определения тональности текста
Для автоматического определения тональности текста можно выделить следующие подходы:
1) на основе правил с использованием шаблонов (rule-based with patterns). Подход заключается в генерации правил, на основе которых будет определяться тональность текста. Для этого текст разбивается на слова или последовательности слов (N-grams). Затем полученные данные используются для выделения часто встречающихся шаблонов, которым присваивается положительная или отрицательная оценка. Выделенные шаблоны применяются при создании правил вида «ЕСЛИ условие, ТО заключение»;
2) машинное обучение без учителя (unsupervised learning). Данный подход основан на идее, что наибольший вес в тексте имеют термины, которые чаще встречаются в этом тексте и в то же время присутствуют в небольшом количестве текстов всей коллекции. Выделив данные термины и определив их тональность, можно сделать вывод о тональности всего текста;
3) машинное обучение с учителем (supervised learning). В этом подходе требуется наличие обучающей коллекции размеченных в рамках эмотивного пространства текстов, на базе которой строится статистический или вероятностный классификатор (например, байесовский);
4) гибридный метод (hybrid method). Данный подход сочетает все или несколько из рассмотренных выше принципов и заключается в применении классификаторов на их основе в определенной последовательности [5];
5) метод, основанный на теоретико-графовых моделях. В основе этого метода используется предположение о том, что не все слова в текстовом корпусе документа равнозначны. Какие-то слова имеют больший вес и сильнее влияют на тональность текста. При использовании этого метода анализ тональности разбивается на несколько этапов:
1) построение графа на основе исследуемого текста;
2) ранжирование его вершин;
3) классификация найденных слов;
4) вычисление результата [6].
Проверенные методы сентимент-анализа
а) Метод, основанный на словарях с учетом отрицаний — cоставлены словари положительных и отрицательных слов. Для их заполнения были использованы переведенный список 6800 слов обоих категорий списка на английском [7]. Также словари были вручную скорректированы. При анализе в отзыве подсчитывается количество положительных и отрицательных слов, также учитывается частица «не» перед словом. Если частица «не» встречается перед словом, то слово приобретает противоположную эмоциональную окраску. При сравнении слов использовался стеммер Портера [8]. Стемминг — отсечение от слова окончаний и суффиксов, чтобы оставшаяся часть, называемая stem, была одинаковой для всех грамматических форм слова [9]. Перед обработкой также убираются предлоги и союзы как неинформативные.
б) Метод с использованием библиотеки анализа тональности Стэнфорда и APIсервиса переводов Яндекса — данный метод представляет собой использование библиотеки обработки естественного языка для английского, включающей в себя теоретико-графовый метод, разработанной Стэнфордом и Yandex Translate API для предварительного перевода текста.
В результате проверки были получены следующие результаты: тональность была определена лучше методом, основанном на словарях — оценка была определена правильно для 71 % отзывов. Вторым методом тональность текста была определена для 56 % отзывов.
Анализ полученных результатов и способы улучшения методов
Ошибки данных методов объясняются следующими проблемами:
- многочисленные орфографические ошибки в отзывах
- нет связи с объектов: тональность определяется для всего текста
- не всегда об отношении автора можно сказать по наличию или отсутствию положительных, отрицательных или нейтральных отзывов.
Улучшить результаты автоматического определения тональности текста возможно при помощи использования методов автоматического исправления орфографических ошибок, совершенствования словарей (для методов, основанных на словарях) и обучающей выборки (для методов машинного обучения). Также возможно повысить точность работы алгоритмов, применяя разработки по другим проблемам естественного языка, таких как:
- автоматическое реферирование (automatic summarization)
- выявление кореферентности, референционального множества (coreference resolution)
- анализ сравнений
- извлечение объектов из текстов (Named-entity recognition, NER) и выявление отношений между ними (Relationship extraction).
Рассмотрение способов сентимент анализа показало, что необходимо анализировать связи между словами для корректного определения тональности. Невозможно проанализировать отзыв, игнорируя особенности структуры языка, на котором анализируется комментарий, т. е. необходимы или выявление отношений между объектами предложений или анализ синтаксической структуры предложения. Для данных задач разработано большое количество методов и готовых программных средств для английского языка. Для русского языка готовых решений меньше, и многие из них являются коммерческими.
Так же следует отметить, что не все решения для англоязычных текстов могут быть успешно адаптированы под русский язык. Это объясняется разной структурой английского и русского языков — русский язык является синтетическим языком, английский — аналитическим. В синтетических языках связи между словами обозначаются при помощи изменения строения слова (окончания, удвоения основы). В аналитических — связи между словами обозначены порядком слов. Отсутствие регламентированного расположения слов как в английском, делает анализ русскоязычных текстов более сложной задачей.
Методы сентимент анализа, учитывающие синтаксическую структуру текста
Метод, описанный в [10], учитывает связи между словами в предложении, разработан для русскоязычных текстов. В нем используются описания наиболее частых структур текста, используемых для выражения отношения к объекту. Для анализа цепочек текста в нем используется Томита парсер, разработанный Яндексом. Прописав свои правила и словари, возможно использование Томита парсера для различных задач анализа текста [11].
Метод, описанный в [12], основывается на деревьях зависимостей, разработан для англоязычных текстов. В нем слова предложения представлены узлами дерева. Используются словари положительных и отрицательных слов и слов-инверторов (слова, которые могут поменять полярность всего предложения — например, нет, не, устранили). Значения вышестоящего узла рассчитывается с учетом значений нижестоящих узлов, способности слова инвертировать тональность текста и тональности слова, взятой из словаря. В работе был дан пример: Kidnapped AP photographer freed in Gaza (Похищенный AP фотограф освобожден в Газа). Здесь слова похищенный и Газа являются отрицательными, освобожден — положительным. То есть если не учитывать структуры предложения — выйдет, что новость является отрицательной: два отрицательных слова и одно положительное.
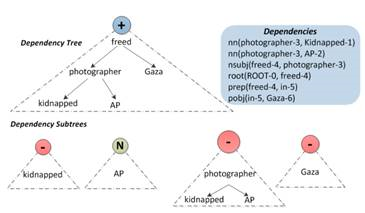
Рис. 1. Дерево зависимостей
В методе используется два типа свойств: узловые и граничные. Узловые обозначают узлы дерева, а граничные — связи между словами. Узловые свойства содержат априорную тональность слова, которая может быть получена использованием словарей. Например, в рис. 1 похищенный (kidnapped) — отрицательное слово, AP — нейтральное, фотограф (photograph) — нейтральное. Отрицательная полярность ветки «похищенный» переходит на узел «фотограф». Узел «фотограф» теперь отрицательный. Узел «Газа» — отрицательный (само слово для новостей имеет отрицательный смысл, определили с помощью словарей). Теперь отрицательным стал узел стоящий выше — freed (освобожденный). Но слово «освобожденный» является словом-инвертором. И поэтому конечная тональность предложения — положительная.
Не всегда возможно построить одно наиболее правильное дерево зависимостей, особенно для языка со свободной структурой. Возможное решение данной проблемы дано в работе [13]. Вместо использования свойств-границ, соединяющих зависимый узел и его родителя, предлагается использовать свойства гипер границы, которые соединяют всех потомков корневого узла дерева, т. е. слово может быть потомком нескольких узлов дерева. После этого для подсчета конечного результата для корневого узла выделяются все возможные поддеревья. Так как их может быть довольно много, то часть из них исключается статистическими методами. Конечный результат высчитывается, учитывая все оставшиеся поддеревья.
В работе [14] предлагается метод классификации отзывов, основанный на машинном обучении с учителем с использованием n-грамм слов (последовательностей из нескольких слов) в качестве свойств.
Заключение
В данной статье были рассмотрены методы анализа тональности текста для русского языка. Было определено, что наилучшими способами являются способы, в которых учитываются связи между словами, структура языка.
Литература:
1. Introduction to Sentiment Analysis, http://www.lct-master.org/files/MullenSentimentCourseSlides.pdf
2. Александр Прохоров, Александр Керимов, Сентимент-анализ и продвижение в социальных медиа http://compress.ru/article.aspx?id=23115
3. Александр Уланов, Обработка текстов на естественном языке (Лекция 10. Анализ мнений) https://compscicenter.ru/media/slides/nlp_2014_spring/2014_04_28_nlp_2014_spring.pdf
4. Yelena Aleksandrovna Mejova, SENTIMENT ANALYSIS WITHIN AND ACROSS SOCIAL MEDIA STREAMS, http://ir.uiowa.edu/cgi/viewcontent.cgi?article=3090&context=etd
5. М. В. Клековкина, Е. В. Котельников, Метод автоматической классификации текстов по тональности, основанный на словаре эмоциональной лексики, http://ceur-ws.org/Vol-934/paper15.pdf
6. Анализ тональности текста, https://ru.wikipedia.org/wiki/
7. Hu and Liu, A list of positive and negative opinion words or sentiment words for English, http://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html#lexicon
8. Стеммер Портера для русского языка http://www.algorithmist.ru/2010/12/porter-stemmer-russian.html
9. Стеммер, http://www.solarix.ru/for_developers/api/stemmer.shtml
10. Mavljutov R. R., Ostapuk N. A., Using basic syntactic relations for sentiment analysis, http://www.dialog-21.ru/digests/dialog2013/materials/pdf/MavljutovRR.pdf
11. Как использовать Томита-парсер в своих проектах. Практический курс, http://habrahabr.ru/company/yandex/blog/225723/
12. Ugan Yasavur, Jorge Travieso, Christine Lisetti, Naphtali Rishe, Sentiment Analysis Using Dependency Trees and Named-Entities, https://www.aaai.org/ocs/index.php/FLAIRS/FLAIRS14/paper/view/7869
13. Zhaopeng Tu, Wenbin Jiang, Qun Liu, and Shouxun Lin, Dependency Forest for Sentiment Analysis, http://www.zptu.net/papers/nlp2012_dependency_forest_for_sa.pdf
14. Dmitriy Bespalov, Sentiment Classification Based on Supervised Latent n-gram Analysis, http://www.cs.cmu.edu/~qyj/papersA08/11-talk-cikm11.pdf
