




Нестрогое сопоставление записей реляционных баз данных с использованием редакционного расстояния между кортежами и ключевого набора атрибутов

Автор: Райкова Ольга Анатольевна
Рубрика: 1. Информатика и кибернетика
Опубликовано в
Статья просмотрена: 451 раз
Библиографическое описание:
Райкова, О. А. Нестрогое сопоставление записей реляционных баз данных с использованием редакционного расстояния между кортежами и ключевого набора атрибутов / О. А. Райкова. — Текст : непосредственный // Технические науки: проблемы и перспективы : материалы I Междунар. науч. конф. (г. Санкт-Петербург, март 2011 г.). — Санкт-Петербург : Реноме, 2011. — С. 137-140. — URL: https://moluch.ru/conf/tech/archive/2/254/ (дата обращения: 03.04.2025).
В процессе функционирования информационных систем приходится сталкиваться с проблемами контроля качества данных. Данные в информационные системы попадают, как правило, двумя путями: непосредственный пользовательский ввод и интеграция с другими системами (при этом первоначально данные так же вносились пользователем) [1]. Присутствие «человеческого фактора» приводит к появлению ошибок в данных, что может негативно сказаться на процессе принятия решений. Ошибки в свою очередь приводят к тому, что в системе появляются так называемые нестрогие дубликаты, то есть записи, отличающиеся только наличием ошибок. Для обеспечения доступа к точным и согласованным данным необходимо исключение дублирующейся информации. Наличие разного рода ошибок приводит к тому, что точные методы поиска не дают необходимых результатов.
В данной работе рассматривается задача нестрогого сопоставления записей [2], хранящихся в реляционной базе данных. Будет введено редакционное расстояние между кортежами и рассмотрена процедура выделения набора атрибутов для сопоставления с разделением этих атрибутов на основные (первичный ключ сопоставления) и дополнительные. Так же будет рассмотрено двухэтапное сопоставление записей по двум группам атрибутов.
Большинство методов нестрогого сопоставления данных ориентировано на неструктурированный или слабоструктурированный текст. Отличительной же чертой хранения информации в реляционной базе данных является ее строгая структурированность. Это свойство заставляет адаптировать существующие алгоритмы для структурированных данных. Самым простым способом такой адаптации было бы преобразование записи таблицы в строку путем перечисления значений каждого поля через пробел. Однако увеличение длины строки приведет к росту количества вычислений, а значит и занимаемых ресурсов. Рассмотрим метод нестрогого сопоставления с учетом структурированной природы данных.
Перед выполнением процедуры сопоставления необходимо принять решение о том, какие атрибуты будут в ней участвовать. Логично предположить, что не все атрибуты отношения имеет смысл включать в сопоставление. Например, суррогатные идентификаторы записей не дадут никакой дополнительной информации, так как в каждой из сопоставляемых баз они генерируются независимо.
Пусть X и Y – реляционные отношения [3], кортежи которых необходимо сопоставить в нестрогом смысле, A = sch X = {A1, A2, …, An}, B = sch Y = {B1, B2 …, Bm} – схемы отношений. В каждой из этих схем отношений выберем подмножество атрибутов для сопоставления:
A'
= {A'1,
A'2,
…, A'r},
A'
![]() A
A
B'
= {B'1,
B'2
…, B'r},
B'
![]() B,
где
r ≤ min (m, n).
B,
где
r ≤ min (m, n).
Отметим, что схемы сопоставляемых отношений первоначально могут не совпадать (например, в одном отношении фамилия, имя и отчество физического лица представляются одним атрибутом, а в другом – тремя). Однако в данной работе вопрос сопоставления схем не рассматривается и предполагается, что части схемы сопоставлены предварительно. Это нетрудно сделать с помощью построения представлений.
В связи с выделением подмножеств атрибутов для сопоставления возможны следующие ситуации. Данных атрибутов может быть недостаточно, чтобы идентифицировать запись, то есть количество ложных срабатываний (ситуаций, когда записи, не являющиеся дубликатами, из-за недостаточной информации определяются как нестрогие дубликаты) при сопоставлении будет слишком велико. В этом случае необходимо добавить дополнительные атрибуты к выбранным. Противоположной ситуацией может оказаться избыточность выбранных атрибутов, что приведет к дополнительным вычислениям, а значит дополнительным затратам ресурсов и времени. Отметим, что вопрос оптимального выбора набора атрибутов для сопоставления остается пока открытым. Однако в общем случае для каждого отношения будем рассматривать два непересекающихся подмножества исходного множества атрибутов:
-
A'
= {A'1,
A'2,
…, A'r},
B'
= {B'1,
B'2
…, B'r}
и
- Ak' = { Ak'1, Ak'2, …, Ak'r},Bk' = { Bk'1, Bk'2, …, Bk'r},
- A', Ak'
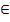 A, B',
Bk'
B,
A, B',
Bk'
B, - Ak' = { Ak'1, Ak'2, …, Ak'r},Bk' = { Bk'1, Bk'2, …, Bk'r},
где r ≤ min (m, n) и k ≤ r. Ak' и Bk' будем называть первичным ключом сопоставления. Можно так же использовать следующую запись:
- A'
= {A'1,
A'2,
…, A'k
, A'k+1
, …, A'r},
- B' = {B'1, B'2, …, B'k, B'k+1, …, B'r}.
При этом понятие первичного ключа в данном случае не аналогично соответствующему понятию реляционных баз данных. В данном случае первичный ключ идентифицирует запись с некоторой погрешностью, то есть в данном отношении могут существовать записи с таким же ключом сопоставления. Нужно выбирать ключ таким образом, чтобы количество таких записей было небольшим. Отметим, что на практике можно проводить анализ ключа сопоставления для определения того, насколько хорошо он идентифицирует запись выбранного отношения.
Поля, которые мы назвали первичным ключом, будут являться основными полями для сопоставления, а остальные – дополнительными. В соответствии с этим будем проводить сопоставление в два этапа.
На первом
этапе каждому кортежу, соответствующему схеме A'
будет
поставлено в соответствие множество кортежей схемы B'
по
первичному ключу сопоставления. Это множество может быть пустым. С
учетом того, что при сопоставлении будет использоваться нестрогое
сравнение, будем использовать для этой операции термин «нестрогое
соединение», введенный в работе [2]. Эта операция для отношений
A
и B
обозначается символом
![]() и определим
как отношение, составленное из всех пар записей отношений-аргументов,
соответствующие значения полей которых близки, то есть расстояние
между ними не превосходит заданного порогового значения:
и определим
как отношение, составленное из всех пар записей отношений-аргументов,
соответствующие значения полей которых близки, то есть расстояние
между ними не превосходит заданного порогового значения:
![]()
где
![]() – расстояние редактирования между соответствующими атрибутами
отношений, h
– пороговое значение расстояния редактирования.
– расстояние редактирования между соответствующими атрибутами
отношений, h
– пороговое значение расстояния редактирования.
Таким образом, выполнив нестрогое соединение по ключу сопоставления, получим отношение, состоящее из всех пар записей, соответствующие значения атрибутов которых близки. Получить кортежи отношения X, которым соответствует больше одного кортежа отношения Y, и наоборот, можно выполнив соответствующие группировки.
Для элементов, которым соответствует множество размерности больше единицы, проведем второй этап сопоставления по дополнительным атрибутам, уменьшив таким образом результирующее множество.
Нестрогие реляционные операции, введенные в работе [2], позволяют получить только результирующее множество. Далее предлагается способ вычислить расстояние редактирования (Левенштейна) [4] между сопоставляемыми кортежами. Численное значение расстояния редактирования позволит более точно судить о степени схожести записей и при необходимости делать выбор между несколькими потенциальными дубликатами.
Самым простым способом получения результирующего значения расстояния редактирования между кортежами можно считать учет результатов сопоставления значения каждого атрибута в равной степени. Расстояние между кортежами A и B будем обозначать D(A, B). Таким образом, расстояние редактирования между кортежами может быть вычислено по следующей формуле:
![]()
где n – количество атрибутов, участвующих в сопоставлении,
di – расстояние редактирования между значениями соответствующих атрибутов.
Покажем, что введенное расстояние между кортежами является метрикой. Докажем аксиомы метрики:
Покажем, что D(A,B) ≥ 0.
Так как d(x,y) – расстояние Левенштейна, которое является метрикой, то
 И n
> 0, следовательно, D(A,B)
≥ 0.
И n
> 0, следовательно, D(A,B)
≥ 0.
Покажем, что D(A, B) = 0 <=> A=B. Будем считать, что кортежи A и B равны, если все значения соответствующих атрибутов отношений совпадают.
Так как d(x,y) ≥ 0, для того чтобы
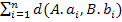 равнялась нулю, необходимо, чтобы
равнялась нулю, необходимо, чтобы
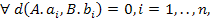 а это означает, что все
значения соответствующих атрибутов отношений совпадают, то есть
кортежи A
и B
равны.
а это означает, что все
значения соответствующих атрибутов отношений совпадают, то есть
кортежи A
и B
равны.
Покажем, что D(A, B) = D(B, A).
Так как d(x,y) = d(y,x) =>
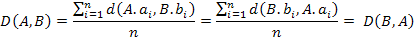
Покажем, что D(A, B) ≤ D(A, С) + D(С, B).
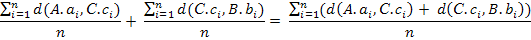
Так как d(x,y) ≤ d(x,z) + d(z,y),
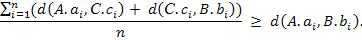
В приведенной выше формуле мы рассматриваем только факт наличия/отсутствия ошибок в словах. Однако атрибуты могут иметь разный семантический вес в отношении (важность). Например, очевидно, что в отношении, описывающем сотрудников организации и содержащем фамилию, имя, отчество и дату рождения, отчество будет иметь наименьший семантический вес. В качестве примера рассмотрим следующие записи:
|
№ |
Фамилия |
Имя |
Отчество |
Дата рождения |
|
1 |
Абакумов |
Анатолий |
Егорович |
10.10.1970 |
|
2 |
Воронов |
Анатолий |
Егорович |
10.10.1970 |
|
3 |
Абакумов |
Анатолий |
Андреевич |
10.10.1970 |
Легко вычислить, что расстояние редактирования между записями (1) и (2) равно расстоянию редактирования между записями (1) и (3), однако более вероятно, что дубликатами являются записи с одинаковой фамилией.
Чтобы учесть это, можно использовать дополнительные весовые коэффициенты для атрибутов. Похожий подход существует в методах информационного поиска [5]. Таким образом, формула приобретает следующий вид:
![]()
где сi – весовые коэффициенты.
В заключении рассмотрим вопрос о способах назначения весовых коэффициентов атрибутам отношения. На данном этапе предлагается назначение коэффициентов экспертом, однако в дальнейшем планируется рассмотреть способы расчета коэффициентов на основе информации о длине и типе данных атрибута. Полученные значения можно использовать как для непосредственного вычисления расстояния, так в качестве рекомендаций эксперту.
Таким образом, в данной работе были рассмотрены некоторые аспекты задачи сопоставления записей реляционных баз данных. Было введено понятие редакционного расстояния между реляционными кортежами и предложен способ вычисления расстояния между записями как без учета семантического веса атрибутов, так и с его использованием. Так же рассмотрена процедура сопоставления с использованием двух групп атрибутов: основных (первичный ключ сопоставления) и дополнительных, которая позволяет более гибко управлять процессом сопоставления записей.
- Литература:
Тарасов С. Управление качеством данных на основе алгоритмов нечеткого поиска // Мир ПК. 2007. №11.
Федоркова Г. О. Разработка специального математического обеспечения для отождествления записей в базах данных на основе операций нестрогого соответствия.: дис. канд. техн. наук: 05.13.11, Липецк, 2005, 158 с. РГБ ОД, 61:05-5/3233.
Дейт, К. Д. Введение в системы баз данных, 7-е издание. Пер. с англ. – М.: Вильямс, 2001.
Левенштейн. В.И. Двоичные коды с исправлением выпадений, вставок и замещений символов. Докл. АН СССР, 163, 4, стр. 845-848, 1965.
Губин М. В. Модели и методы представления текстового документа в системах информационного поиска.: дис. канд. физ.-мат. наук: 05.13.11, Санкт-Петербург, 2005, 95 с.




