





Рассматриваются вопросы разработки алгоритмического и программного обеспечения для управления многопроцессорными параллельными вычислительными системами распределенного и облачного типа на базе концептуально нового поколения вычислительной техники — нейрокомпьютеров, принцип функционирования которых основан на принципах мышления человека. Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 14–07–00261 а.
Ключевые слова: нейрокомпьютер, управление, распределенные системы, облачные системы, параллелизм.
В настоящее время нейрокомпьютерная технология является одним из наиболее быстроразвивающихся разделов вычислительной техники и новым — “интеллектуальным” этапом ее развития. Использование нейропроцессоров позволяет при решении некоторых задач повысить скорость обработки до 2048 раз, а энергоэффективность до 100 раз. Но для дальнейшего развития в этой области существует ряд проблем, одной из которых является небольшая частота нейрочипов (30–150 МГц). Для ее решения одним из лучших методов является использование многопроцессорных архитектур, для которых практически отсутствует математическое, алгоритмическое и программное обеспечение различного назначения, в том числе и для управления [1,2].
Цель работы: разработка алгоритмического обеспечения и программных средств управления вычислительными системами различного типа на базе нейропроцессоров.
Для решения поставленных задач будем рассматривать пример использования нейропроцессора семейства NM640x, разрабатываемые НТЦ «Модуль» в качестве вычислительного узла системы. Введем понятие host-процессора — процессора, который будет осуществлять непосредственное управление системой и nm-процессора — нейропроцессора [3–11].
Host-интерфейс проектировался исходя из следующих предпосылок и требований:
- наиболее распространённым прикладным сценарием взаимодействия PC-машины и целевых устройств конструктива PCI с разделяемой памятью является сценарий, в котором инициатором взаимодействия является host-процесс: он инициализирует устройство, загружает прикладную задачу, принимает и отображает результаты её работы. В таких сценариях nm-процесс играет подчинённую роль;
- базовый интерфейс библиотеки должен быть инвариантен относительно разных типов устройств (но всё того же класса PCI-устройств с разделяемой памятью);
- интерфейс библиотеки должен обеспечивать инвариантность кода прикладных host-программ относительно разных процессоров многопроцессорных устройств (или, как минимум, лёгкую перенацеливаемость);
- интерфейс библиотеки должен быть минимальным.
Host-интерфейс библиотеки достаточно универсален, чтобы покрыть большой класс устройств с общей памятью и произвольным количеством процессоров:
- сокрытие особенностей доступа к конкретному устройству и особенностей взаимодействия с процессорами устройства достигается за счёт использования дескрипторов доступа к экземплярам устройств процессоров;
- в функциях выдачи дескрипторов доступа экземпляры устройств и процессоров идентифицируются порядковыми номерами в 32-разрядном слове.
Имена типов дескрипторов в фиксированы и от реализаций библиотеки для разных устройств не зависят. Благодаря этому host-часть прикладной программы возможно перенацеливать на иное устройство без изменения существенного кода, простой заменой заголовочного файла. Используя динамическую загрузку host-части библиотеки, возможно параметризовать выбор реализации библиотеки во время исполнения, в таком случае для перенацеливания перекомпиляция прикладной программы не требуется вовсе.
Доступ к разным процессорам многопроцессорного устройства не может осуществляться полностью идентичным образом; при переходе от одного процессора устройства к другому host-процесс должен задействовать иные связи, иные адреса разделяемой памяти. Данная проблема решается путём использования функциями пересылки блоков памяти целевой адресации — функции принимают в качестве аргумента дескриптор целевого процессора и адрес в адресном пространстве этого процессора, скрывая от пользователя библиотеки сложности пересчёта целевого адреса в смещение разделяемой памяти. Таким образом для перенацеливания host-части программы на работу с nm-частью, загруженной на другой процессор устройства достаточно изменить индекс процессора при вызове.
Для успешной работы модуля управления необходимы следующие параметры [5]:
1. Количество нейропроцессорных модулей.
2. Вид структуры: конвейерная, векторная, конвейерно-векторная (несколько параллельных векторных потоков обрабатываются по принципу конвейера), векторно-конвейерная (параллельно обрабатываются несколько потоков, которые, в свою очередь, обрабатываются по принципу конвейера) или произвольная.
3. Если была выбрана произвольная структура, то необходима идентификация активных связей между нейропроцессорными модулями.
4. Выбор используемого аппаратного обеспечения: модель нейропроцессора или модель эмулятора.
Для управления сложной вычислительной системой на базе нейропроцесоров реализованы следующие функции nm-части: определение номера текущего процессора; барьерная синхронизация с host-процессом, скаляром (то есть передача одного элемента); барьерная синхронизация с host-процессом, массивом (то есть передача нескольких элементов на нейропроцессор).
Для управления сложной вычислительной системой на базе нейропроцесоров реализованы следующие функции host-части: определение номера версии библиотеки для использования нужного драйвера; определение количества доступных экземпляров модуля (то есть количество элементов в системе); получение дескриптора доступа к экземпляру модуля; завершение работы с модулем; перезагрузка экземпляра модуля; загрузка кода начальной инициализации (код передается автоматически); получение дескриптора доступа к процессору модуля; получение дескриптора доступа к процессору модуля; маскирование прерываний с процессоров модуля на PC; ожидание прерывания с процессоров модуля на PC; загрузка и исполнение пользовательской программы; запись блока данных в разделяемую память модуля; чтение блока из разделяемой памяти модуля; барьерная синхронизация с nm-процессом, скаляром (взаимодействует с аналогичной функцией для nm-части); барьерная синхронизация с nm-процессом, массивом (взаимодействует с аналогичной функцией для nm-части); установка времени ожидания функциям синхронизации; посылка прерывания на процессор; перезагрузка экземпляра модуля и запуск на исполнение внутренний загрузочный код модуля; запрос статуса.
Для более эффективного управления нейропроцессорной системой можно использовать также порт JTAG, имеющийся во всех нейропроцессорах, выпускаемых Texas Instruments и НТЦ «Модуль». Это интерфейс предназначен для подключения сложных цифровых микросхем или устройств уровня печатной платы к стандартной аппаратуре тестирования и отладки.
Для возможности управления распределенными связями между нейропроцессорами кластера или облачного цетра обработки данных было необходимо реализовать возможность множественных удаленных подключений к нейропроцессорам, распределенным в пространстве. В качестве провайдера подключения была выбрана технология организации IIS сервера и технология XML для обеспечения интерфейса подключения к процессору. Полностью были реализованы вышеперечисленные функции в виде ссылок XML для подключения и доступа к нейропроцессору. Также сохранены необходимые для работы глобальные XML-переменные.
Далее были реализованы алгоритмы подключения к удаленным нейропроцессорным устройств и двусторонней передачи данных. На рисунке 1 показана диаграмма управления нейропроцессорной системой. Модуль управления работает в зависимости от выбранной нейропроцессорной структуры (конвейерная, векторная, конвейерно-векторная и т. д.).
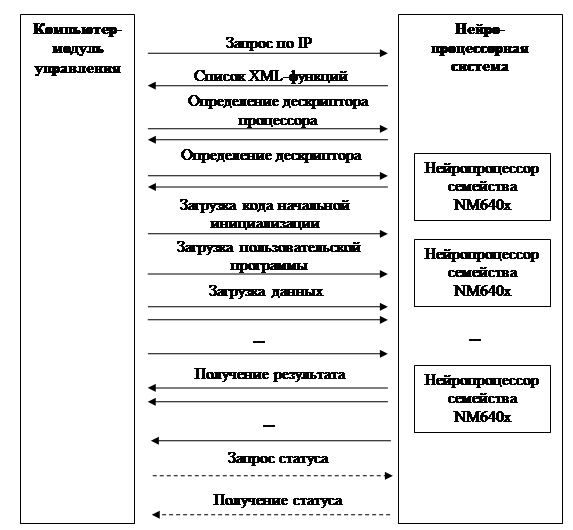
Рис. 1. Схема действий при работе с удаленным нейропроцессором
Операции «Запрос статуса» и «Получение статуса» являются необязательными и используются в случае отсутствия сигналов от какого-либо процессора или подозрительных результатов выполнения операции.
Литература:
1. Галушкин А. И. Нейронные ЭВМ — перспективное направление развития вычислительной техники — М.: Препринт, 1991.-615 с.
2. Головкин Б. А. Вычислительные системы с большим числом процессоров. М.: Радио и связь, 1995. — 320 с.
3. Романчук В. А., Ручкин В. Н., Колмыков М. В. Возможности программного комплекса NM Model для разработки и отладки программ обработки изображений // Вестник РГРТУ. — Рязань: РГРТУ, 2008. — № 2. — Вып. 24. — С.83–85.
4. Vladimir Ruchkin, Vladimir Fulin, Vitaliy Romanchuk , Boris Kostrov and Ekaterina Ruchkina. Parallelism in Embedded microprocessor System Based on Clustering // Proceedings of the 4nd Mediterranean Conference on Embedded Computing (MECO). — Budva, Montenegro, 2015. — С.45–50.
5. Романчук В. А., Ручкин В. Н. Алгоритмы анализа вычислительных структур на базе нейропроцессоров // Вестник РГРТУ. — Рязань: РГРТУ, 2012. — № 2. — Вып.40. — С.60–66.
6. Романчук В. А., Ручкин В. Н. Разработка алгоритмов определения вида структуры нейропроцессорной системы на основе описания связей ее элементов // Информатика и прикладная математика: межвуз. сб. науч. тр. — Рязань: РГУ имени С. А. Есенина, 2011. — Вып.17. — С.106–109.
7. Злобин В. К., Григоренко Д. В., Ручкин В. Н., Романчук В. А. Кластеризация и восстанавливаемость нейропроцессорных систем обработки данных // Известия тульского государственного университета. Технические науки. — Тула: Издательство ТулГУ, 2013. — Вып.9. — Ч.2. — С.125–135.
8. Романчук В. А., Ручкин В. Н. Оценка результатов моделирования вычислительных систем на базе нейропроцессоров // Известия тульского государственного университета. Технические науки. — Тула: Издательство ТулГУ, 2013. — Вып.9–2 — С.194–203.
9. Романчук В. А., Лукашенко В. В. Разработка математической модели реструктуризуемого под классы задач, виртуализируемого кластера GRID-системы на базе нейропроцессоров // Вестник РГУ имени С. А. Есенина. — Рязань: РГУ имени С. А. Есенина, 2014. — № 1(42). — C. 177- 182.
10. Романчук В. А. Инновационный программный комплекс моделирования вычислительных систем на базе нейропроцессоров «НейроКС» // Современные научные исследования и инновации. — Декабрь, 2012 [Электронный ресурс]. — URL: http://web.snauka.ru/issues/2012/12/19407.
11. Романчук В. А. Разработка алгоритмов определения связей элементов вычислительной структуры на базе нейропроцессоров // Информатика и прикладная математика: межвуз. сб. науч. тр. — Рязань: РГУ имени С. А. Есенина, 2011. — Вып.17. — С.102–105.
