




Использование имитационного моделирования для анализа производительности биллинговых систем

Авторы: Воробьев Сергей Петрович, Горобец Виталий Владимирович
Рубрика: 1. Информатика и кибернетика
Опубликовано в
II международная научная конференция «Актуальные вопросы технических наук» (Пермь, февраль 2013)
Статья просмотрена: 734 раза
Библиографическое описание:
Воробьев, С. П. Использование имитационного моделирования для анализа производительности биллинговых систем / С. П. Воробьев, В. В. Горобец. — Текст : непосредственный // Актуальные вопросы технических наук : материалы II Междунар. науч. конф. (г. Пермь, февраль 2013 г.). — Т. 0. — Пермь : Меркурий, 2013. — С. 1-5. — URL: https://moluch.ru/conf/tech/archive/73/3439/ (дата обращения: 26.04.2025).
Современные тенденции развития рынка информационных технологий, связанные с постоянно и быстро растущим многообразием видов предоставляемых услуг и их объемов, ставят перед компаниями все более сложные задачи по организации процесса предоставления услуг клиентам: предоставление максимального спектра различных услуг, создание гибкой системы учета и тарификации использованных ресурсов, выставления счетов и учета оплаты, максимальная ориентация на нужды конкретного потребителя, максимально быстрая реакция на запросы клиента, поддержка различных способов оплаты. Исходя из этого, возникает задача создания современных высокоэффективных программных комплексов, осуществляющих учет объема потребляемых абонентами услуг, расчет и списание денежных средств в соответствии с тарифами компании. Такие автоматизированные системы относятся к классу OLTP (On-Line Transaction Processing) и называются биллинговыми системами (БС).
Однако традиционно их узким местом является снижение производительности при возрастании нагрузки (увеличение количества пользователей), накоплении информации за длительный промежуток времени, а также высокая фрагментация хранимых данных, характерная для транзакционных систем. Это особенно критично для рынка OLTP-решений, которые предназначены для ввода, структурированного хранения и обработки информации в режиме реального времени. Кроме того, по той же причине в них существенно ограничены возможности выполнения таких функций, как формирование бухгалтерской и аналитической отчетности в различных разрезах и с различной глубиной детализации.
Для решения данной проблемы компании, предоставляющие услуги, вынуждены приобретать дорогостоящее оборудование, производить его настройку и постоянно пользоваться услугами высокооплачиваемых специалистов. В связи с этим в качестве базовой архитектуры при разработке биллинговых OLTP-систем предлагается использовать облачную технологию (Cloud Computing), которая позволит заменить большие капитальные затраты на реализацию такой системы операционными. В соответствии с [1], идеология данного подхода заключается в переносе вычислений, обработки и хранения данных в существенной степени с персональных компьютеров на серверы сети Интернет. Актуальной задачей в этом случае является оптимальное распределение данных в облаке. Этим можно добиться значительного сокращения расходов и повышения скорости работы системы. В настоящее время в большинстве случаев такие системы строятся без учета критериев эффективности и с большим запасом по масштабированию, поскольку технология проектирования и моделирования облачных систем еще недостаточно отработана. Исходя из этого, необходим программный комплекс, реализующий математические модели функционирования и оптимизации структуры облачной системы, который позволит производить имитационное моделирование с целью получения интегральных показателей эффективности ее работы.
В связи с этим в данной работе рассматривается модель архитектуры БС, предполагающей размещение фрагментов распределенной базы данных (РБД) в облаке, а также предлагается программный комплекс для оценки производительности такой системы.
Архитектура сети (рис. 1) описана в работе [2] и включает сеть с произвольной топологией (облако), соединяющую узлы (серверы), и локальные вычислительные сети (ЛВС) с регулярной структурой (сеть компании, сети удаленных филиалов), все рабочие станции которых имеют доступ в сеть с произвольной топологией. Кроме того, в архитектуру сети могут входить персональные компьютеры и мобильные устройства (ноутбуки, планшетные компьютеры и смартфоны) удаленных пользователей БС.
В состав сети произвольной топологии входят узлы хранения (непосредственно серверы, хранящие фрагменты баз данных), серверы управления доставкой контента, серверы метаданных, коммутаторы.
Серверы метаданных (СМ) содержат базы данных (БД) о местоположении фрагментов и другие параметры.
Серверы управления доставкой контента (СУД) выполняют работу по взаимодействию пользователя с распределенной системой и предназначены для последовательного выполнения следующих задач:
прием запросов от пользователей;
выбор узлов, которые будут обрабатывать запрос пользователя;
перенаправление запроса на выбранные узлы;
прием ответов от узлов на пользовательский запрос;
составление результирующего набора данных;
перенаправление ответа сервера на запрос пользователю.
Узлы хранения, содержащие сами фрагменты, могут быть совершенно разными гетерогенными системами, что является принципиальным отличием предлагаемой архитектуры от известных решений.
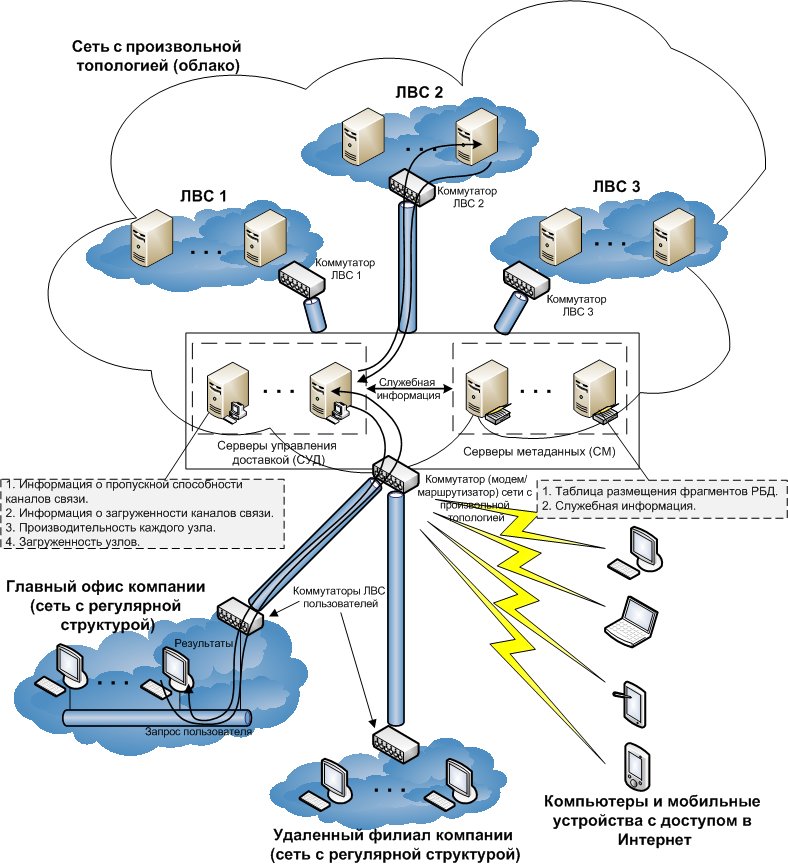
Рис. 1. Сетевая структура
Концептуальная модель рассматриваемой информационной системы представляет разомкнутую сеть массового обслуживания, содержащую:
приборы, моделирующие работу канала, коммутаторов и узлов;
буферную память каждого коммутатора, предназначенную для хранения транзакций пользователей;
буферную память каждого узла.
Описанную модель распределенной системы можно представить в виде системы массового обслуживания (рис. 2).

Рис. 2. Концептуальная модель системы массового обслуживания
Для оценки эффективности работы биллинговой системы в ЮРГТУ (НПИ) разработан программный комплекс, реализующий математические модели функционирования и оптимизации структуры облачной системы. Для определения интегральных характеристик, таких как время реакции на запросы каждого пользователя и время реакции системы, используются соотношения, указанные в работе [2]. Результатом работы программного комплекса является оптимальное размещение информационных ресурсов различного типа на узлах облака с использованием алгоритмов генетического программирования, определение рационального числа реплик данных с целью обеспечения высокой эффективности и надежности. Кроме того, предлагаемый комплекс позволяет производить имитационное моделирование для получения и последующего анализа таких характеристик системы, как загрузка каждого узла, среднее время обработки запроса узлом, количество обращений к узлу, квадрат коэффициента вариации времени задержки и др.
Данная программа для проведения экспериментов использует библиотеки системы имитационного моделирования Pilgrim. Однако необходимо отметить, что в разработанном продукте (в отличие от конструктора моделей GEM 1.0) очереди, обслуживающие приборы и управляемые терминаторы транзактов (демультипликаторы) создаются динамически с учетом настроек пользователя. Это дает гибкость проектирования и конфигурирования структуры БС, а также предоставляет возможность проведения эксперимента «что, если». Предложенный программный комплекс позволяет, например, определить, сколько требуется узлов сети произвольной структуры, чтобы в течение заданного промежутка времени не происходило задержек в обработке запросов, но в то же время не было значительного простоя узлов. Во время работы модели автоматически строится график задержек в выбранном узле. Поскольку для БС крайне важно обеспечить высокую доступность (небольшое время отклика системы), то при анализе результатов имитационного моделирования необходимо обратить особое внимание на состояние очередей и загрузку обслуживающих приборов. Эти параметры во многом определяют производительность всей системы. Для рассматриваемой архитектуры БС одними из важнейших узлов являются СУД и СМ, т. к. они первоначально обрабатывают пользовательские запросы и периодически поступающую служебную информацию. Показателем стабильности работы этих узлов может служить состояние очередей к ним (пример представлен на рис. 3).
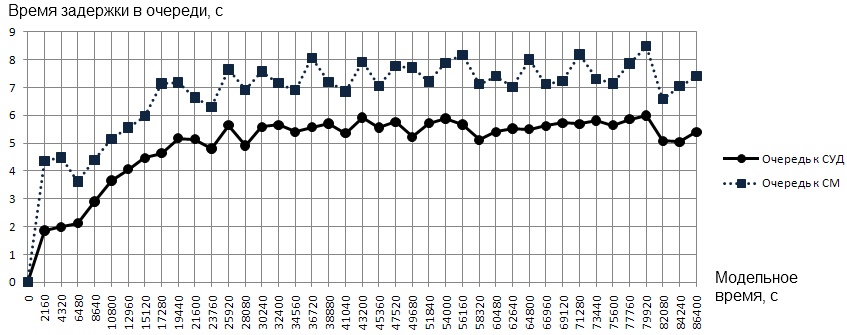
Рис. 3. Графики задержек в узлах
Приведенные графики показывают, что время задержки в очередях к СУД и СМ с течением модельного времени стабилизируется, следовательно, увеличения времени отклика системы из-за перегрузки СУД или СМ не будет. После окончания процесса моделирования автоматически формируется файл, который содержит указанные выше характеристики системы, часть из которых представлена в табл. 1:
Таблица 1
Результаты моделирования
|
№ узла |
Наименование узла |
Тип узла |
Загрузка (%=) |
M [t] среднее время |
C2 [t] кв. коэф. вар. |
Счетчик входов и hold |
Кол-во каналов |
Оставшиеся транзакты |
|
101 |
Очередь к СУД |
queue |
- |
5,05 |
1,65 |
79332 |
1 |
0 |
|
109 |
Обслуженные |
term |
- |
100,43 |
0,73 |
72984 |
0 |
1 |
|
112 |
Все запросы |
creat |
- |
0,00 |
1,00 |
73000 |
1 |
0 |
|
114 |
СУД |
serv |
28,4 |
1,00 |
0,24 |
256581 |
10 |
0 |
|
115 |
Очередь ЛВС 1 |
queue |
- |
0,46 |
1,12 |
71220 |
1 |
0 |
|
116 |
ЛВС 1 |
serv |
32,8 |
3,99 |
0,08 |
71220 |
10 |
0 |
|
120 |
Очередь к СМ |
queue |
- |
7,09 |
1,17 |
75493 |
1 |
0 |
|
121 |
СМ |
serv |
33,8 |
2,01 |
0,24 |
75493 |
5 |
0 |
|
130 |
Очередь ЛВС 2 |
queue |
- |
6,20 |
4,34 |
6548 |
1 |
0 |
|
131 |
ЛВС 2 |
serv |
28,7 |
9,1 |
6,01 |
6548 |
5 |
0 |
|
132 |
Очередь ЛВС 3 |
queue |
- |
6,94 |
1,03 |
1564 |
1 |
0 |
|
133 |
ЛВС 3 |
serv |
25,2 |
4,8 |
7,96 |
1564 |
3 |
0 |
|
201 |
Оч. польз. 0 |
queue |
- |
7,36 |
1,65 |
2715 |
1 |
0 |
|
301 |
Польз. 0 |
serv |
62,7 |
19,94 |
0,06 |
2715 |
1 |
0 |
Анализ приведенных результатов показывает, что за период моделирования, равный 1 суткам (86400 секунд), в систему поступило 73000 запросов. В среднем пользователи потратили на обдумывание запросов около 60 % времени работы с ЛВС. Среднее время ожидания запроса и ответа в очереди пользователя составило 7 с, а среднее время пребывания в узле приблизительно равно 20 с. Из поступивших 73000 запросов были обработаны 72984 запроса, остальные находятся в очередях к серверам и узлам. Такая ситуация обусловлена запасом вычислительных мощностей серверов управления доставкой, т. к. коэффициент нагрузки СУД составляет 28,4 %, причем в очереди запросов не находится.
Загрузка серверов метаданных составила 33,8 %, что говорит о существенном запасе вычислительной мощности. Загрузка узлов подсетей облачной структуры колеблется от 25 % до 33 %, что свидетельствует о большом запасе вычислительной мощности узлов.
При анализе состояния очередей особое внимание следует обратить на значение квадрата коэффициента вариации времени задержки. Если оно близко к нулю, время задержки не имело существенного разброса, то есть длина очереди была практически постоянной. Если же значение квадрата коэффициента вариации велико, то это значит, что транзакты приходили в очередь группами. В данном случае квадрат коэффициента вариации не слишком большой, поэтому можно сделать вывод о том, что время задержек в очередях было приблизительно постоянным.
Следовательно, для рассмотренного примера модели БС узлов облака достаточно, чтобы в течение заданного промежутка времени не происходило задержек в обработке запросов пользователей, однако наблюдается невысокая загрузка серверов и узлов облака, что указывает на низкую эффективность функционирования системы. Это подтверждает тот факт, что рассмотренную БС целесообразно реализовать на базе облачной технологии и использовать преимущества ее концепции «платы по мере использования».
- Таким образом, разработанный в ЮРГТУ (НПИ) программный комплекс может быть использован для проведения имитационного моделирования с целью анализа производительности биллинговых систем, построенных на базе облачной архитектуры.
Литература:
- Gartner. Gartner Top Ten Disruptive Technologies for 2008 to 2012. Emerging Trends and Technologies Roadshow, 2008.
- Воробьев С. П., Горобец В. В. Исследование модели транзакционной системы с репликацией фрагментов базы данных, построенной по принципам облачной среды // Инженерный вестник Дона: электрон. журн. 2012. № 4. URL: http://www.ivdon.ru/magazine/archive/n4t1y2012/1149 (дата обращения: 19.10.2012).