




Адаптивный поиск информации в Internet

Автор: Зуева Виктория Николаевна
Рубрика: 1. Информатика и кибернетика
Опубликовано в
II международная научная конференция «Современные тенденции технических наук» (Уфа, май 2013)
Статья просмотрена: 264 раза
Библиографическое описание:
Зуева, В. Н. Адаптивный поиск информации в Internet / В. Н. Зуева. — Текст : непосредственный // Современные тенденции технических наук : материалы II Междунар. науч. конф. (г. Уфа, май 2013 г.). — Т. 0. — Уфа : Лето, 2013. — С. 7-10. — URL: https://moluch.ru/conf/tech/archive/74/3682/ (дата обращения: 19.04.2025).
Извлечение знаний можно определить как нахождение и анализ полезной информации. Данную область деятельности принято подразделять на две части. Первая — автоматический поиск информации в документах Сети — Web content mining. Вторая — обнаружение и обработка информации, касающейся работы пользователей с сервером, — Web usage mining. В рамках данной статьи нас будет интересовать вторая часть, использующая результаты первой.
Модуль добычи данных в Internet, назовем его WebMiner, в свою очередь делится на три подсистемы:
- составление дайджеста по заданным темам с заданных сайтов;
- поиск интересующей информации через поисковые системы;
- загрузка данных.
Рассмотрим подсистему составление дайджеста по заданным темам.
Целевая функция: «Страница подготовленного дайджеста по определенной тематике (эти и только эти новые данные должны быть нужны пользователю по указанной тематике)»
Основные положения:
- страница должна быть доступна к просмотру пользователем в любом браузере;
- приложение должно запускаться параллельно браузеру;
- приложение должно отслеживать страницы на Web, посещаемые пользователем, сохранять статистику и на базе этой статистики создавать дайджест;
- в дайджест должны попадать только новые материалы, появившиеся на самых часто посещаемых сайтах;
- дайджесты должны строиться в разрезе тематики — свой дайджест на каждую тематику;
- архитектура — HTTP Proxy, работающая на клиенте;
- система интеллектуального поиска информации в сети Internet должна быть адаптивна под конкретного пользователя.
В БД WebMiner используются:
- база знаний для данного пользователя (БЗП);
- база сайтов пользователя (БС).
Формат БЗП:
- слово;
- ранг слова (частота встречаемости);
- номер слова;
- ссылки на N номеров слов, наиболее встречающимися в сочетании с данным словом (с частотой смежности)
- страна пользователя.
Формат БС:
- название сайта;
- общее количество посещений за последнюю неделю;
- общее количество посещений за все время;
- количество посещений за последнюю неделю инициированных WebMiner;
- количество посещений за все время инициированных WebMiner;
- дата первого посещения;
- дата последнего посещения;
K наиболее посещаемых страниц на данном сайте (с датами последних посещений) — общее;
K наиболее посещаемых страниц на данном сайте (с датами последних посещений) — инициированное WebMiner.
Формулы расчета:
Примечание 1: слова размерностью меньше 2 символов учитываются, только в том случае, если они написаны заглавными буквами. Слова размерностью больше 2 символов учитываются, если они не попадают в список запрещенных слов. Например, для русскоязычных текстов, список запрещенных слов:
1. для
2. потому
3. что
и т. д.
Примечание 2: также необходимо добавить в этот список все зарезервированные слова языков программирования HTML, PHP и т. д.
Частота встречаемости:
![]() , (1)
, (1)
где ![]() - частота встречаемости данного слова;
- частота встречаемости данного слова;
![]() — количество повторений данного слова в тексте;
— количество повторений данного слова в тексте;
![]() — количество слов в тексте размерностью больше 2 символов и без запрещенных слов.
— количество слов в тексте размерностью больше 2 символов и без запрещенных слов.
Частота взаимовстречаемости слова с данным словом:
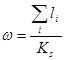 , (2)
, (2)
где ![]() — частота взаимовстречаемости,
— частота взаимовстречаемости,
![]() — количество повторений взаимовстречаемого слова с заданным в тексте с длиной позиционирования не больше двух слов. Причем если слова разделяет точка, то взаимостречаемое слово не учитывается;
— количество повторений взаимовстречаемого слова с заданным в тексте с длиной позиционирования не больше двух слов. Причем если слова разделяет точка, то взаимостречаемое слово не учитывается;
![]() — коэффициент удаленности взаимовстречаемого слова от заданного (количество слов от).
— коэффициент удаленности взаимовстречаемого слова от заданного (количество слов от).
Для примера текст: «Для прогнозирования спроса используются нейросети».
Заданное слово: нейросеть, тогда в ![]() попадает слово из текста спрос. При этом должно учитываться, что глаголы и предлоги не попадают в анализ.
попадает слово из текста спрос. При этом должно учитываться, что глаголы и предлоги не попадают в анализ.
Примечание: очевидно, что частота взаимовстречаемости в одном тексте взаимовстречаемого слова и заданного слова равна обратной комбинации поиска взаимовстречаемости этих слов. Например ![]() .
.
В случае если пользователь делает запрос на поисковой системе, то слова в тексте запроса добавляются с частотами равными единице. При этом страница, выданная поисковой машиной, не учитывается.
Алгоритм работы WebMiner состоит из следующих шагов:
При первом запуске инициируются БЗП и БС.
При последующих запусках алгоритм следующий:
1. В случае захода пользователя на любой сайт происходит сканирование и вычисление частот встречаемости и частот взаимовстречаемости слов. Обновление итоговой частоты слова происходит по формуле:
![]() , (3)
, (3)
где ![]() - количество текстов, где встречалось заданное слово.
- количество текстов, где встречалось заданное слово.
Итоговая частота взаимовстречаемости считается аналогично. Второй вариант — можно еще использовать коэффициент старения посещения страницы.
2. Происходит обновление БС.
3. С заданной периодичностью WebMiner посещает наиболее встречаемые сайты и ищет в заголовках (или в зависимости от настроек по всей странице) статей слова с наибольшим рангом. В случае нахождения заголовка (или непосредственно на странице) ранжируемого слова, пользователю посылается сообщение о новостях и в случае если пользователь зайдет по ссылке WebMiner на предлагаемую страницу обновляется количество наиболее посещаемых страниц (а также страниц инициированных WebMiner).
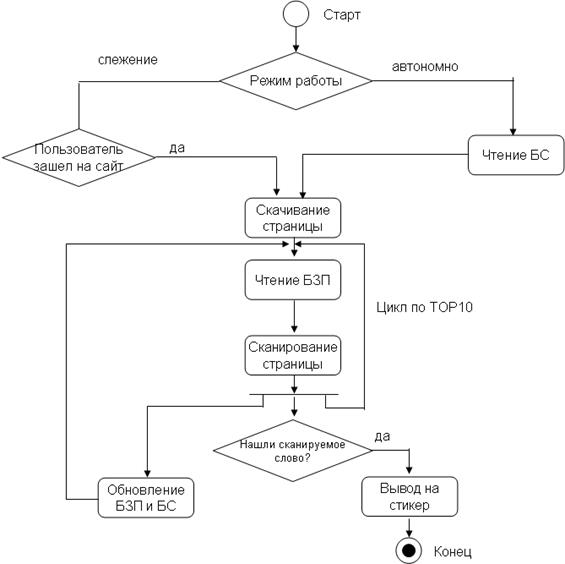
Рис. 1. Алгоритм работы WebMiner
В системе можно использовать ранги по тематикам: юмор, спорт, новости, бизнес и т. д. Также можно периодически делать запрос на поисковые системы со списком наиболее встречаемых слов. Можно использовать перекрестные ссылки на другие страницы с данного сайта.
Все страницы просмотренные пользователем за период R (R ~ неделя) должны храниться в папке программы (без картинок) с названием «URL страницы» без http://. В данном случае имеет смысл вести простую базу (файл DBF) с полями:
- имя страницы;
- ссылка на название сохраненного файла этой страницы (равна «имя страницы» без «http://»);
- количество слов, размером больше 2 двух символов.
В случае захода на любую страницу идет поиск по данной базе — если есть эта же страница, то идет сверка по количеству слов размером больше двух символов.
Примечание 3: страницы можно не сохранять, обойтись только контрольной суммой.
Интерес пользователя к информации может быть долговременным и кратковременным.
Долговременным интересом пользователя будет называть, такой интерес, который не проходит в течение периода N (N первоначально равен неделе). Как пример можно привести, допустим, футбол, анекдоты и т. п.
Краткосрочным интересом пользователя будем называть, такой интерес, который продолжается не более периода K (К первоначально равен неделе). Как пример, можно привести, допустим, политический вопрос, например «революция в Киргизии».
При этом частоты по формулам (1) и (2) должны считаться как на неделю, так и за весь период. Варианты работы системы:
Вариант 1. Вариант сканирования только заголовков (ищем в тексте только то, что заключено в кавычках после href=:
Пример
<TITLE>Главные новости дня: политика, экономика, происшествия</TITLE>
<link rel=«stylesheet» href=«http://top.rbc.ru/topnews.css» type=«text/css»>
То есть, в данном случае есть ссылка «http://top.rbc.ru/topnews.css».
Слова для БЗС берутся между <TITLE> и </TITLE>
Вариант 2. Режим слежения за пользователем
1. Отслеживается, что пользователь зашел на сайт xxx;
2. Отслеживается ссылка, на которую перешел пользователь;
3. Обновляются БЗП и БС. Причем в БС добавляются как корень страницы, так и конечная страница. Обновляется БЗС по словам[1];
4. и так далее по всем заходам пользователя.
Вариант 3. Режим автономной работы.
1. По таймеру делается обход наиболее посещаемых страниц пользователя (TOP10), то есть скрыто загружаются эти страницы;
2. Выбираются наиболее встречаемые слова пользователя из БЗП;
3. На каждой загруженной странице ищутся в заголовках и кратких аннотациях (то есть между двумя link) наиболее встречаемые слова;
4. В случае нахождения нужного слова (слов), эта ссылка попадает в дайджест;
5. После сканирования всех страниц пользователю выдается дайджест;
6. В случае перехода по ссылке дайджеста, включается «режим слежения за пользователем».
Рассмотрим подсистему поиска через поисковые системы. В качестве поисковой системы используется связка двух лидеров в данном сегменте: Google (мировой лидер) и Yandex (российский лидер). Следует также отметить, что Google индексирует и российские сайты. Запрос обрабатывается скриптом, написанном на ЯП Perl.
Рассмотрим подсистему блока загрузки данных. Данный блок является самым простым по реализации. Алгоритм (автоматический):
1. Срабатывает таймер;
2. Открытие заданной станицы в Internet;
3. Парсировка страницы на наличие ссылки на заданный файл (формат xls) (учитываем, шаблон названия);
4. Скачивание файла;
5. Открытие файла (hidden);
6. По заданному шаблону выкачиваем данные в БД.
Таким образом, мы получаем простую систему помощника, позволяющую находить интересующую информацию в сети Internet в автоматическом режиме.
Литература:
1. Д. Ландэ «Поиск знаний в Internet» — М, Диалектика, 2005 г.
2. Christopher D. Manning, Hinrich Schutze. Foundations of Statistical Natural Language Processing.
3. Ethem Alpaydin. Introduction to Machine Learning (Adaptive Computation and Machine Learning).




