





1. Введение
Шагающие роботы уже на один десяток лет вызывают повышенный интерес со стороны ученых и инженеров-робототехников [1–2]. Одна из причин такого внимания — это исключительные возможности передвижения по пересеченной местности по сравнению с традиционными колесными или гусеничными роботами. Действительно, подобные роботы способны передвигаться по неровным поверхностям, перешагивать препятствия, пересекать овраги, шагать по лестницам и даже, при соответствующей конструкции, карабкаться по стенам и деревьям. Многоногие роботы с тремя и более парами ног представляют особый интерес, поскольку они, во-первых, статически устойчивы, а во-вторых, более надежны, поскольку потеря одной или нескольких конечностей для таких роботов не является фатальной.
Однако обратной стороной указанных преимуществ является значительная сложность управления подобными роботами, связанная с наличием большего количества управляемых степеней свободы (гиперизбыточность). По этой причине даже непосредственное ручное управление человеком подобной машиной невозможно. Это означает, что шагающая машина, даже в случае ручного управления человеком, все равно должна обладать автоматической системой управления движением, хотя бы на уровне контроля и координации работы ног.
В настоящее время системы управления шагающими роботами в основном конструируются вручную. При таком подходе разработчик старается заранее предусмотреть и запрограммировать все возможные формы передвижения и ситуации, когда их необходимо применять. Однако из-за наличия большого количества степеней свободы вручную задать сенсорно-моторную функцию, определяющую траектории движения всех конечной с учетом показаний сенсоров, а также учесть все виды поверхностей, по которым может передвигаться робот, достаточно сложно. Особенно тяжело предусмотреть возможность адаптации в случае неожиданного изменении окружающей среды или поломки отдельных частей робота. Поэтому становиться актуальным разработка способов автоматического порождения системы управления на основе различных моделей обучения.
Однако использование популярных методов, таких как обучение с подкреплением (Reinforcement Learning), напрямую для генерации систем управления гиперизбыточными роботами оказывается затруднительным по причине наличия большого количества степеней свободы у подобных роботов. Поэтому в настоящее время многие разработчики в основном отдают предпочтение эволюционным методам, в частности, генетическим алгоритмам и генетическому программированию, а также их комбинациям со стандартными методами обучения [3–6].
Но применение эволюционных методов также имеет недостатки, основными из которых являются следующие [7]. Во-первых, это существенное время, требуемое на проведение вычислений, поскольку на каждом эволюционном шаге каждое решение из популяции требует оценки эффективности способа перемещения. Во-вторых, это практическая невозможность применения данного метода для адаптации в условиях реальной работы, поскольку для работы метода необходимо наличие популяции роботов.
В данной работе предлагается обучающаяся система управления, использующая логико-вероятностный метод извлечения знаний для генерации правил управления на основании опыта взаимодействия системы с окружающей средой [8–10]. Особенностью предлагаемого подхода является использование свойств симметрии в конструкции робота для построения системы управления и ее обучения. Действительно, многоногие роботы обычно имеют симметричную морфологию, которая позволяет функционально разбить конструкцию робота на модули таким образом, что подсистема управления каждого из них будет контролировать только одну пару конечностей. При этом правила управления схожими парами конечностей могут в большой степени совпадать либо вообще быть идентичными. Чтобы эффективно использовать подобные свойства симметрии модулей, в данной роботе предлагается специальный метод поиска управляющих правил, который в первую очередь пытается найти правила, общие для всех модулей, а уже затем специфицировать их для каждого конкретного модуля в отдельности. Эффективность подхода оценивается на примере обучения способам передвижения виртуальной модели многоногого робота.
2. 3D симулятор многоногого робота
Для проведения экспериментов с предложенной моделью управления был разработан интерактивный 3D-симулятор с графическим интерфейсом. Основное назначение программы — проведение экспериментов по управлению роботами в среде, приближенной к реальному миру. Программа обладает возможностями визуализации виртуальной среды и записью экспериментов в видео-файл. В качестве физического движка в симуляторе используется библиотека Open Dynamic Library (ODE) [11], которая позволяет моделировать динамику твердых тел с различными видами сочленений. Преимуществом данной библиотеке является скорость, высокая стабильность интегрирования, а также встроенное обнаружение столкновений.

Рис. 1. Модель многоногого робота
Модель многоногого робота представлена в симуляторе в виде конструкции из шести одинаковых модулей, связанных друг с другом жесткими сочленениями (рис. 1). Каждый модуль имеет пару Г-образных ног с правой и левой стороны соответственно. Таким образом, суммарно робот имеет двенадцать ног-конечностей. Каждая нога соединена с модулем при помощи универсального сочленения, имеющего два угловых двигателя, которые позволяют вращать ногу в суставе в горизонтальной и вертикальной плоскостях. В целом, конструкция робота напоминает своим видом биологических многоножек и позволяет реализовать характерные для данного вида способы передвижения.
3. Модель обучающейся системы управления
Для создания системы управления модульными роботами предлагается использовать нейронные сети, состоящие из обучаемых логических нейронов, каждый из которых управляет отдельным модулем робота.
Логические нейроны функционируют в дискретном времени 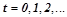 . Каждый нейрон содержит некоторый набор входов
. Каждый нейрон содержит некоторый набор входов 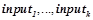 , принимающих действительные значения, и один выход
, принимающих действительные значения, и один выход 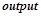 , принимающий значения из заранее заданного набора
, принимающий значения из заранее заданного набора 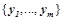 . В каждый момент времени
. В каждый момент времени 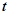 на входы нейрона подается входящая информация путем присвоения входам некоторых действительных значений
на входы нейрона подается входящая информация путем присвоения входам некоторых действительных значений  ,
, 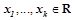 . Результатом работы нейрона является выходной сигнал
. Результатом работы нейрона является выходной сигнал 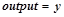 ,
, 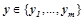 , принимающий одно из возможных значений.
, принимающий одно из возможных значений.
После того, как отработают все нейроны сети, от внешней среды поступает награда. Функция награды задается в зависимости от конечной цели и служит оценкой качества управления. Задачей системы управления является обнаружение таких закономерностей функционирования нейронов, которые бы обеспечивали получение максимальной награды.
Множество закономерностей, определяющих работу нейронов, предлагается искать в виде логических закономерностей с оценками, имеющих следующий вид:
 ,
, где 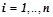 — переменная по объектам — индексам нейронов.
— переменная по объектам — индексам нейронов.
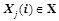 — предикаты из заданного множества входных предикатов
— предикаты из заданного множества входных предикатов  , описывающих входы
, описывающих входы 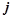 нейронов
нейронов 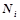
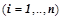 . К примеру, в простейшем случае данные предикаты могут быть заданы как
. К примеру, в простейшем случае данные предикаты могут быть заданы как  , где
, где  — некоторые константы из области значении входящих сигналов, которые могут быть заданы, к примеру, путем квантования диапазона возможных значений соответствующих входов нейронов.
— некоторые константы из области значении входящих сигналов, которые могут быть заданы, к примеру, путем квантования диапазона возможных значений соответствующих входов нейронов.
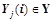 — предикаты из заданного множества выходных предикатов
— предикаты из заданного множества выходных предикатов 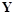 , описывающих выходы нейронов и имеющих вид
, описывающих выходы нейронов и имеющих вид 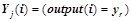 , где
, где 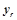 — некоторые константы из набора значений выходных сигналов.
— некоторые константы из набора значений выходных сигналов.
 — предикаты из множества предикатов
— предикаты из множества предикатов  , имеющих вид
, имеющих вид 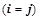 , где
, где 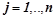 , смысл которых — сужать область применения правил вида до конкретных нейронов.
, смысл которых — сужать область применения правил вида до конкретных нейронов.
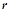 — награда, максимизация которой является постоянной задачей нейрона.
— награда, максимизация которой является постоянной задачей нейрона.
Данные закономерности предсказывают, что если на вход нейрона , будут поданы сигналы, удовлетворяющие входным предикатам 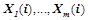 из посылки правила, и нейрон подаст на свой выход сигнал, указанный в выходном предикате
из посылки правила, и нейрон подаст на свой выход сигнал, указанный в выходном предикате 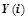 , то математическое ожидание награды будет равно некоторой величине .
, то математическое ожидание награды будет равно некоторой величине .
Отдельно отметим, что если какой-либо нейрон 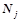 имеет вход, специфичный только для этого нейрона, то предполагаем, что предикат
имеет вход, специфичный только для этого нейрона, то предполагаем, что предикат 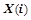 , описывающий этот вход, будет принимать значение «0» для всех
, описывающий этот вход, будет принимать значение «0» для всех 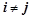 , т. е. для всех других нейронов. Аналогично, если выход какого-либо нейрона может принимать некоторое значение
, т. е. для всех других нейронов. Аналогично, если выход какого-либо нейрона может принимать некоторое значение  , характерное только для этого нейрона, то соответствующий выходной предикат
, характерное только для этого нейрона, то соответствующий выходной предикат  также будет принимать значение «0» для всех .
также будет принимать значение «0» для всех .
Поясним необходимость введения множества предикатов . В том случае, если правила не содержит предикатов из , то они будут иметь вид  и будут описывать закономерности, общие для всех нейронов , . Добавление в посылку правила предиката из автоматически суживает область применения правила до конкретного нейрона. Таким образом, правила, содержащие предикаты из , описывают закономерности, специфичные для конкретных нейронов. Также следует отметить, что сужение области применимости правил может происходить не только за счет предикатов из , но также за счет входных либо выходных предикатов из и , описывающих специфичные входы либо выходы конкретных нейронов.
и будут описывать закономерности, общие для всех нейронов , . Добавление в посылку правила предиката из автоматически суживает область применения правила до конкретного нейрона. Таким образом, правила, содержащие предикаты из , описывают закономерности, специфичные для конкретных нейронов. Также следует отметить, что сужение области применимости правил может происходить не только за счет предикатов из , но также за счет входных либо выходных предикатов из и , описывающих специфичные входы либо выходы конкретных нейронов.
Для нахождения закономерностей вида предлагается использовать алгоритм, основанный на идеях семантического вероятностного вывода, описанного в работах [12]. При помощи данного алгоритма анализируется множества данных, хранящих статистику работы нейронной сети (вход-выход нейронов и полученная награда) и извлекаются все статистически значимые закономерности вида .
В данной работе мы не будем приводить описание алгоритма семантического вероятностного вывода. Подробное описание можно найти в работах [8,12]. Отмети только, что суть алгоритма заключается в последовательном уточнении правил, начиная с правил единичной длины, путем добавления в посылку правил новых предикатов с последующей проверкой уточненных правил на принадлежность к вероятностным закономерностям. По существу реализуется направленный перебор правил, позволяющий существенно сократить пространство поиска. Сокращение перебора достигается за счет использования эвристики, которая заключается в том, что, начиная с момента, когда длина посылки правил достигает некоторой заданной величины, называемой глубиной базового перебора, начинается последовательное уточнение только тех правил, которые являются вероятностными закономерностями.
Преимущество использования семантического вероятностного вывода и правил вида состоит в организации поиска правил таким образом, что сначала будут обнаруживаться правила, общие для всех нейронов, а только затем — более сложные, включающие специфичные для конкретных нейронов правила. В результате, в задачах управления модульными роботами, если хотя бы часть модулей имеет схожие функции, которые можно описать общими правилами, предложенный подход позволяет существенно сократить время поиска решения.
Функционирование нейронной сети в целом происходит следующим образом. На каждом такте работы сети на входы нейронов поступают входящие сигналы. После чего последовательно для каждого нейрона запускается процедура принятия решения, в процессе которой из множества правил, описывающих работу нейронов, выбираются те, которые применимы к текущему нейрону на текущих входных сигналах. Затем среди отобранных правил выбирается одно правило, прогнозирующее максимальное значение математического ожидания награды . Далее на выход нейрона подается выходной сигнал , указанный в правиле. В начальной стадии функционирования сети, когда множество правил, описывающих работу нейронов, еще пусто, либо когда нет правил, применимых к текущему набору входящих сигналов, выход нейрона определяется случайным образом. После того, как все нейроны сгенерируют свои выходные сигналы, от внешней среды поступает награда и осуществляется обучение, в процессе которого ищутся новые и корректируются текущие правила работы в соответствии с предложенным алгоритмом поиска закономерностей.
4. Система управления движением многоногого робота
Для задачи управления многоногим роботом был выбран нейронный контур, состоящий из шести нейронов — по одному нейрону на каждый модуль робота (рис. 2). Каждый нейрон ,  контролирует движения левой и правой ноги своего модуля, подавая активирующие сигналы на соответствующие угловые двигатели, вращающие конечности в суставе. Чтобы немного упростить задачу, движения правой и левой ног робота были синхронизированы таким образом, что движение одной ноги всегда происходит в противофазе с другой. Т. е., к примеру, движение левой ноги вперед всегда сопровождается движением правой ноги назад. Таким образом, нейрону, по сути, достаточно контролировать движения только одной ноги, поскольку вторая нога будет повторять эти же движения, только в противофазе.
контролирует движения левой и правой ноги своего модуля, подавая активирующие сигналы на соответствующие угловые двигатели, вращающие конечности в суставе. Чтобы немного упростить задачу, движения правой и левой ног робота были синхронизированы таким образом, что движение одной ноги всегда происходит в противофазе с другой. Т. е., к примеру, движение левой ноги вперед всегда сопровождается движением правой ноги назад. Таким образом, нейрону, по сути, достаточно контролировать движения только одной ноги, поскольку вторая нога будет повторять эти же движения, только в противофазе.
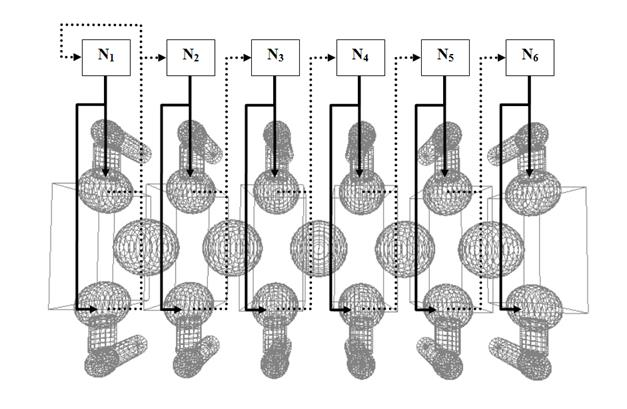
Рис. 2. Схема нейронного контура управления движением
Нейрон первого модуля  получает на вход информацию о положении ног первого модуля. Остальные нейроны ,
получает на вход информацию о положении ног первого модуля. Остальные нейроны ,  получают на свои вход данные о положении ног предыдущего модуля. Информация о положение ноги задается парой углов сгиба конечности в суставе в вертикальной и горизонтальной плоскостях.
получают на свои вход данные о положении ног предыдущего модуля. Информация о положение ноги задается парой углов сгиба конечности в суставе в вертикальной и горизонтальной плоскостях.
Множество входных и выходных предикатов для нейронов задается путем квантования диапазона возможных значений соответствующих входов и выходов нейрона. Награда для всего нейронного контура управления движением определяется в зависимости от величины скорости, которую разовьет робот на отрезке времени  : чем выше скорость — тем больше награда.
: чем выше скорость — тем больше награда.

Рис. 3. Последовательность движений робота при перемещении вперед
При помощи 3D-симулятор была проведена серия экспериментов по обучению движению модели многоногого робота. Результаты экспериментов показали, что система управления успешно обнаруживает согласованные движения конечностей, обеспечивающие эффективное перемещение вперед. На рисунке 3 приведен пример оптимальной последовательности движений, найденной в процессе обучения.
5. Заключение
В данной работе предложен подход к адаптивному управлению модульными системами с большим числом степеней свободы, основанный на совместном обучении управляющих модулей, начиная с нахождения общих для всех модулей управляющих правил и закачивая их последующей спецификацией в соответствии с идеями семантического вероятностного вывода. Полученные результаты показывают, что предложенная модель системы управления способна обучиться сложным формам передвижения, основываясь только на опыте взаимодействия системы с окружающей средой. Кроме того, стоит отметить, что предложенный подход хорошо масштабируется относительно увеличения числа конечностей: добавление новых модулей к конструкции робота не приводит к увеличению количества общих правил и поэтому слабо влияет на эффективность системы. С практической точки зрения, проведенные экспериментальные исследования на примере многоногого робота показывают, что предложенный подход является достаточно эффективным и может быть использован для управления сложными модульными системами, имеющими множество степеней свободы.
Литература:
1. Raibert M. H. Legged robots // Communications of the ACM. — 1986. — 29(6). — pp. 499–514.
2. Silva M. F., Machado J. A. T. A historical perspective of legged robots // Journal of Vibration and Control. — 2007. — V.13. — 9–10. — pp. 1447–1486.
3. Bongard J. C. Evolutionary Robotics // Communications of the ACM. — 2013. — Vol. 56. — No. 8. — pp. 74–83.
4. Daoxiong Gong, Jie Yan, Guoyu Zuo. A Review of Gait Optimization Based on Evolutionary Computation // Applied Computational Intelligence and Soft Computing. — 2010. — vol. 2010. — Article ID 413179. — 12 p.
5. Valsalam V. K. Miikkulainen R. Modular neuroevolution for multilegged locomotion // In Proceedings of GECCO. — 2008. — pp. 265–272.
6. lto K., Matsuno F. A study of reinforcement learning for the robot with many degrees of freedom — acquisition of locomotion patterns for multi legged robot // In Proc. of IEEE Int. Conf. on Robotics and Automation. — 2002. — pp. 3392–3397.
7. Mataric M., Cliff D. Challenges in evolving controllers for physical robots // Robotics and Autonomous Systems. — October 1996. — 19(1). — pp. 67–83.
8. Демин А. В., Витяев Е. Е. Логическая модель адаптивной системы управления // Нейроинформатика. — 2008. — Т. 3. — № 1. — С. 79–107.
9. Демин А. В. Обучающаяся модель управления хемотаксисом нематоды C.Elegans // Нейроинформатика. — 2013. — Т. 7. — № 1. — С. 29–41.
10. Demin A. V., Vityaev E. E. Learning in a virtual model of the C. elegans nematode for locomotion and chemotaxis // Biologically Inspired Cognitive Architectures (2014). — Elsevier, 2014. — V. 7. — pp. 9–14.
11. Smith R. Open Dynamics Engine. — URL: http://ode.org/.
12. Витяев Е. Е. Извлечение знаний из данных. Компьютерное познание. Модели когнитивных процессов. — Новосибирск: НГУ, 2006. — 293 с.
