




Оптимизация размещения данных по узлам информационно-вычислительной сети

Авторы: Зинкин Сергей Александрович, Белецкий Павел Андреевич
Рубрика: 3. Автоматика и вычислительная техника
Опубликовано в
II международная научная конференция «Современные тенденции технических наук» (Уфа, май 2013)
Статья просмотрена: 566 раз
Библиографическое описание:
Зинкин, С. А. Оптимизация размещения данных по узлам информационно-вычислительной сети / С. А. Зинкин, П. А. Белецкий. — Текст : непосредственный // Современные тенденции технических наук : материалы II Междунар. науч. конф. (г. Уфа, май 2013 г.). — Т. 0. — Уфа : Лето, 2013. — С. 29-31. — URL: https://moluch.ru/conf/tech/archive/74/3863/ (дата обращения: 18.04.2025).
В статье представлен метод для оптимизации размещения данных по узлам информационно-вычислительной сети.
Ключевые слова:оптимизация, данные, информационно-вычислительные сети.
Одним из приоритетных и необходимых направлений развития информационных технологий является географически распределенная обработка информации в информационно-вычислительной сети. Это вызвано необходимостью интеграции информационных ресурсов, находящихся в разных географических локациях. Важной задачей проектирования таких сетей становится размещение файлов по узлам сети.
Для достижения поставленных задач повсеместно используют распределенные базы данных. Оптимальное размещение баз данных и файлов в узлах распределенных систем с учетом приведенных затрат на размещение и обслуживание позволит получить значительный экономический эффект при создании и эксплуатации больших кластерных систем.
С начала построения информационно-вычислительных систем для работы с базами данных они имели централизованную структуру. Необходимая информация хранилась на одном сервере. Достоинством использования такой организации является облегчение задачи обеспечения безопасности и целостность файлов и таблиц.
Но при использовании сетей, работающих с централизованной организацией, с увеличением объема хранимых данных и прибавлением все новых клиентов, обращающихся к ней, а также с распределенным территориальным размещением кластерных систем, возникает потребность в распределенной обработке информации, выявляются значительные недостатки, присущие централизованной организации. В результате возрастает объем обмена информацией, происходит снижение надежности процесса обмена файлами, уменьшение общей производительности, и в значительной степени увеличивается объем средств, необходимых на организацию и эксплуатацию баз данных.
Выходом из сложившейся ситуации является построение распределенной базы данных. При таком способе организации сети появляются возможности увеличения параметра эффективности обработки файлов, снижение затрат при эксплуатации, упрощение процесса управления информационно-вычислительной системой. В распределенной базе данных файлы хранятся на нескольких узлах. Обработка информации и передача между различными узлами осуществляется в результате выполнения запросов. Процесс распределения файлов по узлам может осуществляться посредством размещения таблиц по разным узлам или распределения различных составляющих одной таблицы по узлам.
Оптимальный выбор количества файлов и их размещение в узлах сети может значительно увеличить эффективность сети. Поэтому первоочередной задачей становится наилучшее распределение файлов по узлам. Из-за большой размерности очень трудно получить точное решение. По решению этой проблемы неоднократно проводились исследования [1–3].
В данной статье предлагается алгоритм оптимального размещения файлов. Критерием является суммарный объем запросов. Файлы хранятся в базах так, что имеется только единственная копия файла.
Введем обозначения: ![]() - множество узлов информационной сети.
- множество узлов информационной сети. ![]() - множество файлов.
- множество файлов. ![]() - файл
- файл ![]() .
. ![]() - узел
- узел ![]() .
. ![]() - объем памяти узла
- объем памяти узла ![]() .
. ![]() - объем файла
- объем файла![]() .
. ![]() - интенсивность запросов узла
- интенсивность запросов узла ![]() к файлу
к файлу![]() .
. ![]() - объем запроса к файлу
- объем запроса к файлу ![]() .
. ![]() - затраты на хранение файла
- затраты на хранение файла ![]() на узле
на узле ![]() .
. 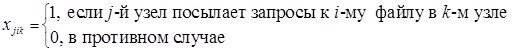
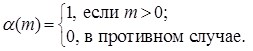
где ![]() - числовой аргумент функции
- числовой аргумент функции ![]() .
.
Необходимые для правильного выполнения ограничения функции перечислены ниже:
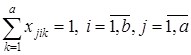 (1);
(1); ![]() (2), где
(2), где 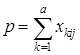 .
.
![]() (3).
(3).
Функция размещения, определяющая наименьшую стоимость хранения файлов, будет иметь следующий вид:
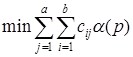 (4)
(4)
В данной статье для решения поставленной задачи предлагается использование разработанного алгоритма:
1) Для каждой пары ![]() вычисляем значения величины
вычисляем значения величины ![]() .
.
2) Распределяем значения ![]() по убыванию.
по убыванию.
3) Очередному ![]() определить номер файла
определить номер файла ![]() и номер узла
и номер узла ![]() . Если файл
. Если файл ![]() пока не размещен в
пока не размещен в ![]() узле, проверить выполнимость ограничений (1)-(3). Если поставленные ограничения выполняются — происходит размещение файла.
узле, проверить выполнимость ограничений (1)-(3). Если поставленные ограничения выполняются — происходит размещение файла.
4) Если файлы размещены в сети, вычисляем значения функции (4).
Компьютерные системы развиваются со стремительной скоростью. Но даже такое стремительное развитие зачастую не способно удовлетворить требованиям инженеров. В большинстве случаев для вычислений необходим по меньшей мере кластер персональных машин. В итоге выполнение инженерных целей может стать очень труднодостижимой задачей, а в отдельных случаях невыполнимой. В случае выполнения задачи, когда получается использовать множество компьютеров, серверов, кластеров, баз данных, размещенных по всему миру, можно добиться решения проблемы.
Литература:
1. Захаров Г. П. Методы исследования сетей передачи данных. — М: Радио и связь. — 1982. — 208с.
2. Мартин Дж. Вычислительные сети и распределенная обработка данных: программное обеспечение, методы и архитектура.. — М.: Финансы и статистика. — 1979. — 256с.
3. Шастова Г. А., Коекин А. И. Выбор и оптимизация структуры информационных систем. — М.: Энергия. — 1972. — 256с.




